Nejlepší Spring Data JpaRepository
Úvod
V tomto článku vám ukážu nejlepší způsob, jak používat Spring Data JpaRepository, které se nejčastěji používá nesprávným způsobem.
Největší problém s výchozími daty Spring JpaRepository je skutečnost, že rozšiřuje obecný CrudRepository , která ve skutečnosti není kompatibilní se specifikací JPA.
Paradox metody ukládání JpaRepository
Nic takového jako save neexistuje metoda v JPA, protože JPA implementuje paradigma ORM, nikoli vzor Active Record.
JPA je v podstatě stroj stavu entity, jak ukazuje následující diagram:
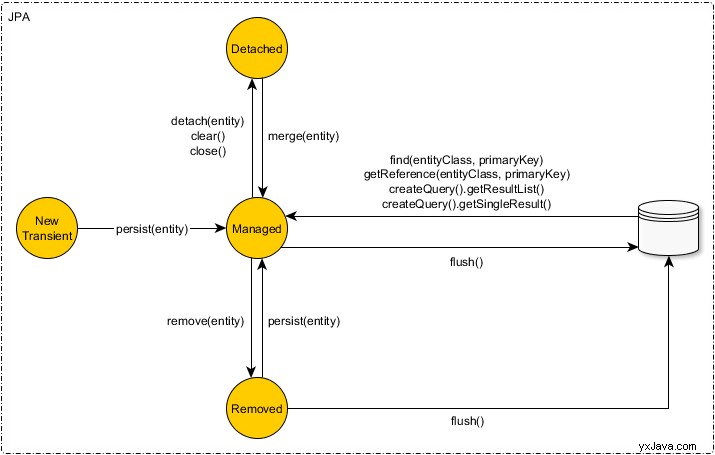
Jak jasně vidíte, žádné save neexistuje metoda v JPA.
Nyní byl Hibernate vytvořen před JPA, takže kromě implementace specifikace JPA poskytuje také své vlastní specifické metody, jako je update jeden.
I když existují dvě metody zvané save a saveOrUpdate v režimu spánku Session , jak jsem vysvětlil v tomto článku, jsou pouze aliasem pro update .
Ve skutečnosti, počínaje Hibernate 6, save a saveOrUpdate metody jsou nyní zastaralé a budou odstraněny v budoucí verzi, protože jde pouze o chybu, která byla unesena z Hibernate 1.
Pokud vytvoříte novou entitu, musíte zavolat persist takže se entita stane spravovanou a flush vygeneruje INSERT prohlášení.
Pokud se entita oddělí a vy jste ji změnili, musíte změny přenést zpět do databáze, v takovém případě můžete použít buď merge nebo update . První metoda, merge , zkopíruje stav oddělené entity do nové entity, která byla načtena aktuálním kontextem perzistence, a nechá flush zjistit, zda UPDATE je dokonce nutné. Druhá metoda, update , vynutí flush pro spuštění UPDATE s aktuálním stavem entity.
remove metoda naplánuje odstranění a flush spustí DELETE prohlášení.
Ale JpaRepository zdědí save metoda z CrudRepository , stejně jako MongoRepository nebo SimpleJdbcRepository .
Nicméně MongoRepository a SimpleJdbcRepository zaujmout přístup aktivního záznamu, zatímco JPA ne.
Ve skutečnosti save metoda JpaRepository je implementován takto:
@Transactional
public <S extends T> S save(S entity) {
if (this.entityInformation.isNew(entity)) {
this.em.persist(entity);
return entity;
} else {
return this.em.merge(entity);
}
}
V zákulisí není žádná magie. Je to buď volání na persist nebo merge ve skutečnosti.
Anti-pattern metody ukládání
Protože JpaRepository obsahuje save Naprostá většina vývojářů softwaru s ní tak zachází a nakonec narazíte na následující anti-vzor:
@Transactional
public void saveAntiPattern(Long postId, String postTitle) {
Post post = postRepository.findById(postId).orElseThrow();
post.setTitle(postTitle);
postRepository.save(post);
}
Jak moc je to známé? Kolikrát jste viděli tento „vzor“ používat?
Problém je v save linka, která je sice zbytečná, ale není bezplatná. Volání merge na spravované entitě vypálí cykly CPU spuštěním MergeEvent , který může být kaskádován dále v hierarchii entit, aby skončil v bloku kódu, který dělá toto:
protected void entityIsPersistent(MergeEvent event, Map copyCache) {
LOG.trace( "Ignoring persistent instance" );
final Object entity = event.getEntity();
final EventSource source = event.getSession();
final EntityPersister persister = source.getEntityPersister(
event.getEntityName(),
entity
);
//before cascade!
( (MergeContext) copyCache ).put( entity, entity, true );
cascadeOnMerge( source, persister, entity, copyCache );
copyValues( persister, entity, entity, source, copyCache );
event.setResult( entity );
}
Nejen, že merge hovor nepřináší nic užitečného, ale ve skutečnosti zvyšuje režii navíc k vaší době odezvy a dělá poskytovatele cloudu s každým takovým hovorem bohatším.
A to není vše. Jak jsem vysvětlil v tomto článku, obecný save metoda není vždy schopna určit, zda je entita nová. Pokud má například entita přiřazený identifikátor, Spring Data JPA zavolá merge místo persist , čímž se spustí zbytečné SELECT dotaz. Pokud se to stane v kontextu úlohy dávkového zpracování, pak je to ještě horší, můžete vygenerovat spoustu zbytečných SELECT dotazy.
Takže to nedělejte! Můžete to udělat mnohem lépe.
Nejlepší alternativa Spring Data JpaRepository
Pokud save metoda existuje, lidé ji zneužijí. To je důvod, proč je nejlepší ji vůbec nemít a poskytnout vývojáři lepší alternativy vhodné pro JPA.
Následující řešení používá vlastní idiom Spring Data JPA Repository.
Začneme tedy vlastním HibernateRepository rozhraní, které definuje nový kontrakt pro šíření změn stavu entity:
public interface HibernateRepository<T> {
//Save methods will trigger an UnsupportedOperationException
@Deprecated
<S extends T> S save(S entity);
@Deprecated
<S extends T> List<S> saveAll(Iterable<S> entities);
@Deprecated
<S extends T> S saveAndFlush(S entity);
@Deprecated
<S extends T> List<S> saveAllAndFlush(Iterable<S> entities);
//Persist methods are meant to save newly created entities
<S extends T> S persist(S entity);
<S extends T> S persistAndFlush(S entity);
<S extends T> List<S> persistAll(Iterable<S> entities);
<S extends T> List<S> peristAllAndFlush(Iterable<S> entities);
//Merge methods are meant to propagate detached entity state changes
//if they are really needed
<S extends T> S merge(S entity);
<S extends T> S mergeAndFlush(S entity);
<S extends T> List<S> mergeAll(Iterable<S> entities);
<S extends T> List<S> mergeAllAndFlush(Iterable<S> entities);
//Update methods are meant to force the detached entity state changes
<S extends T> S update(S entity);
<S extends T> S updateAndFlush(S entity);
<S extends T> List<S> updateAll(Iterable<S> entities);
<S extends T> List<S> updateAllAndFlush(Iterable<S> entities);
}
Metody v HibernateRepository rozhraní jsou implementovány pomocí HibernateRepositoryImpl třídy takto:
public class HibernateRepositoryImpl<T> implements HibernateRepository<T> {
@PersistenceContext
private EntityManager entityManager;
public <S extends T> S save(S entity) {
return unsupported();
}
public <S extends T> List<S> saveAll(Iterable<S> entities) {
return unsupported();
}
public <S extends T> S saveAndFlush(S entity) {
return unsupported();
}
public <S extends T> List<S> saveAllAndFlush(Iterable<S> entities) {
return unsupported();
}
public <S extends T> S persist(S entity) {
entityManager.persist(entity);
return entity;
}
public <S extends T> S persistAndFlush(S entity) {
persist(entity);
entityManager.flush();
return entity;
}
public <S extends T> List<S> persistAll(Iterable<S> entities) {
List<S> result = new ArrayList<>();
for(S entity : entities) {
result.add(persist(entity));
}
return result;
}
public <S extends T> List<S> peristAllAndFlush(Iterable<S> entities) {
return executeBatch(() -> {
List<S> result = new ArrayList<>();
for(S entity : entities) {
result.add(persist(entity));
}
entityManager.flush();
return result;
});
}
public <S extends T> S merge(S entity) {
return entityManager.merge(entity);
}
public <S extends T> S mergeAndFlush(S entity) {
S result = merge(entity);
entityManager.flush();
return result;
}
public <S extends T> List<S> mergeAll(Iterable<S> entities) {
List<S> result = new ArrayList<>();
for(S entity : entities) {
result.add(merge(entity));
}
return result;
}
public <S extends T> List<S> mergeAllAndFlush(Iterable<S> entities) {
return executeBatch(() -> {
List<S> result = new ArrayList<>();
for(S entity : entities) {
result.add(merge(entity));
}
entityManager.flush();
return result;
});
}
public <S extends T> S update(S entity) {
session().update(entity);
return entity;
}
public <S extends T> S updateAndFlush(S entity) {
update(entity);
entityManager.flush();
return entity;
}
public <S extends T> List<S> updateAll(Iterable<S> entities) {
List<S> result = new ArrayList<>();
for(S entity : entities) {
result.add(update(entity));
}
return result;
}
public <S extends T> List<S> updateAllAndFlush(Iterable<S> entities) {
return executeBatch(() -> {
List<S> result = new ArrayList<>();
for(S entity : entities) {
result.add(update(entity));
}
entityManager.flush();
return result;
});
}
protected Integer getBatchSize(Session session) {
SessionFactoryImplementor sessionFactory = session
.getSessionFactory()
.unwrap(SessionFactoryImplementor.class);
final JdbcServices jdbcServices = sessionFactory
.getServiceRegistry()
.getService(JdbcServices.class);
if(!jdbcServices.getExtractedMetaDataSupport().supportsBatchUpdates()) {
return Integer.MIN_VALUE;
}
return session
.unwrap(AbstractSharedSessionContract.class)
.getConfiguredJdbcBatchSize();
}
protected <R> R executeBatch(Supplier<R> callback) {
Session session = session();
Integer jdbcBatchSize = getBatchSize(session);
Integer originalSessionBatchSize = session.getJdbcBatchSize();
try {
if (jdbcBatchSize == null) {
session.setJdbcBatchSize(10);
}
return callback.get();
} finally {
session.setJdbcBatchSize(originalSessionBatchSize);
}
}
protected Session session() {
return entityManager.unwrap(Session.class);
}
protected <S extends T> S unsupported() {
throw new UnsupportedOperationException(
"There's no such thing as a save method in JPA, so don't use this hack!"
);
}
}
Nejprve všechny save metody spouštějí UnsupportedOperationException , což vás nutí vyhodnotit, který přechod stavu entity máte místo toho zavolat.
Na rozdíl od figuríny saveAllAndFlush , persistAllAndFlush , mergeAllAndFlush a updateAllAndFlush můžete těžit z mechanismu automatického dávkování, i když jste jej dříve zapomněli nakonfigurovat, jak je vysvětleno v tomto článku.
Doba testování
Chcete-li použít HibernateRepository , vše, co musíte udělat, je rozšířit ji vedle standardního JpaRepository , takto:
@Repository
public interface PostRepository
extends JpaRepository<Post, Long>, HibernateRepository<Post> {
}
To je ono!
Tentokrát neexistuje způsob, jak byste mohli narazit na nechvalně známý save volat anti-vzor:
try {
transactionTemplate.execute(
(TransactionCallback<Void>) transactionStatus -> {
postRepository.save(
new Post()
.setId(1L)
.setTitle("High-Performance Java Persistence")
.setSlug("high-performance-java-persistence")
);
return null;
});
fail("Should throw UnsupportedOperationException!");
} catch (UnsupportedOperationException expected) {
LOGGER.warn("You shouldn't call the JpaRepository save method!");
}
Místo toho můžete použít persist , merge nebo update metoda. Takže, pokud chci zachovat nějaké nové entity, mohu to udělat takto:
postRepository.persist(
new Post()
.setId(1L)
.setTitle("High-Performance Java Persistence")
.setSlug("high-performance-java-persistence")
);
postRepository.persistAndFlush(
new Post()
.setId(2L)
.setTitle("Hypersistence Optimizer")
.setSlug("hypersistence-optimizer")
);
postRepository.peristAllAndFlush(
LongStream.range(3, 1000)
.mapToObj(i -> new Post()
.setId(i)
.setTitle(String.format("Post %d", i))
.setSlug(String.format("post-%d", i))
)
.collect(Collectors.toList())
);
A přenesení změn z některých oddělených entit zpět do databáze se provádí následovně:
List<Post> posts = transactionTemplate.execute(transactionStatus ->
entityManager.createQuery("""
select p
from Post p
where p.id < 10
""", Post.class)
.getResultList()
);
posts.forEach(post ->
post.setTitle(post.getTitle() + " rocks!")
);
transactionTemplate.execute(transactionStatus ->
postRepository.updateAll(posts)
);
A na rozdíl od merge , update nám umožňuje vyhnout se zbytečnému SELECT a existuje pouze jeden UPDATE probíhá:
Query:[" update post set slug=?, title=? where id=?" ], Params:[ (high-performance-java-persistence, High-Performance Java Persistence rocks!, 1), (hypersistence-optimizer, Hypersistence Optimizer rocks!, 2), (post-3, Post 3 rocks!, 3), (post-4, Post 4 rocks!, 4), (post-5, Post 5 rocks!, 5), (post-6, Post 6 rocks!, 6), (post-7, Post 7 rocks!, 7), (post-8, Post 8 rocks!, 8), (post-9, Post 9 rocks!, 9) ]
Skvělé, že?
Závislost na Maven
HibernateRepository je k dispozici na Maven Central, takže první věc, kterou musíme udělat, je přidat závislost Hibernate Types. Pokud například používáte Maven, musíte do svého projektu přidat následující závislost pom.xml konfigurační soubor:
Pro Hibernate 6:
<dependency>
<groupId>com.vladmihalcea</groupId>
<artifactId>hibernate-types-60</artifactId>
<version>${hibernate-types.version}</version>
</dependency>
Pro Hibernate 5.5 a 5.4:
<dependency>
<groupId>com.vladmihalcea</groupId>
<artifactId>hibernate-types-55</artifactId>
<version>${hibernate-types.version}</version>
</dependency>
A pro Hibernate 5.3 a 5.2:
<dependency>
<groupId>com.vladmihalcea</groupId>
<artifactId>hibernate-types-52</artifactId>
<version>${hibernate-types.version}</version>
</dependency>
Poté musíte zahrnout com.vladmihalcea.spring.repository v @EnableJpaRepositories konfigurace, jako toto:
@Configuration
@EnableJpaRepositories(
basePackages = {
"com.vladmihalcea.spring.repository",
...
}
)
public class JpaConfiguration {
...
}
A je to!
Vaše jarní datová úložiště nyní mohou rozšířit úžasné HibernateRepository utility, což je mnohem lepší alternativa k výchozímu Spring Data JpaRepository .
Závěr
JPA nemá nic takového jako save metoda. Je to jen hack, který musel být implementován v JpaRepository protože metoda je zděděna z CrudRepository , což je základní rozhraní sdílené téměř projekty Spring Data.
Pomocí HibernateRepository , nejen že můžete lépe zdůvodnit, kterou metodu musíte volat, ale můžete také těžit z update metoda, která poskytuje lepší výkon pro úlohy dávkového zpracování.