Tiered Compilation i JVM
1. Oversigt
JVM'en fortolker og udfører bytekode under kørsel. Derudover gør den brug af just-in-time (JIT) kompileringen til at øge ydeevnen.
I tidligere versioner af Java var vi nødt til manuelt at vælge mellem de to typer JIT-kompilere, der var tilgængelige i Hotspot JVM. Den ene er optimeret til hurtigere applikationsopstart, mens den anden opnår en bedre samlet ydeevne. Java 7 introducerede lagdelt kompilering for at opnå det bedste fra begge verdener.
I denne tutorial ser vi på klient- og server-JIT-kompilatorerne. Vi vil gennemgå trindelt kompilering og dens fem kompileringsniveauer. Til sidst vil vi se, hvordan metodekompilering fungerer ved at spore kompileringslogfilerne.
2. JIT-kompilatorer
En JIT-compiler kompilerer bytekode til native kode for ofte udførte sektioner . Disse sektioner kaldes hotspots, deraf navnet Hotspot JVM. Som et resultat kan Java køre med lignende ydeevne som et fuldt kompileret sprog. Lad os se på de to typer af JIT-kompilere, der er tilgængelige i JVM.
2.1. C1 – Klientleverandør
Klientkompileren, også kaldet C1, er en type JIT-kompiler optimeret til hurtigere opstartstid . Den forsøger at optimere og kompilere koden så hurtigt som muligt.
Historisk har vi brugt C1 til kortlivede applikationer og applikationer, hvor opstartstid var et vigtigt ikke-funktionelt krav. Før Java 8 var vi nødt til at angive -klienten flag for at bruge C1-kompileren. Men hvis vi bruger Java 8 eller højere, har dette flag ingen effekt.
2.2. C2 – Server Complier
Servercompileren, også kaldet C2, er en type JIT-kompiler optimeret til bedre generel ydeevne . C2 observerer og analyserer koden over længere tid sammenlignet med C1. Dette giver C2 mulighed for at lave bedre optimeringer i den kompilerede kode.
Historisk set brugte vi C2 til langvarige server-side applikationer. Før Java 8 var vi nødt til at angive -serveren flag for at bruge C2-kompileren. Dette flag vil dog ikke have nogen effekt i Java 8 eller nyere.
Vi skal bemærke, at Graal JIT-kompileren også er tilgængelig siden Java 10, som et alternativ til C2. I modsætning til C2 kan Graal køre i både just-in-time og ahead-of-time kompileringstilstande for at producere indbygget kode.
3. Trindelt kompilering
C2-kompileren tager ofte mere tid og bruger mere hukommelse til at kompilere de samme metoder. Det genererer dog bedre optimeret indbygget kode end den, der produceres af C1.
Det trindelte kompileringskoncept blev først introduceret i Java 7. Dets mål var at bruge en blanding af C1- og C2-kompilere for at opnå både hurtig opstart og god langsigtet ydeevne .
3.1. Det bedste fra begge verdener
Ved opstart af applikationen fortolker JVM i første omgang al bytekode og indsamler profiloplysninger om den. JIT-kompileren gør derefter brug af den indsamlede profilinformation til at finde hotspots.
For det første kompilerer JIT-kompileren de ofte udførte kodesektioner med C1 for hurtigt at nå indbygget kodeydeevne. Senere slår C2 ind, når flere profiloplysninger er tilgængelige. C2 omkompilerer koden med mere aggressive og tidskrævende optimeringer for at øge ydeevnen:
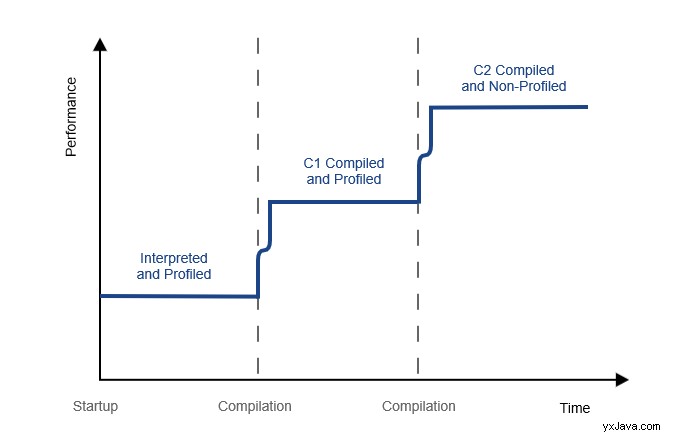
Kort sagt, C1 forbedrer ydeevnen hurtigere, mens C2 giver bedre ydeevneforbedringer baseret på flere oplysninger om hotspots.
3.2. Nøjagtig profilering
En yderligere fordel ved opdelt kompilering er mere nøjagtige profileringsoplysninger. Før opdelt kompilering indsamlede JVM kun profileringsoplysninger under fortolkning.
Med trindelt kompilering aktiveret, indsamlerJVM også profileringsoplysninger om den C1-kompilerede kode . Da den kompilerede kode opnår bedre ydeevne, giver den JVM'en mulighed for at indsamle flere profileksempler.
3.3. Kodecache
Kodecache er et hukommelsesområde, hvor JVM'en gemmer al bytekode kompileret til native kode. Lagdelt kompilering øgede mængden af kode, der skal cachelagres op til fire gange.
Siden Java 9 segmenterer JVM kodecachen i tre områder:
- Ikke-metodesegmentet – JVM intern relateret kode (omkring 5 MB, konfigurerbar via -XX:NonNMethodCodeHeapSize )
- Det profilerede kodesegment – C1-kompileret kode med potentielt korte levetider (omkring 122 MB som standard, konfigurerbar via -XX:ProfiledCodeHeapSize )
- Det ikke-profilerede segment – C2-kompileret kode med potentielt lange levetider (tilsvarende 122 MB som standard, konfigurerbar via -XX:NonProfiledCodeHeapSize )
Segmenteret kodecache hjælper med at forbedre kodelokaliteten og reducerer hukommelsesfragmentering . Det forbedrer således den samlede ydeevne.
3.4. Deoptimering
Selvom C2 kompileret kode er meget optimeret og lang levetid, kan den deoptimeres. Som følge heraf ville JVM midlertidigt rulle tilbage til tolkning.
Deoptimering sker når compilerens optimistiske antagelser er bevist forkerte — for eksempel, når profiloplysninger ikke stemmer overens med metodeadfærd:
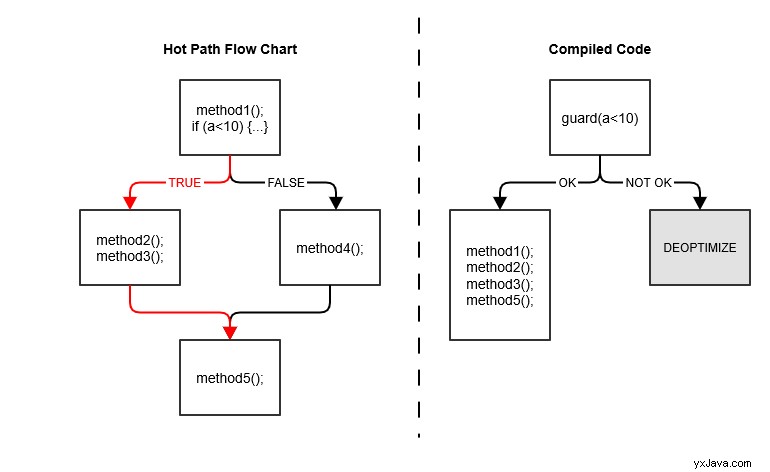
I vores eksempel, når den varme vej ændres, deoptimerer JVM den kompilerede og indlejrede kode.
4. Kompileringsniveauer
Selvom JVM kun fungerer med én tolk og to JIT-kompilatorer, er der fem mulige kompileringsniveauer . Grunden til dette er, at C1-kompileren kan fungere på tre forskellige niveauer. Forskellen mellem disse tre niveauer er mængden af profilering, der udføres.
4.1. Niveau 0 – Fortolket kode
I første omgang fortolker JVM al Java-kode . I denne indledende fase er ydelsen normalt ikke så god sammenlignet med kompilerede sprog.
JIT-kompileren starter dog efter opvarmningsfasen og kompilerer den varme kode under kørsel. JIT-kompileren gør brug af de profileringsoplysninger, der er indsamlet på dette niveau, til at udføre optimeringer.
4.2. Niveau 1 – Simpel C1 kompileret kode
På dette niveau kompilerer JVM koden ved hjælp af C1-kompileren, men uden at indsamle nogen profileringsoplysninger. JVM bruger niveau 1 til metoder, der betragtes som trivielle .
På grund af lav metodekompleksitet ville C2-kompileringen ikke gøre det hurtigere. JVM konkluderer således, at det ikke nytter noget at indsamle profileringsoplysninger for kode, der ikke kan optimeres yderligere.
4.3. Niveau 2 – Begrænset C1-kompileret kode
På niveau 2 kompilerer JVM koden ved hjælp af C1-kompileren med lysprofilering. JVM'en bruger dette niveau når C2-køen er fuld . Målet er at kompilere koden så hurtigt som muligt for at forbedre ydeevnen.
Senere kompilerer JVM koden på niveau 3 ved hjælp af fuld profilering. Endelig, når først C2-køen er mindre optaget, genkompilerer JVM den på niveau 4.
4.4. Niveau 3 – Fuld C1-kompileret kode
På niveau 3 kompilerer JVM koden ved hjælp af C1-kompileren med fuld profilering. Niveau 3 er en del af standardkompileringsstien. Således bruger JVM det ialle tilfælde undtagen for trivielle metoder, eller når compilerkøerne er fulde .
Det mest almindelige scenarie i JIT-kompilering er, at den fortolkede kode hopper direkte fra niveau 0 til niveau 3.
4.5. Niveau 4 – C2 Kompileret kode
På dette niveau kompilerer JVM koden ved hjælp af C2-kompileren for maksimal langsigtet ydeevne. Niveau 4 er også en del af standard kompileringsstien. JVM bruger dette niveau til at kompilere alle metoder undtagen trivielle .
Da niveau 4-koden anses for at være fuldt optimeret, stopper JVM med at indsamle profileringsoplysninger. Det kan dog beslutte at deoptimere koden og sende den tilbage til niveau 0.
5. Kompileringsparametre
Lagdelt kompilering er aktiveret som standard siden Java 8 . Det anbefales stærkt at bruge det, medmindre der er en stærk grund til at deaktivere det.
5.1. Deaktivering af lagdelt kompilering
Vi kan deaktivere lagdelt kompilering ved at indstille –XX:-Tiered Compilation flag. Når vi indstiller dette flag, vil JVM ikke skifte mellem kompileringsniveauer. Som et resultat bliver vi nødt til at vælge, hvilken JIT-kompiler der skal bruges:C1 eller C2.
Medmindre det er udtrykkeligt angivet, beslutter JVM, hvilken JIT-kompiler der skal bruges baseret på vores CPU. For multi-core processorer eller 64-bit VM'er vil JVM'en vælge C2. For at deaktivere C2 og kun bruge C1 uden profileringsoverhead, kan vi anvende -XX:TieredStopAtLevel=1 parameter.
For fuldstændigt at deaktivere begge JIT-kompilatorer og køre alt ved hjælp af tolken, kan vi anvende -Xint flag. Vi skal dog bemærke, at deaktivering af JIT-kompilere vil have en negativ indvirkning på ydeevnen .
5.2. Indstilling af tærskler for niveauer
En kompileringstærskel er antallet af metodeankaldelser, før koden kompileres . I tilfælde af opdelt kompilering kan vi indstille disse tærskler for kompileringsniveauer 2-4. For eksempel kan vi indstille en parameter -XX:Tier4CompileThreshold=10000 .
For at kontrollere standardtærsklerne, der bruges på en specifik Java-version, kan vi køre Java ved hjælp af -XX:+PrintFlagsFinal flag:
java -XX:+PrintFlagsFinal -version | grep CompileThreshold
intx CompileThreshold = 10000
intx Tier2CompileThreshold = 0
intx Tier3CompileThreshold = 2000
intx Tier4CompileThreshold = 15000Vi skal bemærke, at JVM ikke bruger den generiske CompileThreshold parameter, når lagdelt kompilering er aktiveret .
6. Metodekompilering
Lad os nu tage et kig på en metodekompileringslivscyklus:
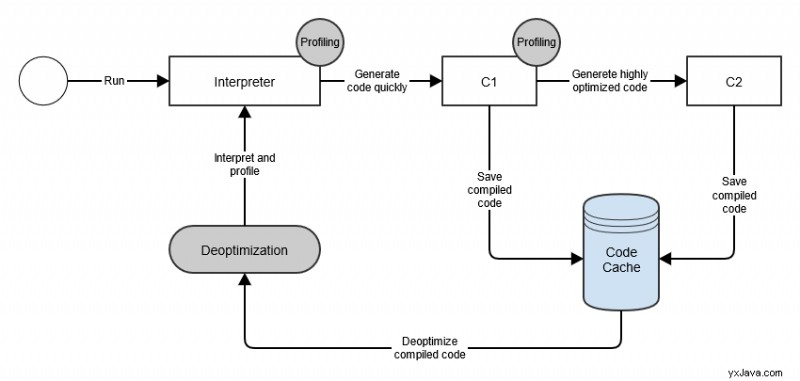
Sammenfattende fortolker JVM i første omgang en metode, indtil dens påkald når Tier3CompileThreshold . Derefter kompilerer den metoden ved hjælp af C1-kompileren, mens profileringsoplysninger fortsætter med at blive indsamlet . Endelig kompilerer JVM metoden ved hjælp af C2-kompileren, når dens kald når Tier4CompileThreshold . Til sidst kan JVM beslutte at deoptimere den C2 kompilerede kode. Det betyder, at hele processen gentages.
6.1. Kompileringslogfiler
Som standard er JIT-kompileringslogfiler deaktiveret. For at aktivere dem kan vi indstille -XX:+PrintCompilation flag . Kompileringslogfilerne er formateret som:
- Tidsstempel – i millisekunder siden applikationsstart
- Kompilerings-id – Inkrementelt ID for hver kompilerede metode
- Attributter – Kompilationens tilstand med fem mulige værdier:
- % – Udskiftning på stakken fandt sted
- s – Metoden er synkroniseret
- ! – Metoden indeholder en undtagelsesbehandler
- b – Kompileringen fandt sted i blokeringstilstand
- n – Kompilering transformerede en indpakning til en indbygget metode
- Kompileringsniveau – mellem 0 og 4
- Metodenavn
- Bytekodestørrelse
- Deoptimeringsindikator – Med to mulige værdier:
- Givet ikke-deltager – Standard C1-deoptimering eller compilerens optimistiske antagelser har vist sig at være forkerte
- Lavet zombie – En oprydningsmekanisme til skraldeopsamleren for at frigøre plads fra kodecachen
6.2. Et eksempel
Lad os demonstrere metodekompileringens livscyklus med et simpelt eksempel. Først opretter vi en klasse, der implementerer en JSON-formatering:
public class JsonFormatter implements Formatter {
private static final JsonMapper mapper = new JsonMapper();
@Override
public <T> String format(T object) throws JsonProcessingException {
return mapper.writeValueAsString(object);
}
}Dernæst opretter vi en klasse, der implementerer den samme grænseflade, men implementerer en XML-formatering:
public class XmlFormatter implements Formatter {
private static final XmlMapper mapper = new XmlMapper();
@Override
public <T> String format(T object) throws JsonProcessingException {
return mapper.writeValueAsString(object);
}
}Nu vil vi skrive en metode, der bruger de to forskellige formateringsimplementeringer. I den første halvdel af løkken bruger vi JSON-implementeringen og skifter derefter til XML-en for resten:
public class TieredCompilation {
public static void main(String[] args) throws Exception {
for (int i = 0; i < 1_000_000; i++) {
Formatter formatter;
if (i < 500_000) {
formatter = new JsonFormatter();
} else {
formatter = new XmlFormatter();
}
formatter.format(new Article("Tiered Compilation in JVM", "Baeldung"));
}
}
}Til sidst indstiller vi -XX:+PrintCompilation flag, kør hovedmetoden og observer kompileringsloggene.
6.3. Gennemse logfiler
Lad os fokusere på log-output for vores tre brugerdefinerede klasser og deres metoder.
De første to logposter viser, at JVM kompilerede main metoden og JSON-implementeringen af formatet metode på niveau 3. Derfor blev begge metoder kompileret af C1-kompileren. Den C1 kompilerede kode erstattede den oprindeligt fortolkede version:
567 714 3 com.baeldung.tieredcompilation.JsonFormatter::format (8 bytes)
687 832 % 3 com.baeldung.tieredcompilation.TieredCompilation::main @ 2 (58 bytes)A few hundred milliseconds later, the JVM compiled both methods on level 4. Hence, the C2 compiled versions replaced the previous versions compiled with C1:
659 800 4 com.baeldung.tieredcompilation.JsonFormatter::format (8 bytes)
807 834 % 4 com.baeldung.tieredcompilation.TieredCompilation::main @ 2 (58 bytes)Blot et par millisekunder senere ser vi vores første eksempel på deoptimering. Her markerede JVM'en forældet (ikke deltager) de C1 kompilerede versioner:
812 714 3 com.baeldung.tieredcompilation.JsonFormatter::format (8 bytes) made not entrant
838 832 % 3 com.baeldung.tieredcompilation.TieredCompilation::main @ 2 (58 bytes) made not entrantEfter et stykke tid vil vi bemærke endnu et eksempel på deoptimering. Denne logpost er interessant, da JVM-mærket forældet (ikke deltager) de fuldt optimerede C2-kompilerede versioner. Det betyder, at JVM rullede den fuldt optimerede kode tilbage, da den opdagede, at den ikke var gyldig længere:
1015 834 % 4 com.baeldung.tieredcompilation.TieredCompilation::main @ 2 (58 bytes) made not entrant
1018 800 4 com.baeldung.tieredcompilation.JsonFormatter::format (8 bytes) made not entrant
Dernæst vil vi se XML-implementeringen af formatet metode for første gang. JVM kompilerede det på niveau 3 sammen med main metode:
1160 1073 3 com.baeldung.tieredcompilation.XmlFormatter::format (8 bytes)
1202 1141 % 3 com.baeldung.tieredcompilation.TieredCompilation::main @ 2 (58 bytes)Et par hundrede millisekunder senere kompilerede JVM begge metoder på niveau 4. Men denne gang er det XML-implementeringen, der blev brugt af main metode:
1341 1171 4 com.baeldung.tieredcompilation.XmlFormatter::format (8 bytes)
1505 1213 % 4 com.baeldung.tieredcompilation.TieredCompilation::main @ 2 (58 bytesSamme som før, et par millisekunder senere, markerede JVM'en forældet (ikke aktør) de C1 kompilerede versioner:
1492 1073 3 com.baeldung.tieredcompilation.XmlFormatter::format (8 bytes) made not entrant
1508 1141 % 3 com.baeldung.tieredcompilation.TieredCompilation::main @ 2 (58 bytes) made not entrantJVM fortsatte med at bruge niveau 4 kompilerede metoder indtil slutningen af vores program.
7. Konklusion
I denne artikel undersøgte vi det niveaudelte kompileringskoncept i JVM. Vi gennemgik de to typer JIT-kompilatorer, og hvordan tiered compilation bruger dem begge for at opnå de bedste resultater. Vi så fem niveauer af kompilering og lærte, hvordan man styrer dem ved hjælp af JVM-parametre.
I eksemplerne udforskede vi hele metodekompileringslivscyklussen ved at observere kompileringslogfilerne.
Som altid er kildekoden tilgængelig på GitHub.