Valg af en hurtig unik identifikator (UUID) for Lucene
De fleste søgeapplikationer, der bruger Apache Lucene, tildeler et unikt id eller primær nøgle til hvert indekseret dokument. Selvom Lucene ikke selv kræver dette (det kunne være ligeglad!), har applikationen normalt brug for det til senere at erstatte, slette eller hente det ene dokument med dets eksterne id. De fleste servere bygget oven på Lucene, såsom Elasticsearch og Solr, kræver et unikt id og kan automatisk generere et, hvis du ikke giver det.
Nogle gange er dine id-værdier allerede foruddefineret, for eksempel hvis en ekstern database eller et indholdsstyringssystem har tildelt en, eller hvis du skal bruge en URI, men hvis du frit kan tildele dine egne id'er, hvad fungerer så bedst for Lucene?
Et oplagt valg er Javas UUID-klasse, som genererer version 4 universelt unikke identifikatorer, men det viser sig, at dette er det værste valg for ydeevne:det er 4X langsommere end det hurtigste. At forstå hvorfor kræver en vis forståelse af, hvordan Lucene finder termer.
BlockTree termordbog
Formålet med termordbogen er at gemme alle unikke termer set under indeksering og kortlægge hvert udtryk til dets metadata (docFreq , totalTermFreq osv.), samt bogføringerne (bilag, modregninger, posteringer og nyttelast). Når der anmodes om et udtryk, skal termordbogen finde det i indekset på disken og returnere dets metadata.
Standard-codec'en bruger BlockTree-term-ordbogen, som gemmer alle termer for hvert felt i sorteret binær rækkefølge, og tildeler termerne i blokke, der deler et fælles præfiks. Hver blok indeholder mellem 25 og 48 termer som standard. Den bruger en præfiks-forsøgsindeksstruktur i hukommelsen (en FST) til hurtigt at kortlægge hvert præfiks til den tilsvarende blok på disken, og ved opslag tjekker den først indekset baseret på det anmodede udtryks præfiks og søger derefter efter det relevante på -disk blok og scanner for at finde udtrykket.
I visse tilfælde, når termerne i et segment har et forudsigeligt mønster, kan termindekset vide, at den ønskede term ikke kan eksistere på disken. Denne hurtige match-test kan være en betydelig præstationsgevinst, især når indekset er koldt (siderne cachelagres ikke af operativsystemets IO-cache), da den undgår en dyr disksøgning. Da Lucene er segmentbaseret, skal et enkelt id-opslag besøge hvert segment, indtil det finder et match, så hurtigt at udelukke et eller flere segmenter kan være en stor gevinst. Det er også vigtigt at holde dit segmentantal så lavt som muligt!
I betragtning af dette burde fuldt tilfældige id'er (som UUID V4) fungere dårligst, fordi de besejrer termindeksets hurtige match-test og kræver en disksøgning for hvert segment. Id'er med et forudsigeligt mønster pr. segment, såsom sekventielt tildelte værdier eller et tidsstempel, bør fungere bedst, da de vil maksimere gevinsterne fra termindeksets hurtige match-test.
Test af ydeevne
Jeg oprettede en simpel ydelsestester for at bekræfte dette; den fulde kildekode er her. Testen indekserer først 100 millioner id'er til et indeks med 7/7/8 segmentstruktur (7 store segmenter, 7 mellemstore segmenter, 8 små segmenter), og søger derefter efter en tilfældig delmængde af 2 millioner af ID'erne og registrerer den bedste tid af 5 løb. Jeg brugte Java 1.7.0_55 på Ubuntu 14.04 med en 3,5 GHz Ivy Bridge Core i7 3770K.
Da Lucenes termer nu er fuldt binære fra 4.0, er den mest kompakte måde at gemme enhver værdi på i binær form, hvor alle 256 værdier af hver byte bruges. En 128-bit id-værdi kræver så 16 bytes.
Jeg testede følgende identifikationskilder:
- Sekventielle id'er (0, 1, 2, …), binært kodet.
- Nulpolstrede sekventielle id'er (00000000, 00000001, …), binært kodet.
- Nanotid, binært kodet. Men husk, at nanotid er vanskelig.
- UUID V1, afledt af et tidsstempel, nodeID og sekvenstæller, der bruger denne implementering.
- UUID V4, tilfældigt genereret ved hjælp af Javas
UUID.randomUUID(). - Flage-id'er, ved hjælp af denne implementering.
For UUID'erne og Flake ID'erne testede jeg også binær kodning ud over deres standard (base 16 eller 36) kodning. Bemærk, at jeg kun testede opslagshastighed ved hjælp af en tråd, men resultaterne skal skaleres lineært (på tilstrækkeligt samtidig hardware), når du tilføjer tråde.
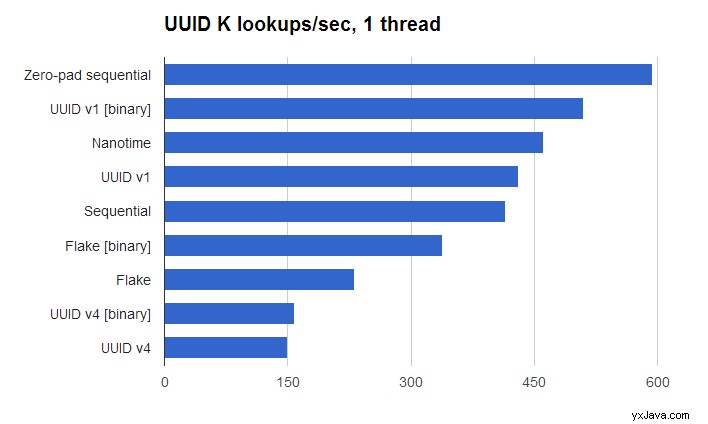
Nulpolstrede sekventielle id'er, kodet i binært, er hurtigst, en del hurtigere end ikke-nulpolstrede sekventielle id'er. UUID V4 (ved hjælp af Javas UUID.randomUUID() ) er ~4X langsommere.
Men for de fleste applikationer er sekventielle id'er ikke praktiske. Den næsthurtigste er UUID V1, kodet i binært. Jeg var overrasket over, at dette er så meget hurtigere end Flake ID'er, da Flake ID'er bruger de samme rå informationskilder (tid, node-id, sekvens), men blander bitsene anderledes for at bevare den samlede bestilling. Jeg formoder, at problemet er antallet af almindelige førende cifre, der skal krydses i et Flake ID, før du kommer til cifre, der adskiller sig på tværs af dokumenter, da højordens bits af 64-bit tidsstemplet kommer først, hvorimod UUID V1 placerer den lave orden bits af 64-bit tidsstemplet først. Måske skal termindekset optimere tilfældet, når alle termer i ét felt deler et fælles præfiks.
Jeg testede også separat ved at variere basen fra 10, 16, 36, 64, 256 og generelt for de ikke-tilfældige id'er er højere baser hurtigere. Jeg blev glædeligt overrasket over dette, fordi jeg forventede, at en base, der matchede BlockTree-blokstørrelsen (25 til 48), ville være bedst.
Der er nogle vigtige forbehold til denne test (patches er velkomne)! En rigtig applikation ville naturligvis gøre meget mere arbejde end blot at slå id'er op, og resultaterne kan være anderledes, da hotspot skal kompilere meget mere aktiv kode. Indekset er fuldt varmt i min test (masser af RAM til at holde hele indekset); for et koldt indeks ville jeg forvente, at resultaterne bliver endnu mere skarpe, da det bliver så meget vigtigere at undgå en disk-søgning. I en rigtig applikation ville de id'er, der bruger tidsstempler, være mere spredt fra hinanden i tid; Jeg kunne selv "simulere" dette ved at forfalske tidsstemplerne over et bredere område. Måske ville dette lukke kløften mellem UUID V1 og Flake ID'er? Jeg brugte kun én tråd under indeksering, men en rigtig applikation med flere indekseringstråde ville sprede id'erne ud over flere segmenter på én gang.
Jeg brugte Lucenes standard TieredMergePolicy, men det er muligt, at en smartere fusionspolitik, der favoriserede fletning af segmenter, hvis id'er var mere "lignende", kan give bedre resultater. Testen udfører ingen sletninger/opdateringer, hvilket ville kræve mere arbejde under opslag, da et givet id kan være i mere end ét segment, hvis det var blevet opdateret (bare slettet i alle undtagen ét af dem).
Endelig brugte jeg at bruge Lucenes standard-codec, men vi har gode opslagsformater, der er optimeret til primærnøgleopslag, når du er villig til at bytte RAM med hurtigere opslag, såsom dette Google summer-of-code-projekt fra sidste år og MemoryPostingsFormat. Disse vil sandsynligvis give betydelige præstationsgevinster!