ChronicleMap – Java-arkitektur med Off Heap-hukommelse
Mit sidste indlæg blev skrevet for et par uger siden, og efter nogle gyldige tilbagemeldinger vil jeg gerne præcisere et par punkter som et forord til denne artikel.
Det vigtigste ved at 'oprette millioner af objekter med Zero Garbage' burde være, at du med Chronicle ikke er 'begrænset' til at bruge jvm-allokeret on-heap-hukommelse, når du skriver et Java-program. Måske ville artiklen have haft mere passende titlen 'Creating Millions of Objects using Zero Heap'. Et andet punkt, jeg ville fremhæve, var, at når du ikke har nogen heap-hukommelse, forårsager du ingen GC-aktivitet.
En kilde til forvirring kom fra det faktum, at jeg brugte udtrykket 'skrald' til at beskrive de genstande, der var allokeret på dyngen. De tildelte genstande var faktisk ikke skrald, selvom de forårsagede GC-aktivitet.
Jeg udtænkte et eksempel for at demonstrere, et, at ChronicleMap ikke bruger heap-hukommelse, mens ConcurrentHashMap gør, og to, at når du bruger heap-hukommelse, kan du ikke ignorere GC. Du skal i det mindste tune dit system omhyggeligt for at sikre, at du ikke ender med at lide af lange GC-pauser. Dette betyder ikke, at der ikke er problemer med at allokere fra off-heap (se slutningen af dette indlæg), og det betyder heller ikke, at du ikke kan tune dig igennem en on-heap-løsning for at eliminere GC. At gå væk er på ingen måde et universalmiddel til alle Java-ydeevneproblemer, men for meget specifikke løsninger kan det give interessante muligheder, som jeg vil diskutere i dette indlæg.
Der kan være tilfælde, hvor du muligvis skal dele data mellem JVM'er.
Lad os forenkle for nu og sige, at du har to JVM'er, der kører på den samme maskine, som den ene eller begge gerne vil se opdateringer fra den anden. Hvert Java-program har en ConcurrentHashMap som den opdaterer, gemmes disse opdateringer og er tilgængelige for den senere. Men hvordan får programmet opdateringerne anvendt af det andet Java-program til sit kort?
Grundlæggende er JDK on-heap-samlinger såsom HashMap og ConcurrentHashMap kan ikke deles direkte mellem JVM'er. Dette skyldes, at heap-hukommelse er indeholdt af den JVM, hvorigennem den blev allokeret. Derfor, når JVM'en forlader, frigives hukommelsen, og dataene ikke længere er tilgængelige, er der ingen implicit måde at bevare hukommelsen uden for JVM'ens levetid. Så du skal finde en anden mekanisme til at dele data mellem JVM'erne. Typisk kan du bruge en database som en ekstern delbar butik og beskedtjeneste til at sende dataopdateringerne til andre processer for at underrette dem om, at nogle data er blevet opdateret.
Dette resulterer i følgende arkitektur:
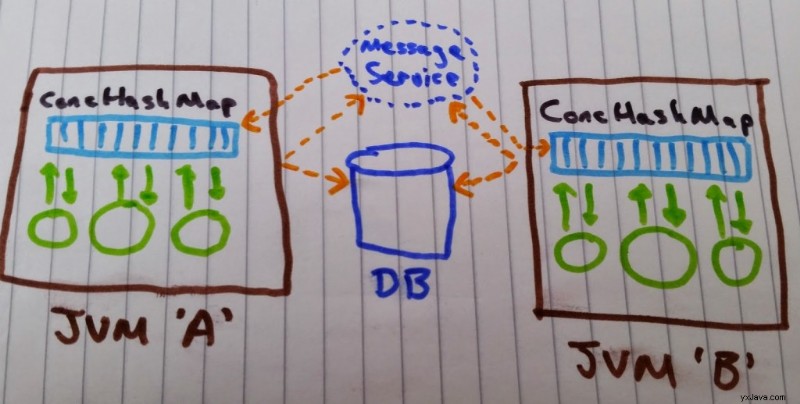
Problemet med denne arkitektur er, at brug mister hastighederne i hukommelsen af et HashMap, især hvis skrivning til din database ikke er så hurtig, og du ønsker, at skrivningen skal fortsætte, før du sender beskeden ud over beskedtjenesten. Mange løsninger vil også involvere TCP-opkald, som igen kan være en kilde til latenstid.
Der er selvfølgelig meget hurtigere måder at bevare data på end at skrive til en fuldgyldig database ved hjælp af mekanismer som journalisering til disk, for eksempel ved at bruge et produkt som ChronicleQueue eller lignende. Men hvis du brugte en journal, skulle du stadig bygge al logikken for at genskabe en Map datastruktur ved genstart for ikke at nævne at skulle holde en korttypestruktur opdateret på en anden JVM.
(Grunden til, at du måske overhovedet vil bevare dataene, er, at du skal være i stand til at gendanne i tilfælde af en genstart uden at skulle afspille alle data fra kilden). Ud over den latenstid, som denne arkitektur introducerer, er der komplikationen ved at skulle håndtere den ekstra kode og konfiguration til databasen og meddelelsestjenesten.
Selv at acceptere, at denne form for funktionalitet kan pakkes ind i rammer, ville det ikke være fantastisk, hvis du i hukommelsen Map var faktisk synlig uden for din JVM. Map skal implicit kunne bevare dataene, så dets data er tilgængelige uafhængigt af JVM'ens levetid. Det bør give adgang med de samme "hukommelses"-hastigheder, som du kan opnå ved at bruge et on heap-kort.
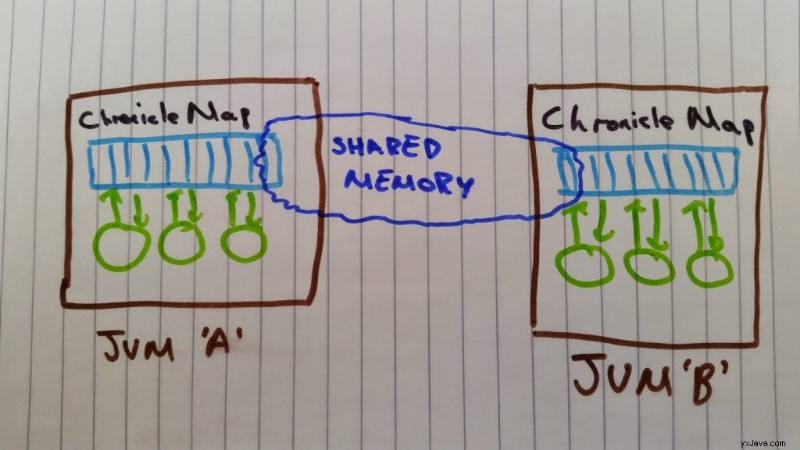
Det er her ChronicleMap kommer ind. ChronicleMap er en implementering af java.util.ConcurrentMap men kritisk bruger den off heap-hukommelse som er synlig uden for JVM'en for enhver anden proces, der kører på maskinen. (For en diskussion om on-heap vs off-heap hukommelse se her).
Hver JVM vil oprette en ChronicleMap peger på de samme hukommelseskortede filer. Når en proces skriver ind i sin ChronicleMap den anden proces kan øjeblikkeligt (~40 nanosekunder) se opdateringen i dens ChronicleMap . Da dataene er lagret i hukommelsen uden for JVM'en, vil en JVM-afslutning ikke medføre, at nogen data går tabt. Dataene vil blive opbevaret i hukommelsen (forudsat at det ikke var nødvendigt at søge dem ud), og når JVM'en genstarter, kan den kortlægge dem tilbage ekstremt hurtigt. Den eneste måde, hvorpå data kan gå tabt, er, hvis operativsystemet går ned, mens det har snavsede sider, der ikke er blevet lagret på disken. Løsningen på dette er brugsreplikering, som Chronicle understøtter, men som ligger uden for dette indlægs omfang.
Arkitekturen for dette er simpelthen denne:
For et kodeeksempel for at komme i gang med ChronicleMap se mit sidste indlæg eller se den officielle ChronicleMap-vejledning her.
Der er en række forbehold og afvejninger at overveje, før du dykker ned i ChronicleMap.
- ChronicleMap-posterne skal kunne serialiseres. For systemer, der er meget følsomme over for ydeevne, skal du implementere den tilpassede serialisering leveret af Chronicle kendt som BytesMarshallable. Selvom dette er ret nemt at implementere, er det ikke noget, der er nødvendigt med et on-heap-kort. (Når det er sagt, vil lagring af data i en database naturligvis også kræve en eller anden metode til serialisering.)
- Selv med BytesMarshallable-serialisering kan overhead af enhver serialisering være væsentlig for nogle systemer. I et sådant scenarie er det muligt at anvende en nulkopiteknik understøttet af Chronicle (se mit sidste blogindlæg for flere detaljer) for at minimere omkostningerne ved serialisering. Det er dog lidt vanskeligere at implementere end at bruge 'normal' Java. På den anden side vil det i programmer, der er følsomme over for latenstider, have den store fordel, at det ikke skaber nogen objekter, som måske senere skal ryddes op af GC'en.
- Et ChronicleMap ændrer ikke størrelse og skal derfor have en størrelse foran. Dette kan være et problem, hvis du ikke har nogen idé om, hvor mange varer du kan forvente. Det skal dog bemærkes, at overdimensionering, i det mindste på Linux, ikke er et stort problem, da Linux passivt allokerer hukommelse.
- Chronicle er afhængig af, at operativsystemet asynkront flush til disken. Hvis du vil være helt sikker på, at data rent faktisk er blevet skrevet til disken (i modsætning til blot at blive holdt i hukommelsen), skal du replikere til en anden maskine. I virkeligheden burde ethvert missionskritisk system kopiere til en anden maskine, så dette er måske ikke et stort problem ved at adoptere Chronicle.
- ChronicleMap vil være underlagt OS-hukommelsessøgningsproblemer. Hvis hukommelsen bladres ud og skal skiftes tilbage, vil latenstiden blive introduceret i systemet. Derfor, selvom du vil være i stand til at oprette ChronicleMaps med størrelser langt over hovedhukommelsen, skal du være opmærksom på, at personsøgning kan forekomme afhængigt af dine adgangsmønstre på dataene.