Går off-heap for at forbedre latens og reducere AWS-regningen
De fleste præstationsproblemer kan løses på flere forskellige måder. Mange af de anvendelige løsninger er velkendte og velkendte for de fleste af jer. Nogle løsninger, som at fjerne visse datastrukturer fra den JVM-administrerede heap, er mere komplekse. Så hvis du ikke er bekendt med konceptet, kan jeg anbefale at fortsætte for at lære, hvordan vi for nylig reducerede både latensen af vores applikationer og halverede vores Amazon AWS-regning.
Jeg vil starte med at forklare den sammenhæng, hvori løsningen var nødvendig. Som du måske ved, holder Plumbr øje med hver brugerinteraktion. Dette gøres ved hjælp af agenter, der er installeret ved siden af applikationsknudepunkter, der behandler interaktionerne.
Mens de gør det, fanger Plumbr Agents forskellige begivenheder fra sådanne noder. Alle hændelser sendes til central Server og er sammensat til det, vi kalder transaktioner. Transaktioner omfatter flere attributter, herunder:
- start- og sluttidsstempel for transaktionen;
- identiteten på den bruger, der udfører transaktionen;
- den udførte handling (føje vare til indkøbskurv, oprette ny faktura osv.);
- applikationen, hvor operationen hører til;
I forbindelse med et bestemt problem, vi stod over for, er det vigtigt at skitsere, at kun en reference til den faktiske værdi gemmes som en attribut for en transaktion. For eksempel, i stedet for at gemme brugerens faktiske identitet (det være sig en e-mail, brugernavn eller cpr-nummer), gemmes en henvisning til en sådan identitet ved siden af selve transaktionen. Så selve transaktionerne kan se sådan ud:
| ID | Start | Slut | Ansøgning | Betjening | Bruger |
|---|---|---|---|---|---|
| #1 | 12:03:40 | 12:05:25 | #11 | #222 | #3333 |
| #2 | 12:04:10 | 12:06:00 | #11 | #223 | #3334 |
Disse referencer er kortlagt med tilsvarende værdier, der kan læses af mennesker. På en sådan måde opretholdes nøgleværdi-tilknytninger pr. attribut, så brugere med ID'er #3333 og #3334 kan opgøres som John Smith og Jane Doe tilsvarende.
Disse tilknytninger bruges under kørsel, når forespørgsler, der får adgang til transaktionerne, erstatter referencerne med de menneskeligt læsbare referencedata:
| ID | Start | Slut | Ansøgning | Betjening | Bruger |
|---|---|---|---|---|---|
| #1 | 12:03:40 | 12:05:25 | www.example.com | /login | John Smith |
| #2 | 12:04:10 | 12:06:00 | www.example.com | /køb | Jane Doe |
Den naive løsning
Jeg vil vædde på, at alle fra vores læsere kan komme med en simpel løsning på et sådant krav med lukkede øjne. Vælg et java.util.Map implementering efter din smag, indlæs nøgleværdi-parrene til kortet og søg de refererede værdier i løbet af forespørgslen.
Det, der føltes nemt, viste sig at være trivielt, da vi opdagede, at vores foretrukne infrastruktur (Druid-lagring med opslagsdata, der ligger i Kafka-emner) allerede understøttede sådanne kort direkte fra boksen via Kafka-opslag.
Problemet
Den naive tilgang tjente os fint i nogen tid. Efter et stykke tid, da opslagskortene blev større, begyndte forespørgsler, der krævede opslagsværdierne, at tage mere og mere tid.
Vi bemærkede dette, mens vi spiste vores egen dogfood og brugte Plumbr til at overvåge selve Plumbr. Vi begyndte at se GC-pauser blive både hyppigere og længere på Druid Historical-knudepunkterne, der servicerede forespørgslerne og løser opslagene.
Tilsyneladende skulle nogle af de mest problematiske forespørgsler slå op på mere end 100.000 forskellige værdier fra kortet. Mens du gjorde det, blev forespørgslerne afbrudt af GC, der startede og overskred varigheden af den tidligere under 100 ms forespørgsel til 10+ sekunder.
Mens vi gravede efter årsagen, fik vi Plumbr til at eksponere heap-øjebliksbilleder fra sådanne problematiske noder, hvilket bekræftede, at omkring 70 % af den brugte heap efter de lange GC-pauser blev brugt af nøjagtigt opslagskortet.
Det blev også tydeligt, at problemet havde en anden dimension at overveje. Vores lagerlag bygger på en klynge af noder, hvor hver maskine i klyngen, der betjener forespørgslerne, kører flere JVM-processer, hvor hver proces kræver de samme referencedata.

I betragtning af, at de pågældende JVM'er kørte med 16G-heap og effektivt duplikerede hele opslagskortet, var det også ved at blive et problem i kapacitetsplanlægningen. De instansstørrelser, der kræves for at understøtte større og større dynger, begyndte at tage vejafgiften i vores EC2-regning.
Så vi var nødt til at finde en anden løsning, der både reducerede byrden til affaldsindsamling og finde en måde at holde Amazon AWS-omkostningerne i skak.
Løsningen:Chronicle Map
Løsningen, som vi implementerede, blev bygget oven på Chronicle Map. Chronicle Map er off-heap i hukommelsesnøgleværdilager. Som vores test viste, var ventetiden til butikken også fremragende. Men den største fordel, hvorfor vi valgte Chronicle Map, var dets evne til at dele data på tværs af flere processer. Så i stedet for at indlæse opslagsværdierne til hver JVM-heap, kunne vi kun bruge én kopi af kortet, der tilgås af forskellige noder i klyngen:

Inden jeg springer i detaljer, så lad mig give dig et overblik over Chronicle Map-funktioner på højt niveau, som vi fandt særligt nyttige. I Chronicle Map kan data overføres til filsystemet og derefter tilgås af enhver samtidig proces i en "visnings"-tilstand.
Så vores mål var at skabe en mikroservice, der ville have rollen som en "skribent", hvilket betyder, at den ville overføre alle de nødvendige data i realtid i filsystemet og rollen som "læseren" - som er vores Druid-datalager. Da Druid ikke understøtter Chronicle Map ud af boksen, implementerede vi vores egen Druid-udvidelse, som er i stand til at læse allerede vedholdende Chronicle-datafiler og erstatte identifikatorer med navne, der kan læses af mennesker under forespørgselstiden. Koden nedenfor giver et eksempel på, hvordan man kan initialisere Chronicle Map:
ChronicleMap.of(String.class, String.class) .averageValueSize(lookup.averageValueSize) .averageKeySize(lookup.averageKeySize) .entries(entrySize) .createOrRecoverPersistedTo(chronicleDataFile);
Denne konfiguration er påkrævet under initialiseringsfasen for at sikre, at Chronicle Map allokerer virtuel hukommelse i henhold til de grænser, du forudsiger. Preallokering af virtuel hukommelse er ikke den eneste optimering, der er foretaget, hvis du fortsætter data i filsystemet som vi gør, vil du bemærke, at Chronicle-datafiler, der oprettes, faktisk er sparsomme filer. Men dette ville være en historie til et helt andet indlæg, så jeg vil ikke dykke ned i disse.
I konfigurationen skal du angive nøgle- og værdityper for det Chronicle Map, du forsøger at oprette. I vores tilfælde er alle referencedata i tekstformat, derfor har vi typen String angivet for både nøglen og værdien.
Efter at have specificeret typer af nøgle og værdi, er der en mere interessant del unik for Chronicle Map-initialiseringen. Som metodenavne antyder både averageValueSize og averageKeySize kræver, at en programmør angiver den gennemsnitlige nøgle- og værdistørrelse, der forventes at blive gemt i Chronicle Map-forekomsten.
Med metode indgange du giver Chronicle Map det forventede samlede antal data, der kan gemmes i instansen. Man kan undre sig over, hvad der vil ske, hvis antallet af registreringer over tid overstiger foruddefineret størrelse? Hvis du går over den konfigurerede grænse, kan du tilsyneladende blive udsat for forringelse af ydeevnen på de sidst indtastede forespørgsler.
En ting mere at overveje, når du overskrider den foruddefinerede poststørrelse, er, at data ikke kan gendannes fra Chronicle Map-filerne uden at opdatere posternes størrelse. Da Chronicle Map under initialisering forudberegner den nødvendige hukommelse til datafilerne, vil data naturligvis ikke passe ind i den forudberegnede hukommelse, hvis indtastningsstørrelsen forbliver den samme, og filen i virkeligheden indeholder, lad os sige 4x flere indgange, derfor mislykkes initialiseringen af Chronicle Map. Det er vigtigt at huske på dette, hvis du gerne vil overleve genstarterne. For eksempel, i vores scenarie, når vi genstarter en mikrotjeneste, der bevarer dataene fra Kafka-emner, før initialisering af forekomsten af Chronicle Map, beregner den dynamisk antallet af indtastninger baseret på mængden af meddelelser i Kafka-emnet. Dette gør det muligt for os at genstarte mikrotjenesten til enhver tid og gendanne allerede beståede Chronicle Map-filer med opdateret konfiguration.
Take-away
Forskellige optimeringer, som gjorde det muligt for Chronicle Map-instansen at læse og skrive data under mikrosekunder, begyndte at have god effekt med det samme. Allerede et par dage efter udgivelsen af Chronicle Map-baseret dataforespørgsel kunne vi se ydeevneforbedringer:
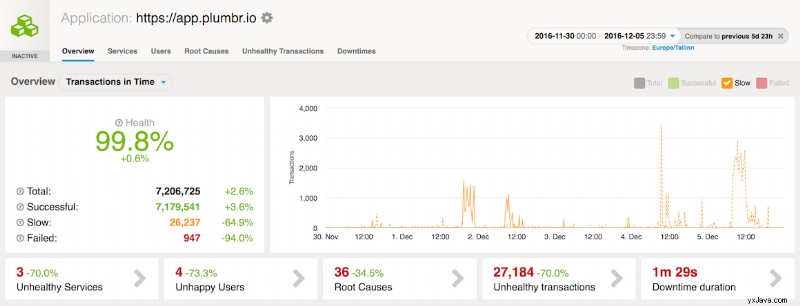
Hertil kommer, at fjernelse af de overflødige kopier af opslagskortet fra hver JVM-bunke gjorde det muligt at skære vores forekomststørrelser for lagernoder betydeligt, hvilket gjorde et synligt indhug i vores Amazon AWS-regning.