Længe leve ETL
Extract transform load er en proces til at trække data fra et datasystem og indlæse i et andet datasystem. Det involverede datasystem kaldes kildesystem og målsystem.
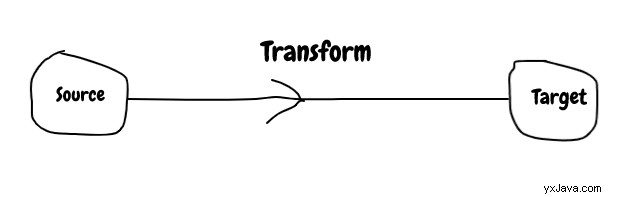
Formen på data fra kildesystemet stemmer ikke overens med målsystemet, så der kræves en vis konvertering for at gøre det kompatibelt, og denne proces kaldes transformation . Transformation er lavet af kort/filter/reducer operationer.
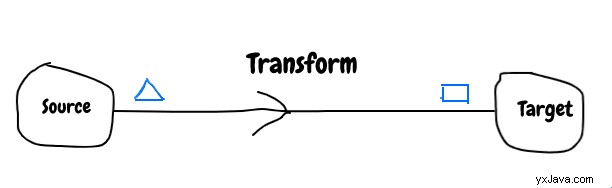
For at håndtere inkompatibiliteten mellem datasystemer kræves nogle metadata. Hvilken type metadata vil være nyttige?
Det er meget almindeligt, at kildedata vil blive transformeret til mange forskellige former for at håndtere forskellige forretningsanvendelser, så det giver mening at bruge beskrivende metadata til kildesystem og præskriptive metadata for målsystem.
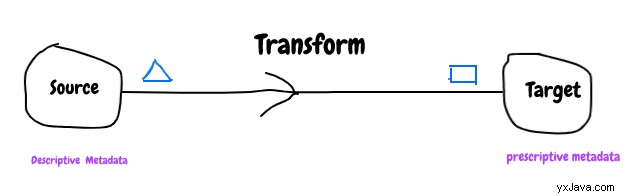
Metadata spiller en vigtig rolle i at gøre systemet både baglæns og frem kompatibel.
Mange gange er det ikke nok at have metadata, fordi nogle kilde-/målsystemdata er for store eller for små til at passe. 
Dette er en situation, hvor transformation bliver interessant. Dette betyder, at en eller anden værdi skal droppes eller indstilles til NULL eller til standardværdi, og det er meget vigtigt at træffe en god beslutning om dette for bagud/fremad-kompatibilitet af transformation. Jeg vil sige, at mange forretningssucces også afhænger af, hvordan dette problem løses! Mange integrationsmareridt kan undgås, hvis dette gøres ordentligt.
Indtil videre har vi diskuteret et enkelt kildesystem, men for mange tilfælde er data fra andre systemer påkrævet for at udføre nogle transformationer som at konvertere bruger-id til navn, udledning af ny kolonneværdi, opslagskodning og mange flere. 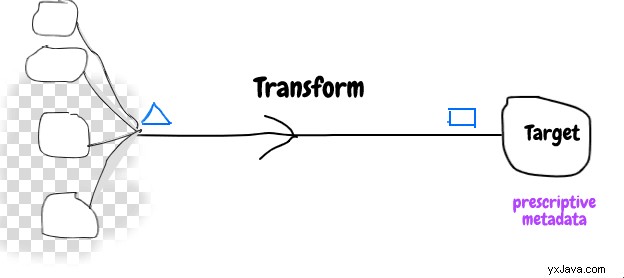
Tilføjelse af flere kildesystemer tilføjer kompleksitet i transformationen for at håndtere manglende data, forældede data og mange flere.
I takt med at datasystemer udvikler sig, så handler det ikke kun om relationslager i dag, vi ser nøgleværdilager , dokumentlager , graf db , kolonnelager , cache , logfiler osv.
Nye datasystemer distribueres også, så dette tilføjer endnu en dimension til transformationens kompleksitet.
Vores gamle relationsdatabaser kan også beskrives, da de er bygget ved hjælp af ETL-mønster ved at bruge ændringslog som kilde til alt, hvad databasen gør 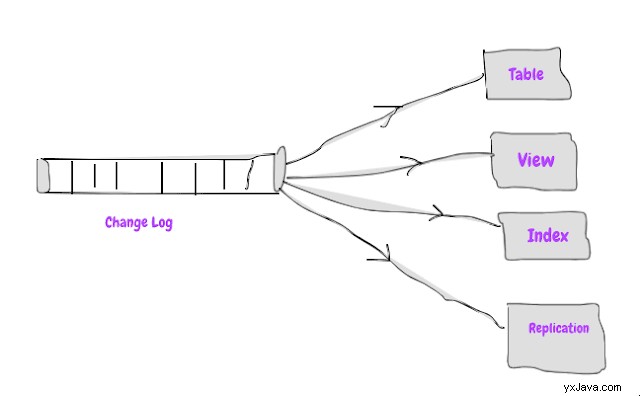
En af myten om ETL er, at det er batchproces, men det ændrer overarbejde med Stream-processor (dvs. Spark Streaming, Flink osv.) og Pub Sub-systemer (Kafka, Pulsur osv.). Dette gør det muligt at udføre transformation umiddelbart efter, at hændelsen er skubbet til kildesystemet.
Lad dig ikke rive med for meget af streaming buzzword, nej
uanset hvilken stream-processor eller pub-undersystem du bruger, men du skal stadig håndtere ovennævnte udfordringer eller udnytte nogle nye platforme til at tage sig af det.
Invester i transformation/forretningslogik, fordi det er nøglen til at bygge et succesfuldt system, der kan vedligeholdes og skaleres.
Holde det statsløst, metadatadrevet, håndtere duplikat/genforsøg osv., endnu vigtigere, skriv tests for at passe godt på det i hurtigt skiftende tid.
Næste gang, når du får nedenstående spørgsmål om din ETL-proces
Behandler du realtid eller batch?
Du skal svare
Det er hændelsesbaseret behandling.
Længe leve E T L