Apache Spark installationsvejledning
I dette indlæg præsenterer vi en omfattende Apache Spark-installationsvejledning.
1. Introduktion
Apache Spark er en open source-klyngecomputerramme med in-memory databehandlingsmotor. Det giver API i Java, Scala, R og Python. Apache Spark fungerer med HDFS og kan være op til 100 gange hurtigere end Hadoop Map-Reduce.
Det understøtter også andre værktøjer på højt niveau som Spark-SQL til struktureret databehandling, MLib til maskinlæring, GraphX til grafbehandling og Spark-streaming til kontinuerlig datastrømbehandling.
Nedenfor installationen er trinene for macOS. Selvom trin og egenskaber forbliver de samme for andre operativsystemer, kan kommandoer være forskellige, især for Windows.
2. Apache Spark Installation
2.1 Forudsætninger for Spark
2.1.1 Java-installation
Sørg for, at Java er installeret, før du installerer og kører Spark. Kør nedenstående kommando for at bekræfte, hvilken version af java der er installeret.
$ java -version
Hvis Java er installeret, vil det vise den installerede version af java.
java version "1.8.0_51" Java(TM) SE Runtime Environment (build 1.8.0_51-b16) Java HotSpot(TM) 64-Bit Server VM (build 25.51-b03, mixed mode)
Hvis ovenstående kommando ikke genkendes, skal du installere java fra Oracle Website, afhængigt af operativsystemet.
2.1.2 Scala-installation
Installation af Scala er obligatorisk før installation af Spark, da det er vigtigt for implementeringen. Tjek versionen af scala, hvis den allerede er installeret.
$scala -version
Hvis den er installeret, vil ovenstående kommando vise den installerede version.
Scala code runner version 2.13.1 -- Copyright 2002-2019, LAMP/EPFL and Lightbend, Inc.
Hvis den ikke er installeret, kan den installeres enten ved at installere IntelliJ og følge trinene som beskrevet her. Det kan også installeres ved at installere sbt eller Scala Built Tool ved at følge trinene som beskrevet her
Scala kan også installeres ved at downloade scala binære filer.
På macOS kan homebrew også bruges til at installere scala ved hjælp af nedenstående kommando,
brew install scala
2.1.3 Gnistinstallation
Download Apache Spark fra den officielle spark-side. Sørg for at downloade den seneste, stabile opbygning af gnist.
Det centrale maven-lager er også vært for et antal gnist-artefakter og kan tilføjes som en afhængighed i pom-filen.
PyPi kan bruges til at installere pySpark. Kør kommando pip install pyspark at installere.
Til dette eksempel har jeg downloadet Spark 2.4.0 og installeret det manuelt.
For at verificere, at gnisten er konfigureret korrekt, skal du køre under kommandoen fra spark HOME_DIRECTORY/bin,
$ ./spark-shell
2019-12-31 13:00:35 WARN NativeCodeLoader:62 - Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
Spark context Web UI available at http://192.168.10.110:4040
Spark context available as 'sc' (master = local[*], app id = local-1577777442575).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 2.4.0
/_/
Using Scala version 2.11.12 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_51)
Type in expressions to have them evaluated.
Type :help for more information.
scala>
3. Lancering af Spark Cluster
Der er flere muligheder for at implementere og køre Spark. Alle disse muligheder adskiller sig i, hvordan chauffører og arbejdere kører i gnist. Bare for at introducere vilkårene,
En driver er gnistens hovedproces. Det konverterer brugerprogrammerne til opgaver og tildeler disse opgaver til arbejdere.
En arbejder er gnistforekomsten, hvor eksekveren er bosat, og den udfører de opgaver, der er tildelt af chaufføren.
Vi vil diskutere dem i detaljer nedenfor.
- Klienttilstand
- Klyngetilstand
3.1 Klienttilstand
I klienttilstand kører drivere og arbejdere ikke kun på det samme system, men de bruger også den samme JVM. Dette er primært nyttigt under udvikling, når det klyngede miljø ikke er klar. Det gør også implementering og test af opgaverne hurtigere.
Spark kommer med en indbygget ressourcemanager, så mens vi kører i klienttilstand, kan vi bruge det samme for at undgå at køre flere processer.
En anden måde er at bruge YARN som ressourcemanager, hvilket vi vil se i detaljer, når vi taler om klyngetilstanden i Spark.
3.1.1 Standalone tilstand
Standalone-tilstand er en simpel klyngemanager sammen med Spark. Det gør det nemt at oprette en selvadministreret Spark-klynge.
Når gnisten er downloadet og udtrukket, skal du køre nedenstående kommando fra spark HOME_DIRECTORY/sbin for at starte masteren,
$ ./start-master.sh starting org.apache.spark.deploy.master.Master, logging to /Users/aashuaggarwal1/Softwares/spark-2.4.0-bin-hadoop2.7/logs/spark-aashuaggarwal1-org.apache.spark.deploy.master.Master-1-Aashus-MacBook-Pro.local.out
Ovenstående kommando vil starte spark master på localhost:8080, hvor spark-portalen kan tilgås i browseren. 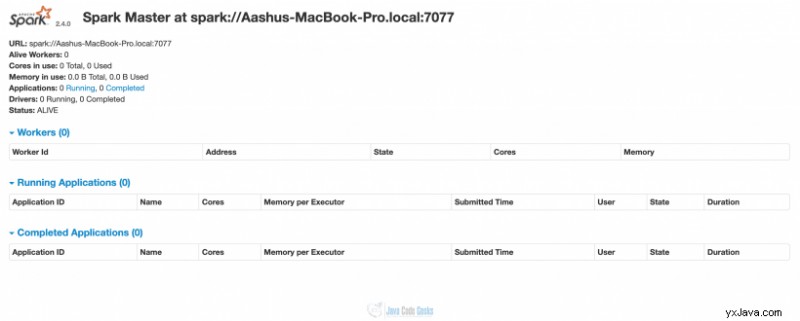
Her kan du se, at der stadig ikke løber nogen arbejdere. Så det er tid til at starte en arbejder. Hvis du ser i ovenstående billede, vises URL'en til sparkmasteren. Dette er den URL, vi vil bruge til at kortlægge allerede kørende master med slaven. Kør under kommandoen fra spark HOME_DIRECTORY/sbin,
$ ./start-slave.sh spark://Aashus-MacBook-Pro.local:7077 starting org.apache.spark.deploy.worker.Worker, logging to /Users/aashuaggarwal1/Softwares/spark-2.4.0-bin-hadoop2.7/logs/spark-aashuaggarwal1-org.apache.spark.deploy.worker.Worker-1-Aashus-MacBook-Pro.local.out
Hvis vi nu besøger localhost:8080, så vil vi se, at 1 arbejdertråd også er startet. Da vi ikke har angivet antallet af kerner og hukommelse eksplicit, har arbejderen optaget alle kernerne (8 i dette tilfælde) og hukommelsen (15 GB) til udførelsen af opgaver. 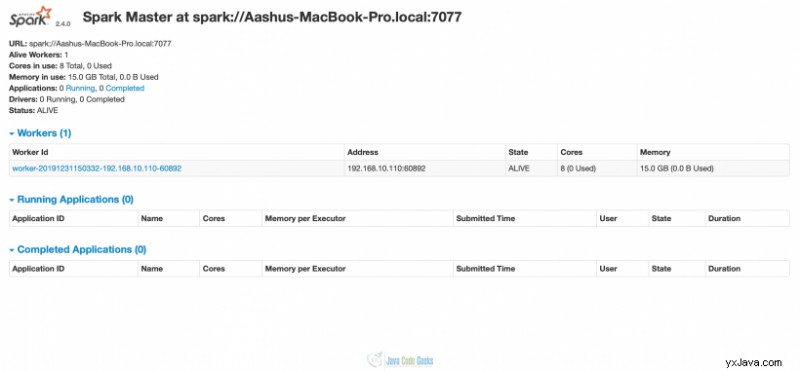
3.2 Klyngetilstand
Klienttilstand hjælper med udviklingen, hvor ændringer kan foretages og testes hurtigt på en lokal stationær eller bærbar computer. Men for at udnytte Sparks virkelige kraft skal den distribueres.
Her er den typiske infrastruktur for en Spark i produktion.
Mens standardressourceforhandler bundtet med Spark også kan bruges i klyngetilstand, men YARN (Yet Another Resource Negotiator) er det mest populære valg. Lad os se det i detaljer.
3.2.1 Hadoop YARN
YARN er en generisk ressourcestyringsramme for distribuerede arbejdsbelastninger. Det er en del af Hadoop-økosystemet, men det understøtter flere andre distribuerede computerrammer som Tez og Spark. 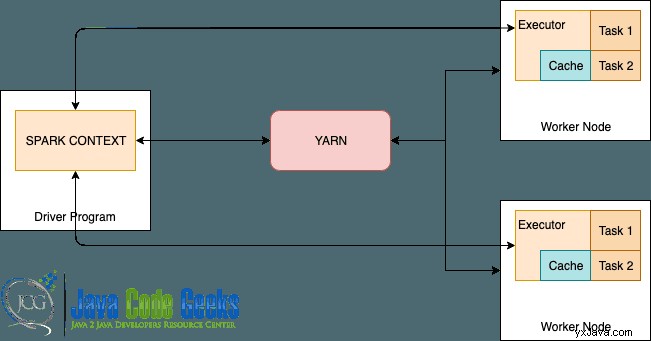
Som vi ser i ovenstående diagram, danner YARN og arbejdsknudepunkter databeregningsrammen.
YARN tager sig af ressourcevoldgift for alle applikationer i systemet, mens executor overvåger den individuelle maskinressourceforbrug og sender disse oplysninger tilbage til ressourceadministratoren.
Der er et par GARN-konfigurationer, som vi skal passe på,
arn.nodemanager.resource.memory-mb
yarn.nodemanager.resource.memory-mb – Det er mængden af fysisk hukommelse, i MB, der kan allokeres til containere i en node. Denne værdi skal være lavere end den tilgængelige hukommelse på noden.
yarn.scheduler.minimum-allocation-mb – Dette er den mindste hukommelse, som ressourceadministratoren skal allokere for hver ny anmodning om en container.
yarn.scheduler.maximum-allocation-mb – Maksimal hukommelse, der kan allokeres til en ny containeranmodning.
Nedenfor er et par gnistkonfigurationer ud fra synspunktet om at køre gnistjob i GARN.
spark.executor.memory – Da hver executor kører som en YARN container, er den bundet af Boxed Memory Axiom. Eksekutører vil bruge hukommelsesallokering svarende til summen af spark.executor.memory + spark.executor.memoryOverhead
spark.driver.memory – I klyngeimplementeringstilstand, da driveren kører i ApplicationMaster, som igen administreres af YARN, bestemmer denne egenskab, hvilken hukommelse der er tilgængelig for ApplicationMaster. Den tildelte hukommelse er lig med summen af spark.driver.memory + spark.driver.memoryOverhead .
4. Resumé
Denne artikel forklarer, hvordan man kører Apache spark i klient- og klyngetilstand ved hjælp af selvstændig og YARN-ressourcemanager. Der er andre ressourcemanagere som Apache Mesos og Kubernetes tilgængelige, som også kan udforskes.Apache Spark