Implementering af domænedrevet design
Implementering af domænedrevet design er en softwaredesign tilgang. Hvordan begynder du at designe noget software? Et komplekst problem kan være overvældende. Selvom du vil se på den eksisterende kodebase og finde ud af designet, kan det være meget arbejde. Mens du bygger, kan det distribuerede system blive komplekst. Dette indlæg er en del af Distributed System Design.
Den domænedrevne tilgang til softwareudvikling fungerer i sync med domæneeksperter. Normalt vil man diskutere problemet med domæneeksperter for at finde ud af, hvilke domæner og regler der kan oprettes, og hvordan de ændres i applikationen. Objektorienteret design er intet andet end domænedrevet design. Domæner er objekter. Uanset hvilket sprog du vælger, skal du oprette domæneobjekter.
Diskuterer med domæneeksperter
Et komplekst problem kræver en diskussion med domæneeksperter. Når du har samlet alle oplysninger om regler og betingelser, kan du begynde at repræsentere det virkelige problem i et domæneobjekt. Regler og betingelser kan hjælpe med at repræsentere domænet, og hvordan domænet vil interagere med andre domæneobjekter.
Det første trin er at vælge domænemodelnavne. Igen, dette afhænger af dit domæne.
Hvis vi skal tage et eksempel på et lokalt bibliotek, vil vi have domæneobjekter som Book , Author , User og Address . En bruger af biblioteket låner en bestemt forfatters bog fra biblioteket. Du kan selvfølgelig også tilføje Genre . Enten ville du tale med et lokalt bibliotek og se, hvad de har brug for for at bygge et online system til at spore deres bogbeholdning. Denne diskussion vil give dig en idé om, hvad din slutbruger ønsker, og hvordan brugeren ønsker at bruge systemet.
Grundlæggende byggeklodser
Når vi har nok information om domænet, opretter vi grundlæggende byggeklodser. Grunden til at starte med domænedrevet design som grundlæggende byggesten er, at denne del af designet er mindst foranderlig. I løbet af ansøgningens levetid vil dette ikke ændre sig. Derfor er det vigtigt at bygge dette så præcist som muligt.
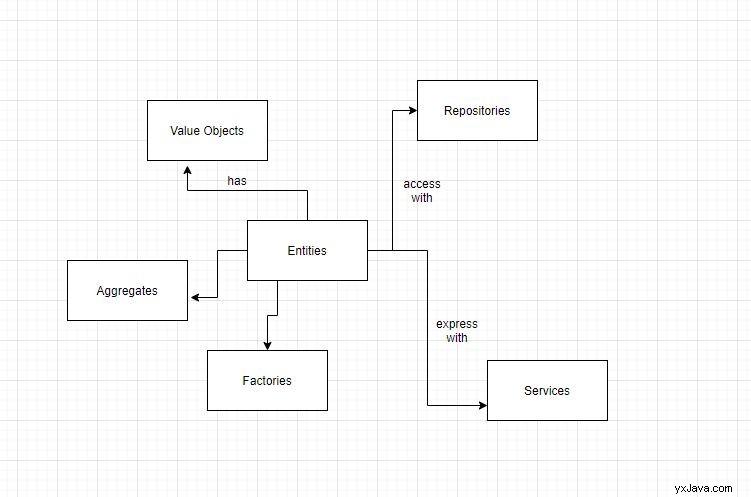
Enheder
Enheder er domæneobjekter. Vi identificerer disse domæneobjekter unikt. En generel måde at identificere disse objekter på er at oprette et felt id som kan være af typen UUID.
Som diskuteret i vores eksempel for opbygning af et online bibliotekssystem til at administrere bøger, Book , Author , Genre vil være forskellige enheder, og vi tilføjer et felt id i hver af disse enheder for at identificere dem entydigt.
public class Book
{
private UUID id;
private String title;
private String isbn;
private Date created;
private Date updated;
}
Værdiobjekter
Værdiobjekter er attributter eller egenskaber for enheder. Som ovenfor, hvor vi oprettede Book enhed, title , isbn er værdiobjekter for denne enhed.
Repositories
Ikke desto mindre er repositories et mellemlag mellem tjenester, der skal have adgang til domæneobjektdata fra persistensteknologierne som en database.
Aggregerede
Aggregater er en samling af enheder. Denne samling er bundet sammen af en rodentitet. Enheder inden for aggregater har en lokal identitet, men uden for denne grænse har de ingen identitet.
Tjenester
Tjenester driver det domænedrevne design. De er udføreren af hele systemet. Al din forretningslogik er afhængig af tjenester. Når du får en anmodning om at hente eller indsætte data, udfører tjenester validering af regler og data ved hjælp af entiteter, repositories og aggregater.
Fabrikker
Hvordan opretter du aggregater? Normalt giver fabrikker hjælp til at skabe aggregater. Hvis et aggregat er simpelt nok, kan man bruge aggregatets konstruktør til at skabe aggregat.
En af måderne at implementere fabrikker på er at bruge Factory Pattern. Vi kan også bruge et abstrakt fabriksmønster til at bygge hierarkier af klasser.
Afslutningsvis for at forstå alt dette
- Aggregater – er lavet af enheder.
- Aggregater – brug tjenester.
- Fabrikker – opret nye aggregater.
- Repositories – hentning, søgning, sletning af aggregater.
Forstå afgrænset kontekst i domænedrevet design
Den udfordrende del af ethvert design er, hvordan man sikrer sig, at vores indsats ikke overlappes. Hvis du opretter funktion A med bestemte domæner og en anden funktion B, der inkluderer en del af domæner fra funktion A, så duplikerer vi indsatsen. Derfor er det vigtigt at forstå den afgrænsede kontekst, når du designer din applikationsarkitektur. I sådanne tilfælde kan man sagtens bruge Liskov Substitution Principle.
Jo flere funktioner du tilføjer, jo mere komplekst bliver designet. Med stigende modeller er det endnu sværere at gætte, hvad du skal bruge i fremtiden. Overordnet set bygger du i sådanne scenarier en afgrænset kontekst. Den afgrænsede kontekst indeholder ikke-relaterede modeller, men deler også de fælles modeller. Dette hjælper med at opdele de komplekse og store modeller, som kan dele nogle modeller.
Konklusion
I dette indlæg lærte vi, hvordan man bruger domænedrevet design til at bygge et skalerbart system. Hvis du vil lære mere om dette emne, kan du få dette kursus om domænedrevet design.
Gode nyheder til læserne – et Black Friday-udsalg på min bog Simplifying Spring Security indtil 30. november. Køb den her.