Trin for trin Spring Batch Tutorial
I dette indlæg vil jeg vise, hvordan du kan bruge Spring Batch. Dette er et trin for trin forårsbatch-vejledning.
I virksomhedsapplikationer er batchbehandling almindelig. Men i takt med at data bliver mere udbredt på internettet, er det også blevet vigtigt, hvordan vi behandler disse data. Der findes flere løsninger. Apache Storm eller Apache Spark hjælper med at behandle og transformere dataene i det nødvendige format. I dette indlæg vil vi se nærmere på Spring Batch.
Hvad er Spring Batch?
Spring Batch er en letvægtsramme designet til at lette batchbehandling . Det giver udviklere mulighed for at oprette batch-applikationer. Til gengæld behandler disse batchapplikationer de indkommende data og transformerer dem til videre brug.
En anden stor fordel ved at bruge Spring Batch er, at det giver mulighed for højtydende behandling af disse data. De applikationer, der er stærkt afhængige af data, er det yderst vigtigt, at data bliver tilgængelige øjeblikkeligt.
Spring Batch giver en udvikler mulighed for at bruge POJO baseret tilgang. I denne tilgang kan en udvikler transformere de batchbehandlede data til datamodeller, som hun kan bruge yderligere til applikationsforretningslogik.
I dette indlæg vil jeg dække et eksempel, hvor vi vil batchbehandle en dataintensiv CSV-fil til medarbejderregistreringer og transformere og validere disse data for at indlæse i vores database.
Hvad er batchbehandling?
Batchbehandling er en databehandlingstilstand. Det involverer at forbruge alle data, behandle disse data, transformere dem og derefter sende dem til en anden datakilde. Normalt sker dette gennem et automatiseret job. Enten et udløsende system eller en bruger udløser et job, og det job behandler jobdefinitionen. Jobdefinition vil handle om at forbruge data fra dens kilde.
Den vigtigste fordel ved batchbehandling er, at den håndterer en stor mængde data. Ikke desto mindre kan denne operation være asynkron. De fleste applikationer udfører batchbehandling adskilt fra brugerinteraktion i realtid.
Dernæst vil vi lære om Spring Batch-rammen og hvad den omfatter.
Forår Batch Framework
Følgende arkitektur viser komponenterne i Spring Batch-rammeværket.
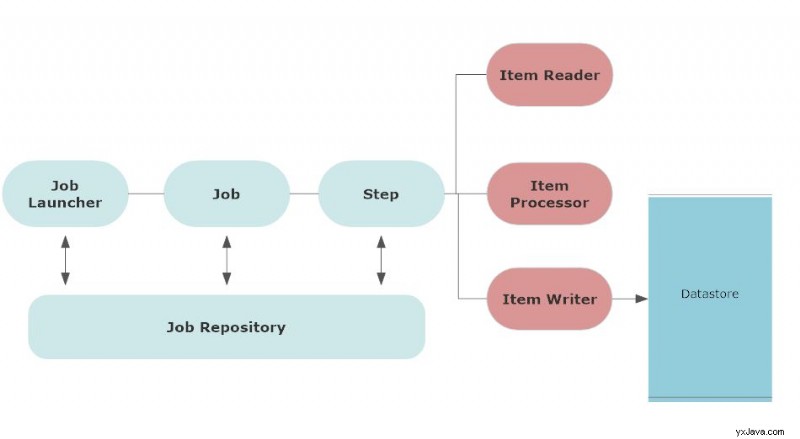
For det første involverer batchprocessen et job. Brugeren planlægger et job til at blive kørt på et bestemt tidspunkt eller baseret på en bestemt betingelse. Dette kan også involvere en jobudløser.
Spring Batch framework inkluderer også
- logning og sporing
- transaktionsstyring
- jobbehandlingsstatistik
- genstart af job
- ressourcestyring
Normalt, når du konfigurerer et job, gemmes det i jobopbevaringsstedet. Joblager opbevarer metadataoplysningerne for alle jobs. En trigger starter disse job på deres planlagte tidspunkt.
Enjobstarter er en grænseflade til at starte et job eller kører et job, når jobbets planlagte tid ankommer.
Job er defineret med jobparametre. Når et job starter, kører en jobinstans for det job. Hver udførelse af jobforekomst har jobudførelse, og den holder styr på jobbets status. Et job kan have flere trin.
Trin er en selvstændig fase af et job. Et job kan bestå af mere end ét trin. I lighed med jobbet har hvert trin trinudførelse, der udfører trinnet og holder styr på trinnets status.
Hvert trin har en varelæser som grundlæggende læser inputdataene, envarebehandler der behandler dataene og transformerer dem, og enemneskriver der tager de behandlede data og udlæser dem.
Lad os nu se alle disse komponenter i vores demo.
Trin for trin Spring Batch Tutorial med et eksempel
Som en del af demoen vil vi uploade en csv-fil gennem Spring Batch Framework. Så til at starte med skal du oprette forårsprojektet og tilføje følgende afhængighed:
implementation 'org.springframework.boot:spring-boot-starter-batch'
Dette er hovedafhængigheden af vores projekt. Vores hovedapplikation vil også se ud som nedenfor:
package com.betterjavacode.springbatchdemo;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
public class SpringbatchdemoApplication
{
public static void main(String[] args)
{
SpringApplication.run(SpringbatchdemoApplication.class, args);
}
}
Opret DTO-objekt
Jeg vil uploade medarbejderdata gennem en CSV-fil, så jeg får oprettet mit DTO-objekt for medarbejder som nedenfor:
package com.betterjavacode.springbatchdemo.dtos;
import com.betterjavacode.springbatchdemo.models.Company;
import com.betterjavacode.springbatchdemo.models.Employee;
import com.betterjavacode.springbatchdemo.repositories.CompanyRepository;
import org.springframework.beans.factory.annotation.Autowired;
import java.io.Serializable;
public class EmployeeDto implements Serializable
{
private static final long serialVersionUID = 710566148641281929L;
@Autowired
public CompanyRepository companyRepository;
private int employeeId;
private int companyId;
private String firstName;
private String lastName;
private String email;
private String jobTitle;
public EmployeeDto()
{
}
public EmployeeDto(int employeeId, String firstName, String lastName, String email,
String jobTitle, int companyId)
{
this.employeeId = employeeId;
this.firstName = firstName;
this.lastName = lastName;
this.email = email;
this.jobTitle = jobTitle;
this.companyId = companyId;
}
public Employee employeeDtoToEmployee()
{
Employee employee = new Employee();
employee.setEmployeeId(this.employeeId);
employee.setFirstName(this.firstName);
employee.setLastName(this.lastName);
employee.setEmail(this.email);
Company company = companyRepository.findById(this.companyId).get();
employee.setCompany(company);
employee.setJobTitle(this.jobTitle);
return employee;
}
public int getEmployeeId ()
{
return employeeId;
}
public void setEmployeeId (int employeeId)
{
this.employeeId = employeeId;
}
public int getCompanyId ()
{
return companyId;
}
public void setCompanyId (int companyId)
{
this.companyId = companyId;
}
public String getFirstName ()
{
return firstName;
}
public void setFirstName (String firstName)
{
this.firstName = firstName;
}
public String getLastName ()
{
return lastName;
}
public void setLastName (String lastName)
{
this.lastName = lastName;
}
public String getEmail ()
{
return email;
}
public void setEmail (String email)
{
this.email = email;
}
public String getJobTitle ()
{
return jobTitle;
}
public void setJobTitle (String jobTitle)
{
this.jobTitle = jobTitle;
}
}
Denne DTO-klasse bruger også et lager CompanyRepository at hente et firmaobjekt og konvertere DTO til et databaseobjekt.
Opsætning af Spring Batch Configuration
Nu vil vi konfigurere en batch-konfiguration for vores job, der kører for at uploade en CSV-fil til databasen. Vores klasse BatchConfig indeholde en annotation @EnableBatchProcessing . Denne annotation aktiverer Spring Batch-funktioner og giver en basiskonfiguration til at konfigurere batchjob i en @Configuration klasse.
@Configuration
@EnableBatchProcessing
public class BatchConfig
{
}
Denne batchkonfiguration vil inkludere en definition af vores job, trin involveret i jobbet. Det vil også indeholde, hvordan vi vil læse vores fildata og behandle dem yderligere.
@Bean
public Job processJob(Step step)
{
return jobBuilderFactory.get("processJob")
.incrementer(new RunIdIncrementer())
.listener(listener())
.flow(step).end().build();
}
@Bean
public Step orderStep1(JdbcBatchItemWriter writer)
{
return stepBuilderFactory.get("orderStep1").<EmployeeDto, EmployeeDto> chunk(10)
.reader(flatFileItemReader())
.processor(employeeItemProcessor())
.writer(writer).build();
}
Above bean erklærer jobbet processJob . incrementer tilføjer jobparametre. listener vil lytte til jobbet og håndtere jobstatus. Bønnen for listener vil håndtere jobafslutning eller jobfejlmeddelelse. Som diskuteret i Spring Batch-arkitekturen omfatter hvert job mere end ét trin.
@Bean for trin bruger stepBuilderFactory at skabe et trin. Dette trin behandler en del af data i en størrelse på 10. Det har en flad fillæser flatFileItemReader() . En processor employeeItemReader vil behandle de data, der er blevet læst af Flat File Item Reader.
@Bean
public FlatFileItemReader flatFileItemReader()
{
return new FlatFileItemReaderBuilder()
.name("flatFileItemReader")
.resource(new ClassPathResource("input/employeedata.csv"))
.delimited()
.names(format)
.linesToSkip(1)
.lineMapper(lineMapper())
.fieldSetMapper(new BeanWrapperFieldSetMapper(){{
setTargetType(EmployeeDto.class);
}})
.build();
}
@Bean
public LineMapper lineMapper()
{
final DefaultLineMapper defaultLineMapper = new DefaultLineMapper<>();
final DelimitedLineTokenizer delimitedLineTokenizer = new DelimitedLineTokenizer();
delimitedLineTokenizer.setDelimiter(",");
delimitedLineTokenizer.setStrict(false);
delimitedLineTokenizer.setNames(format);
defaultLineMapper.setLineTokenizer(delimitedLineTokenizer);
defaultLineMapper.setFieldSetMapper(employeeDtoFieldSetMapper);
return defaultLineMapper;
}
@Bean
public EmployeeItemProcessor employeeItemProcessor()
{
return new EmployeeItemProcessor();
}
@Bean
public JobExecutionListener listener()
{
return new JobCompletionListener();
}
@Bean
public JdbcBatchItemWriter writer(final DataSource dataSource)
{
return new JdbcBatchItemWriterBuilder()
.itemSqlParameterSourceProvider(new BeanPropertyItemSqlParameterSourceProvider<>())
.sql("INSERT INTO employee(employeeId, firstName, lastName, jobTitle, email, " +
"companyId) VALUES(:employeeId, :firstName, :lastName, :jobTitle, :email," +
" " +
":companyId)")
.dataSource(dataSource)
.build();
}
Vi vil tage et kig på hver af disse bønner nu.
FlatFileItemReader vil læse dataene fra den flade fil. Vi bruger en FlatFileItemReaderBuilder til at oprette en FlatFileItemReader af typen EmployeeDto .
resource angiver placeringen af filen.
delimited – Dette bygger en afgrænset tokenizer.
names – vil vise rækkefølgen af felter i filen.
lineMapper er en grænseflade til at kortlægge linjer fra fil til domæneobjekt.
fieldSetMapper vil kortlægge data fra feltsæt til et objekt.
lineMapper bean har brug for tokenizer og fieldsetmapper.
employeeDtoFieldSetMapper er en anden bean, som vi har autowired i denne klasse.
package com.betterjavacode.springbatchdemo.configurations.processor;
import com.betterjavacode.springbatchdemo.dtos.EmployeeDto;
import org.springframework.batch.item.file.mapping.FieldSetMapper;
import org.springframework.batch.item.file.transform.FieldSet;
import org.springframework.stereotype.Component;
import org.springframework.validation.BindException;
@Component
public class EmployeeDtoFieldSetMapper implements FieldSetMapper
{
@Override
public EmployeeDto mapFieldSet (FieldSet fieldSet) throws BindException
{
int employeeId = fieldSet.readInt("employeeId");
String firstName = fieldSet.readRawString("firstName");
String lastName = fieldSet.readRawString("lastName");
String jobTitle = fieldSet.readRawString("jobTitle");
String email = fieldSet.readRawString("email");
int companyId = fieldSet.readInt("companyId");
return new EmployeeDto(employeeId, firstName, lastName, jobTitle, email, companyId);
}
}
Som du kan se, kortlægger denne FieldSetMapper felter til individuelle objekter for at skabe en EmployeeDto .
EmployeeItemProcessor implementerer grænsefladen ItemProcessor . Grundlæggende i denne klasse validerer vi EmployeeDto data for at verificere, om virksomheden, medarbejderen tilhører, eksisterer.
JobCompletionListener kontrollerer status for fuldførelse af job.
@Override
public void afterJob(JobExecution jobExecution)
{
if (jobExecution.getStatus() == BatchStatus.COMPLETED)
{
// Log statement
System.out.println("BATCH JOB COMPLETED SUCCESSFULLY");
}
}
Lad os nu se på ItemWriter . Denne bønne bruger grundlæggende JdbcBatchItemWriter . JdbcBatchItemWriter bruger INSERT sql-sætning for at indsætte behandlet EmployeeDto data ind i den konfigurerede datakilde.
Konfiguration af programegenskaber
Før vi kører vores applikation til at behandle en fil, lad os se på application.properties .
spring.datasource.url=jdbc:mysql://127.0.0.1/springbatchdemo?autoReconnect=true&useSSL=false
spring.datasource.username = root
spring.datasource.password=*******
spring.datasource.driver-class-name=com.mysql.cj.jdbc.Driver
spring.jpa.show-sql=true
spring.jpa.properties.hibernate.dialect = org.hibernate.dialect.MySQL5Dialect
spring.datasource.hikari.connection-test-query=SELECT 1
spring.batch.initialize-schema=ALWAYS
Ud over almindelige datakildeegenskaber bør vi forstå egenskaben spring.batch.initialize-schema=ALWAYS . Hvis vi ikke bruger denne ejendom og starter applikationen, klager applikationen Table batch_job_instance doesn't exist .
For at undgå denne fejl beder vi grundlæggende om at oprette batchjob-relaterede metadata under opstart. Denne egenskab vil oprette yderligere databasetabeller i din database som batch_job_execution , batch_job_execution_context , batch_job_execution_params , batch_job_instance osv.
Demo
Hvis jeg nu udfører min Spring Boot Application, vil den køre og udføre jobbet. Der er forskellige måder at udløse et job på. I en virksomhedsapplikation vil du modtage en fil eller data på en slags lagerplads (S3 eller Amazon SNS-SQS), og du vil have et job, der vil overvåge denne placering for at udløse filindlæsningen Spring Batch-job.
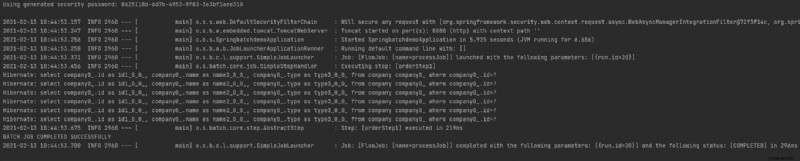
Du kan i udførelsen se en meddelelse om jobafslutning – "BATCHJOB SUCCES FULDFØRT “. Hvis vi tjekker vores databasetabel, vil vi se dataene indlæst.
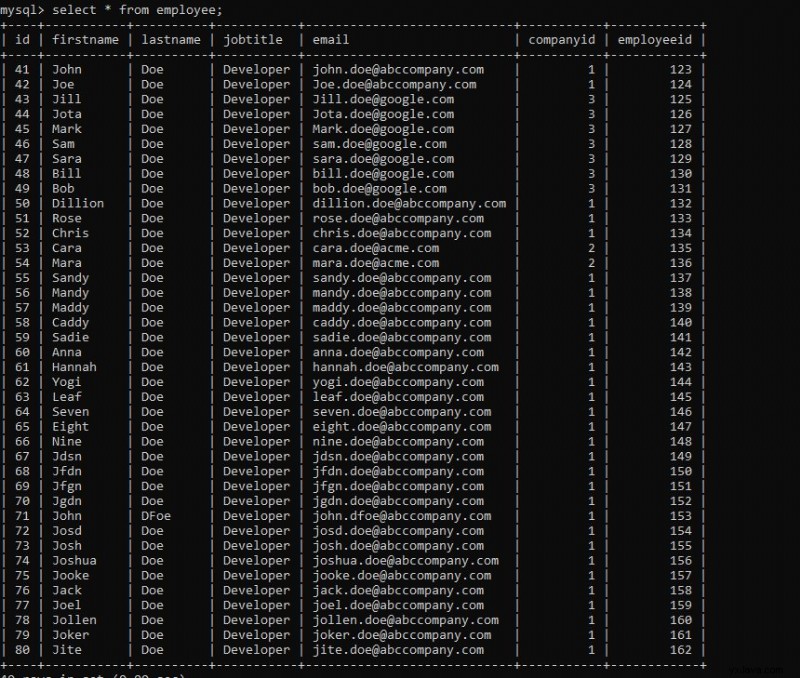
Du kan downloade koden til denne demo fra mit github-lager.
Hvad mere?
Jeg har dækket en Spring Batch tutorial her, men dette er ikke alt. Der er mere til Spring Batch end denne indledende del. Du kan have forskellige inputdatakilder, eller du kan også indlæse dataene fra fil til fil med forskellige databehandlingsregler.
Der er også måder at automatisere disse job og behandle en stor mængde data på en effektiv måde.
Konklusion
I dette indlæg viste jeg et trin for trin Spring Batch Tutorial. Der er mange måder at håndtere batchjobs på, men Spring Batch har gjort dette meget nemt.
I andre nyheder har jeg for nylig udgivet min nye bog – Simplifying Spring Security. Hvis du ønsker at lære om Spring Security, kan du købe bogen her. Ledsager denne bog med dette indlæg med spørgsmål om Spring Boot Interview, og du vil være klar til din næste jobsamtale.