En komplet guide til brug af ElasticSearch med fjederstøvle
I dette indlæg vil jeg dække detaljerne om, hvordan man bruger Elasticsearch med Spring Boot. Jeg vil også dække det grundlæggende i Elasticsearch, og hvordan det bruges i industrien.
Hvad er Elasticsearch?
Elasticsearch er en distribueret, gratis og åben søge- og analysemaskine til alle typer data, inklusive tekstuelle, numeriske, geospatiale, strukturerede og ustrukturerede.
Det er bygget på Apache Lucene. Elasticsearch er ofte en del af ELK-stakken (Elastic, LogStash og Kibana). Man kan bruge Elasticsearch til at gemme, søge og administrere data for
- Logfiler
- Metrics
- En søgebackend
- Applikationsovervågning
Søgning er blevet en central idé på mange felter med stadigt stigende data. Da de fleste applikationer bliver dataintensive, er det vigtigt at søge gennem en stor mængde data med hastighed og fleksibilitet. ElasticSearch tilbyder begge dele.
I dette indlæg vil vi se på Spring Data Elasticsearch. Det giver en enkel grænseflade til at søge, gemme og køre analyseoperationer. Vi vil vise, hvordan vi kan bruge Spring Data til at indeksere og søge logdata.
Nøglebegreber for Elasticsearch
Elasticsearch har indekser, dokumenter og felter. Ideen er enkel og ligner meget databaser. Elasticsearch gemmer data som dokumenter (Rækker) i indekser (Databasetabeller). En bruger kan søge gennem disse data ved hjælp af felter (Kolonner).
Normalt går dataene i elasticsearch gennem forskellige analysatorer for at opdele disse data. Standardanalysatoren opdeler dataene efter tegnsætning som mellemrum eller komma.
Vi bruger spring-data-elasticsearch bibliotek for at bygge demoen af dette indlæg. I Spring Data er et dokument intet andet end et POJO-objekt. Vi tilføjer forskellige annoteringer fra elasticsearch i samme klasse.
Som tidligere nævnt kan elasticsearch gemme forskellige typer data. Ikke desto mindre vil vi se på de simple tekstdata i denne demo.
Oprettelse af Spring Boot Application
Lad os skabe en simpel fjederstøvleapplikation. Vi vil bruge spring-data-elasticsearch afhængighed.
dependencies {
implementation 'org.springframework.boot:spring-boot-starter-data-elasticsearch'
implementation 'org.springframework.boot:spring-boot-starter-thymeleaf'
implementation 'org.springframework.boot:spring-boot-starter-web'
testImplementation 'org.springframework.boot:spring-boot-starter-test'
}
Efterfølgende skal vi oprette Elasticsearch-klientbean. Nu er der to måder at skabe denne bønne på.
Den enkle metode til at tilføje denne bønne er ved at tilføje egenskaberne i application.properties .
spring.elasticsearch.rest.uris=localhost:9200
spring.elasticsearch.rest.connection-timeout=1s
spring.elasticsearch.rest.read-timeout=1m
spring.elasticsearch.rest.password=
spring.elasticsearch.rest.username=
Men i vores ansøgning vil vi bygge denne bønne programmatisk. Vi vil bruge Java High-Level Rest Client (JHLC). JHLC er en standardklient for elasticsearch.
@Configuration
@EnableElasticsearchRepositories
public class ElasticsearchClientConfiguration extends AbstractElasticsearchConfiguration
{
@Override
@Bean
public RestHighLevelClient elasticsearchClient ()
{
final ClientConfiguration clientConfiguration =
ClientConfiguration.builder().connectedTo("localhost:9200").build();
return RestClients.create(clientConfiguration).rest();
}
}
Fremover har vi en klientkonfiguration, der også kan bruge egenskaber fra application.properties . Vi bruger RestClients for at oprette elasticsearchClient .
Derudover vil vi bruge LogData som vores model. Grundlæggende vil vi bygge et dokument til LogData at gemme i et indeks.
@Document(indexName = "logdataindex")
public class LogData
{
@Id
private String id;
@Field(type = FieldType.Text, name = "host")
private String host;
@Field(type = FieldType.Date, name = "date")
private Date date;
@Field(type = FieldType.Text, name = "message")
private String message;
@Field(type = FieldType.Double, name = "size")
private double size;
@Field(type = FieldType.Text, name = "status")
private String status;
// Getters and Setters
}
@Document– angiver vores indeks.@Id– repræsenterer feltet _id i vores dokument, og det er unikt for hver besked.@Field– repræsenterer en anden type felt, der kan være i vores data.
Der er to måder, man kan søge på eller oprette et indeks med elasticsearch –
- Brug af Spring Data Repository
- Brug af ElasticsearchRestTemplate
Forår Data Repository med Elasticsearch
Samlet set giver Spring Data Repository os mulighed for at oprette repositories, som vi kan bruge til at skrive simple CRUD-metoder til søgning eller indeksering i elasticsearch. Men hvis du ønsker mere kontrol over forespørgslerne, vil du måske bruge ElasticsearchRestTemplate . Især giver det dig mulighed for at skrive mere effektive forespørgsler.
public interface LogDataRepository extends ElasticsearchRepository<LogData, String>
{
}
Dette lager giver grundlæggende CRUD-metoder, som Spring tager sig af fra et implementeringsperspektiv.
Brug af ElasticsearchRestTemplate
Hvis vi vil bruge avancerede forespørgsler som aggregering, forslag, kan vi bruge ElasticsearchRestTemplate . Spring Data-biblioteket leverer denne skabelon.
public List getLogDatasByHost(String host) {
Query query = new NativeSearchQueryBuilder()
.withQuery(QueryBuilders.matchQuery("host", host))
.build();
SearchHits searchHits = elasticsearchRestTemplate.search(query, LogData.class);
return searchHits.get().map(SearchHit::getContent).collect(Collectors.toList());
}
Jeg vil yderligere vise brugen af ElasticsearchRestTemplate når vi laver mere komplekse forespørgsler.
ElasticsearchRestTemplate implementerer ElasticsearchOperations . Der er nøgleforespørgsler, som du kan bruge med ElasticsearchRestTemplate der gør brugen af den nemmere sammenlignet med Spring Data repositories.
index() ELLER bulkIndex() tillade oprettelse af et enkelt indeks eller indekser i bulk. Man kan bygge et indeksforespørgselsobjekt og bruge det i index() metodekald.
private ElasticsearchRestTemplate elasticsearchRestTemplate;
public List createLogData
(final List logDataList) {
List queries = logDataList.stream()
.map(logData ->
new IndexQueryBuilder()
.withId(logData.getId().toString())
.withObject(logData).build())
.collect(Collectors.toList());;
return elasticsearchRestTemplate.bulkIndex(queries,IndexCoordinates.of("logdataindex"));
}
search() metode hjælper med at søge i dokumenter i et indeks. Man kan udføre søgeoperationer ved at bygge Query objekt. Der er tre typer Query man kan bygge. NativeQuery , CriteriaQuery og StringQuery .
Hvil controlleren til at forespørge på elasticsearch-instansen
Lad os oprette en hvilecontroller, som vi vil bruge til at tilføje hovedparten af data i vores elasticsearch-forekomst samt til at forespørge den samme forekomst.
@RestController
@RequestMapping("/v1/betterjavacode/logdata")
public class LogDataController
{
@Autowired
private LogDataService logDataService;
@GetMapping
public List searchLogDataByHost(@RequestParam("host") String host)
{
List logDataList = logDataService.getAllLogDataForHost(host);
return logDataList;
}
@GetMapping("/search")
public List searchLogDataByTerm(@RequestParam("term") String term)
{
return logDataService.findBySearchTerm(term);
}
@PostMapping
public LogData addLogData(@RequestBody LogData logData)
{
return logDataService.createLogDataIndex(logData);
}
@PostMapping("/createInBulk")
public List addLogDataInBulk(@RequestBody List logDataList)
{
return (List) logDataService.createLogDataIndices(logDataList);
}
}
Kører Elasticsearch-instans
Indtil videre har vi vist, hvordan man opretter et indeks, og hvordan man bruger elasticsearch-klienten. Men vi har ikke vist at forbinde denne klient med vores elasticsearch-instans.
Vi vil bruge en docker-instans til at køre elasticsearch på vores lokale miljø. AWS leverer sin egen tjeneste til at køre Elasticsearch.
For at køre din egen docker-instans af elasticsearch skal du bruge følgende kommando –
docker run -p 9200:9200 -e "discovery.type=single-node" docker.elastic.co/elasticsearch/elasticsearch:7.10.0
Efterfølgende vil dette starte node elasticsearch node, som du kan verificere ved at besøge http://localhost:9200
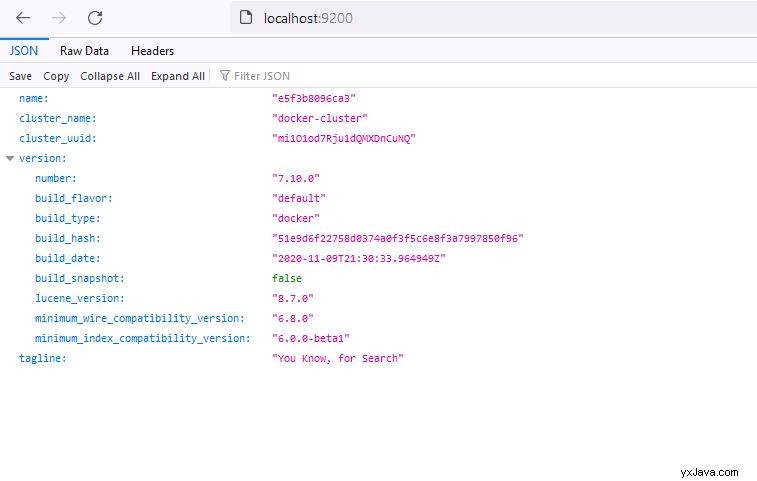
Oprettelse af indeks og søgning efter data
Alt i alt, hvis vi starter applikationen, vil vi bruge et postbud til at oprette et indledende indeks og fortsætte med at tilføje dokumenter til det.
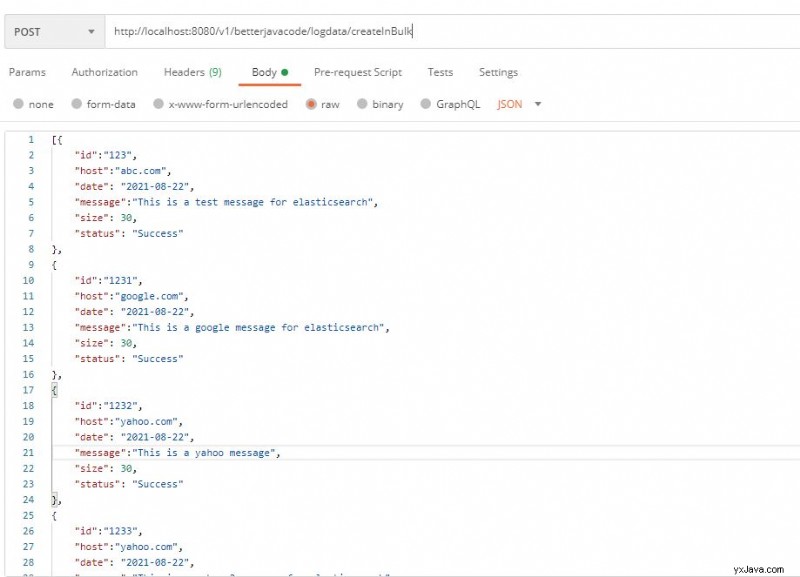
Dette vil også oprette et indeks og tilføje dokumenterne til det indeks. På elasticsearch-forekomsten kan vi se loggen som nedenfor:
{
"type": "server",
"timestamp": "2021-08-22T18:48:46,579Z",
"level": "INFO",
"component": "o.e.c.m.MetadataCreateIndexService",
"cluster.name": "docker-cluster",
"node.name": "e5f3b8096ca3",
"message": "[logdataindex] creating index, cause [api], templates [], shards [1]/[1]",
"cluster.uuid": "mi1O1od7Rju1dQMXDnCuNQ",
"node.id": "PErAmAWPRiCS5tv-O7HERw"
}
Meddelelsen viser tydeligt, at den har oprettet et indeks logdataindex . Hvis nu tilføjer flere dokumenter til det samme indeks, vil det opdatere det indeks.
Lad os køre en søgeforespørgsel nu. Jeg vil køre en simpel forespørgsel for at søge efter tekstudtrykket "Google"
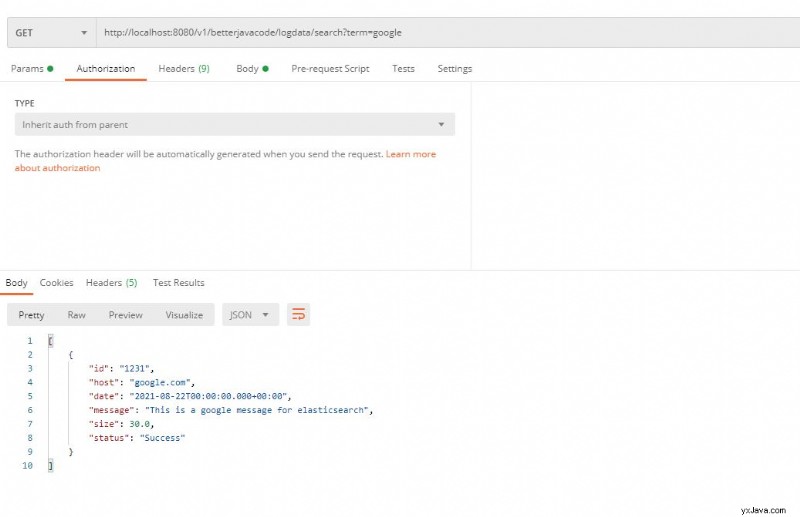
Dette var en simpel søgeforespørgsel. Som tidligere nævnt kan vi skrive mere komplekse søgeforespørgsler ved hjælp af forskellige typer forespørgsler – String, Criteria eller Native.
Konklusion
Kode til denne demo er tilgængelig på mit GitHub-lager.
I dette indlæg dækkede vi følgende ting
- Elasticsearch og nøglebegreber om Elasticsearch
- Forårsdatalager og ElasticsearchRestTemplate
- Integration med Spring Boot Application
- Udførelse af forskellige forespørgsler mod Elasticsearch
Hvis du ikke har tjekket min bog om Spring Security ud, kan du tjekke her.
Synes du Gradle som byggeværktøj er forvirrende? Hvorfor er det så komplekst at forstå? Jeg er ved at skrive en ny simpel bog om Gradle – Gradle For Humans. Følg mig her for flere opdateringer.