Vejledning til ByteBuffer
1. Oversigt
Bufferen klasser er grundlaget, som Java NIO er bygget på. Men i disse klasser er ByteBuffer klasse er mest foretrukket. Det er fordi byten typen er den mest alsidige. For eksempel kan vi bruge bytes til at komponere andre ikke-booleske primitive typer i JVM. Vi kan også bruge bytes til at overføre data mellem JVM og eksterne I/O-enheder.
I denne øvelse vil vi inspicere forskellige aspekter af ByteBuffer klasse.
2. ByteBuffer Oprettelse
ByteBuffer er en abstrakt klasse, så vi kan ikke konstruere en ny instans direkte. Det giver dog statiske fabriksmetoder for at lette oprettelse af instanser. Kort fortalt er der to måder at oprette en ByteBuffer på forekomst, enten ved tildeling eller indpakning:
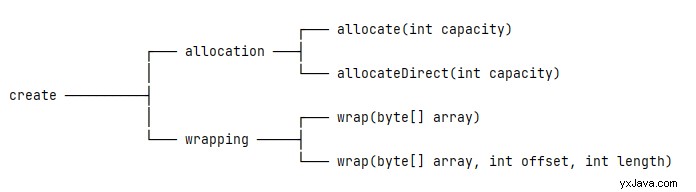
2.1. Tildeling
Allokering vil oprette en instans og tildele privat plads med en specifik kapacitet . For at være præcis, ByteBuffer klasse har to allokeringsmetoder:allokér og allocateDirect .
Brug af allokér metode, får vi en ikke-direkte buffer – det vil sige en bufferforekomst med en underliggende byte array:
ByteBuffer buffer = ByteBuffer.allocate(10);Når vi bruger allocateDirect metode, vil den generere en direkte buffer:
ByteBuffer buffer = ByteBuffer.allocateDirect(10);For nemheds skyld, lad os fokusere på den ikke-direkte buffer og lade diskussionen om direkte buffer ligge til senere.
2.2. Indpakning
Indpakning tillader en instans at genbruge en eksisterende byte array:
byte[] bytes = new byte[10];
ByteBuffer buffer = ByteBuffer.wrap(bytes);Og ovenstående kode svarer til:
ByteBuffer buffer = ByteBuffer.wrap(bytes, 0, bytes.length);Eventuelle ændringer af dataelementerne i den eksisterende byte array vil blive afspejlet i bufferforekomsten og omvendt.
2.3. Løgmodel
Nu ved vi, hvordan man får en ByteBuffer eksempel. Lad os derefter behandle ByteBuffer klasse som en tre-lags løgmodel og forstå det lag for lag indefra og ud:
- Data- og indekslag
- Overførsel af datalag
- Se lag
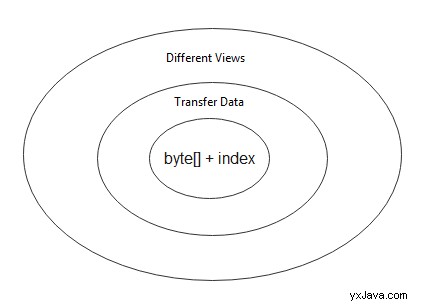
I det inderste lag betragter vi ByteBuffer klasse som en beholder for en byte array med ekstra indekser. I mellemlaget fokuserer vi på at bruge en ByteBuffer instans til at overføre data fra/til andre datatyper. Vi inspicerer de samme underliggende data med forskellige bufferbaserede visninger i det yderste lag.
3. ByteBuffer Indeks
Konceptuelt er ByteBuffer klasse er en byte array pakket inde i et objekt. Det giver masser af praktiske metoder til at lette læsning eller skriveoperationer fra/til underliggende data. Og disse metoder er meget afhængige af de vedligeholdte indekser.
Lad os nu bevidst forenkle ByteBuffer klasse ind i en beholder med byte array med ekstra indekser:
ByteBuffer = byte array + indexMed dette koncept i tankerne kan vi klassificere indeks-relaterede metoder i fire kategorier:
- Grundlæggende
- Marker og nulstil
- Ryd, vend, spole tilbage og komprimer
- Forbliv

3.1. Fire grundlæggende indekser
Der er fire indekser defineret i bufferen klasse. Disse indekser registrerer tilstanden af de underliggende dataelementer:
- Kapacitet:det maksimale antal dataelementer, bufferen kan indeholde
- Grænse:et indeks til at stoppe læsning eller skrivning
- Position:det aktuelle indeks, der skal læses eller skrives
- Mærk:en husket position
Der er også et invariant forhold mellem disse indekser:
0 <= mark <= position <= limit <= capacityOg vi bør bemærke, at alle indeks-relaterede metoder kredser om disse fire indekser .
Når vi opretter en ny ByteBuffer forekomst, mærket er udefineret, positionen holder 0 og grænsen er lig med kapaciteten . Lad os f.eks. allokere en ByteBuffer med 10 dataelementer:
ByteBuffer buffer = ByteBuffer.allocate(10);Eller lad os indpakke et eksisterende byte-array med 10 dataelementer:
byte[] bytes = new byte[10];
ByteBuffer buffer = ByteBuffer.wrap(bytes);Som følge heraf er mærket vil være -1, positionen vil være 0, og både grænsen og kapacitet vil være 10:
int position = buffer.position(); // 0
int limit = buffer.limit(); // 10
int capacity = buffer.capacity(); // 10kapaciteten er skrivebeskyttet og kan ikke ændres. Men vi kan bruge position(int) og limit(int) metoder til at ændre den tilsvarende position og grænse :
buffer.position(2);
buffer.limit(5);Derefter positionen vil være 2, og grænsen bliver 5.
3.2. Marker og nulstil
mark() og reset() metoder giver os mulighed for at huske en bestemt position og vende tilbage til den senere.
Når vi første gang opretter en ByteBuffer forekomst, mærket er udefineret. Derefter kan vi kalde mark() metode og mærket er indstillet til den aktuelle position. Efter nogle handlinger, kalder du reset() metoden ændrer positionen tilbage til mærket .
ByteBuffer buffer = ByteBuffer.allocate(10); // mark = -1, position = 0
buffer.position(2); // mark = -1, position = 2
buffer.mark(); // mark = 2, position = 2
buffer.position(5); // mark = 2, position = 5
buffer.reset(); // mark = 2, position = 2Én ting at bemærke:Hvis mærket er udefineret, kalder reset() metode vil føre til InvalidMarkException .
3.3. Ryd, vend, spole tilbage og komprimer
clear() , flip() , spol tilbage() , og compact() metoder har nogle fælles dele og små forskelle:
For at sammenligne disse metoder, lad os forberede et kodestykke:
ByteBuffer buffer = ByteBuffer.allocate(10); // mark = -1, position = 0, limit = 10
buffer.position(2); // mark = -1, position = 2, limit = 10
buffer.mark(); // mark = 2, position = 2, limit = 10
buffer.position(5); // mark = 2, position = 5, limit = 10
buffer.limit(8); // mark = 2, position = 5, limit = 8clear() metoden ændrer grænsen til kapaciteten , positionen til 0, og mærket til -1:
buffer.clear(); // mark = -1, position = 0, limit = 10flip() metoden ændrer grænsen til positionen , positionen til 0, og mærket til -1:
buffer.flip(); // mark = -1, position = 0, limit = 5rewind() metoden beholder grænsen uændret og ændrer positionen til 0, og mærket til -1:
buffer.rewind(); // mark = -1, position = 0, limit = 8compact() metoden ændrer grænsen til kapaciteten , positionen til resterende (grænse – position ), og mærket til -1:
buffer.compact(); // mark = -1, position = 3, limit = 10Ovenstående fire metoder har deres egne use cases:
- For at genbruge en buffer skal du bruge clear() metoden er praktisk. Det vil sætte indeksene til den oprindelige tilstand og være klar til nye skriveoperationer.
- Efter at have kaldt flip() metoden skifter bufferforekomsten fra skrivetilstand til læsetilstand. Men vi bør undgå at kalde flip() metode to gange. Det er fordi et andet opkald vil sætte grænsen til 0, og ingen dataelementer kan læses.
- Hvis vi ønsker at læse de underliggende data mere end én gang, vil rewind() metoden er praktisk.
- Den compact() metoden er velegnet til delvis genbrug af en buffer. Antag for eksempel, at vi ønsker at læse nogle, men ikke alle, af de underliggende data, og så vil vi skrive data til bufferen. compact() metoden kopierer de ulæste data til begyndelsen af bufferen og ændrer bufferindekserne for at være klar til skriveoperationer.
3.4. Forbliv
hasRemaining() og resterende() metoder beregner forholdet mellem grænsen og positionen :

Når grænsen er større end positionen , hasRemaining() vil returnere true . Også den resterende() metoden returnerer forskellen mellem grænsen og positionen .
For eksempel, hvis en buffer har en position på 2 og en grænse på 8, så vil dens resterende være 6:
ByteBuffer buffer = ByteBuffer.allocate(10); // mark = -1, position = 0, limit = 10
buffer.position(2); // mark = -1, position = 2, limit = 10
buffer.limit(8); // mark = -1, position = 2, limit = 8
boolean flag = buffer.hasRemaining(); // true
int remaining = buffer.remaining(); // 64. Overfør data
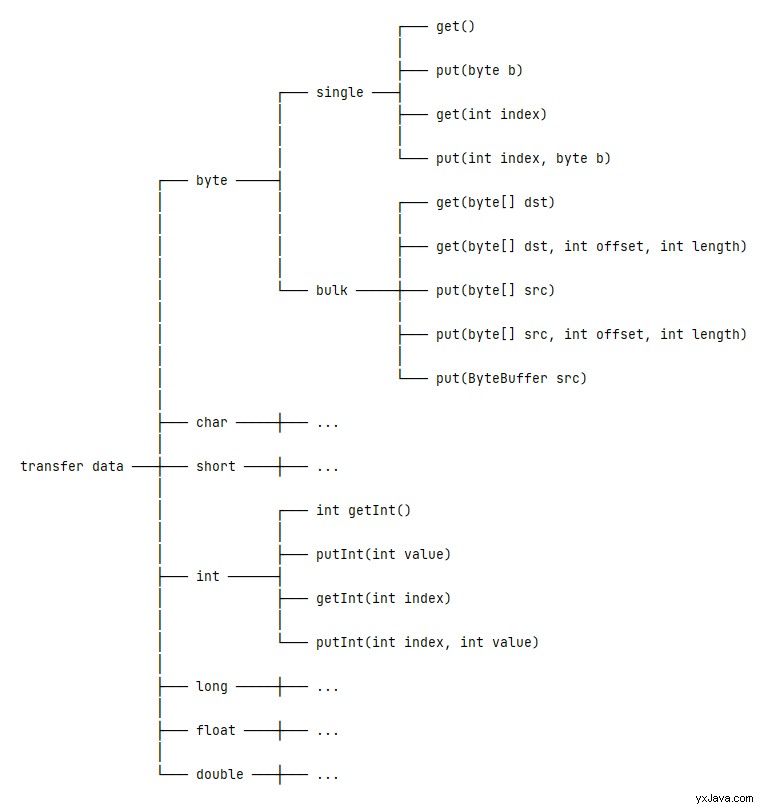
Det andet lag af Onion-modellen handler om overførsel af data. Specifikt ByteBuffer klasse giver metoder til at overføre data fra/til andre datatyper (byte , char , kort , int , lang , flyde og dobbelt ):
4.1. Overfør byte Data
For at overføre byte data, ByteBuffer klasse giver enkelt- og bulkoperationer.
Vi kan læse eller skrive en enkelt byte fra/til bufferens underliggende data i enkelte operationer. Disse operationer omfatter:
public abstract byte get();
public abstract ByteBuffer put(byte b);
public abstract byte get(int index);
public abstract ByteBuffer put(int index, byte b);Vi bemærker muligvis to versioner af get() /put() metoder fra ovenstående metoder:Den ene har ingen parametre, og den anden accepterer et indeks . Så hvad er forskellen?
Den uden indeks er en relativ operation, som opererer på dataelementet i den aktuelle position og senere øger positionen med 1. Den med et indeks er en hel operation, som opererer på dataelementerne i indekset og vil ikke ændre positionen .
I modsætning hertil kan massehandlingerne læse eller skrive flere bytes fra/til bufferens underliggende data. Disse operationer omfatter:
public ByteBuffer get(byte[] dst);
public ByteBuffer get(byte[] dst, int offset, int length);
public ByteBuffer put(byte[] src);
public ByteBuffer put(byte[] src, int offset, int length);Ovenstående metoder hører alle til relative operationer. Det vil sige, at de vil læse eller skrive fra/til den aktuelle position og ændre positionen værdi, henholdsvis.
Der er også en anden put() metode, som accepterer en ByteBuffer parameter:
public ByteBuffer put(ByteBuffer src);4.2. Overfør int Data
Udover at læse eller skrive byte data, ByteBuffer klasse understøtter også de andre primitive typer undtagen boolean type. Lad os tage int type som eksempel. De relaterede metoder omfatter:
public abstract int getInt();
public abstract ByteBuffer putInt(int value);
public abstract int getInt(int index);
public abstract ByteBuffer putInt(int index, int value);Tilsvarende er getInt() og putInt() metoder med et indeks parameter er absolutte operationer, ellers relative operationer.
5. Forskellige visninger
Det tredje lag af Onion Model handler om at læse de samme underliggende data med forskellige perspektiver .
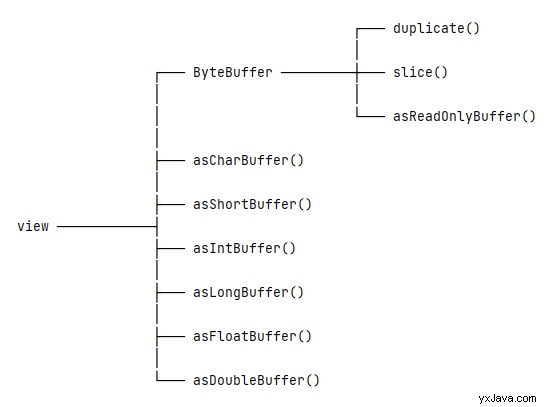
Hver metode i ovenstående billede vil generere en ny visning, der deler de samme underliggende data med original buffer. For at forstå en ny opfattelse bør vi være bekymrede over to problemer:
- Hvordan vil den nye visning parse de underliggende data?
- Hvordan vil den nye visning registrere sine indekser?
5.1. ByteBuffer Vis
At læse en ByteBuffer instans som en anden ByteBuffer view, den har tre metoder:duplicate() , slice() , og asReadOnlyBuffer() .
Lad os se på illustrationen af disse forskelle:
ByteBuffer buffer = ByteBuffer.allocate(10); // mark = -1, position = 0, limit = 10, capacity = 10
buffer.position(2); // mark = -1, position = 2, limit = 10, capacity = 10
buffer.mark(); // mark = 2, position = 2, limit = 10, capacity = 10
buffer.position(5); // mark = 2, position = 5, limit = 10, capacity = 10
buffer.limit(8); // mark = 2, position = 5, limit = 8, capacity = 10duplicate() metoden opretter en ny ByteBuffer eksempel ligesom den originale. Men hver af de to buffere vil have sin uafhængige grænse , position , og marker :
ByteBuffer view = buffer.duplicate(); // mark = 2, position = 5, limit = 8, capacity = 10slice() metoden opretter en delt undervisning af de underliggende data. Udsigtens position vil være 0, og dens grænse og kapacitet vil være resten af den oprindelige buffer:
ByteBuffer view = buffer.slice(); // mark = -1, position = 0, limit = 3, capacity = 3Sammenlignet med duplicate() metode, asReadOnlyBuffer() metoden fungerer på samme måde, men producerer en skrivebeskyttet buffer. Det betyder, at vi ikke kan bruge denne skrivebeskyttede visning til at ændre de underliggende data:
ByteBuffer view = buffer.asReadOnlyBuffer(); // mark = 2, position = 5, limit = 8, capacity = 105.2. Anden visning
ByteBuffer giver også andre visninger:asCharBuffer() , asShortBuffer() , asIntBuffer() , asLongBuffer() , asFloatBuffer() , og asDoubleBuffer() . Disse metoder ligner slice() metode, dvs. de giver en udsnitsvisning svarende til de underliggende datas aktuelle position og grænse . Den største forskel mellem dem er at fortolke de underliggende data til andre primitive typeværdier.
De spørgsmål, vi bør bekymre os om, er:
- Sådan fortolkes de underliggende data
- Hvor skal fortolkningen begynde
- Hvor mange elementer vil blive præsenteret i den nye genererede visning
Den nye visning vil sammensætte flere bytes til den primitive måltype, og den starter fortolkningen fra den aktuelle position af den oprindelige buffer. Den nye visning vil have en kapacitet svarende til antallet af resterende elementer i den oprindelige buffer divideret med antallet af bytes, der udgør visningens primitive type. Eventuelle resterende bytes i slutningen vil ikke være synlige i visningen.
Lad os nu tage asIntBuffer() som et eksempel:
byte[] bytes = new byte[]{
(byte) 0xCA, (byte) 0xFE, (byte) 0xBA, (byte) 0xBE, // CAFEBABE ---> cafebabe
(byte) 0xF0, (byte) 0x07, (byte) 0xBA, (byte) 0x11, // F007BA11 ---> football
(byte) 0x0F, (byte) 0xF1, (byte) 0xCE // 0FF1CE ---> office
};
ByteBuffer buffer = ByteBuffer.wrap(bytes);
IntBuffer intBuffer = buffer.asIntBuffer();
int capacity = intBuffer.capacity(); // 2I ovenstående kodestykke er bufferen har 11 dataelementer og int typen tager 4 bytes. Så intBuffer vil have 2 dataelementer (11 / 4 =2) og udelade de ekstra 3 bytes (11 % 4 =3).
6. Direkte buffer
Hvad er en direkte buffer? En direkte buffer refererer til en buffers underliggende data allokeret på et hukommelsesområde, hvor OS-funktioner kan få direkte adgang til dem. En ikke-direkte buffer refererer til en buffer, hvis underliggende data er en byte array, der er tildelt i Java-heap-området.
Så hvordan kan vi skabe en direkte buffer? En direkte ByteBuffer oprettes ved at kalde allocateDirect() metode med den ønskede kapacitet:
ByteBuffer buffer = ByteBuffer.allocateDirect(10);Hvorfor har vi brug for en direkte buffer? Svaret er enkelt:En ikke-direkte buffer medfører altid unødvendige kopieringsoperationer. Når du sender en ikke-direkte buffers data til I/O-enheder, skal den oprindelige kode "låse" den underliggende byte array, kopier det uden for Java-heapen, og kald derefter OS-funktionen for at tømme dataene. Den oprindelige kode kan dog få direkte adgang til de underliggende data og kalde OS-funktioner for at tømme dataene uden yderligere overhead ved at bruge en direkte buffer.
I lyset af ovenstående, er en direkte buffer perfekt? Nej. Hovedproblemet er, at det er dyrt at allokere og deallokere en direkte buffer. Så i virkeligheden kører en direkte buffer altid hurtigere end en ikke-direkte buffer? Ikke nødvendigvis. Det skyldes, at mange faktorer spiller ind. Og præstationsafvejningen kan variere meget afhængigt af JVM, operativsystem og kodedesign.
Endelig er der en praktisk software-maksime at følge:Først, få det til at virke, så gør det hurtigt . Det betyder, at lad os først koncentrere os om kodens korrekthed. Hvis koden ikke kører hurtigt nok, så lad os foretage den tilsvarende optimering.
7. Diverse
ByteBuffer klasse giver også nogle hjælpemetoder:
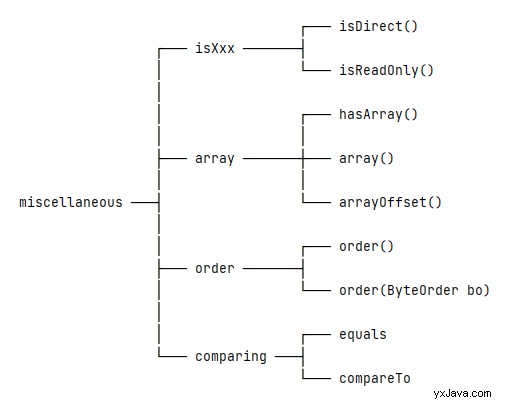
7.1. Er-relaterede metoder
isDirect() metode kan fortælle os, om en buffer er en direkte buffer eller en ikke-direkte buffer. Bemærk, at indpakkede buffere – dem, der er oprettet med wrap() metode – er altid ikke-direkte.
Alle buffere er læsbare, men ikke alle er skrivbare. isReadOnly() metode angiver, om vi kan skrive til de underliggende data.
For at sammenligne disse to metoder, isDirect() metode bekymrer sig om, hvor de underliggende data findes, i Java heap eller hukommelsesområde . Men den isReadOnly() metode bekymrer sig om, hvorvidt de underliggende dataelementer kan ændres .
Hvis en original buffer er direkte eller skrivebeskyttet, vil den nye genererede visning arve disse attributter.
7.2. Array-relaterede metoder
Hvis en ByteBuffer instans er direkte eller skrivebeskyttet, kan vi ikke få dens underliggende byte-array. Men hvis en buffer er ikke-direkte og ikke skrivebeskyttet, betyder det ikke nødvendigvis, at dens underliggende data er tilgængelige.
For at være præcis, den hasArray() metode kan fortælle os, om en buffer har et tilgængeligt backing-array eller ej . Hvis hasArray() metode returnerer true , så kan vi bruge array() og arrayOffset() metoder til at få mere relevant information.
7.3. Byterækkefølge
Som standard er byterækkefølgen for ByteBuffer klasse er altid ByteOrder.BIG_ENDIAN . Og vi kan bruge order() og ordre(ByteOrder) metoder til henholdsvis at hente og indstille den aktuelle byterækkefølge.
Byterækkefølgen påvirker, hvordan de underliggende data skal fortolkes. Antag for eksempel, at vi har en buffer eksempel:
byte[] bytes = new byte[]{(byte) 0xCA, (byte) 0xFE, (byte) 0xBA, (byte) 0xBE};
ByteBuffer buffer = ByteBuffer.wrap(bytes);Bruger ByteOrder.BIG_ENDIAN , val vil være -889275714 (0xCAFEBABE):
buffer.order(ByteOrder.BIG_ENDIAN);
int val = buffer.getInt();Men ved at bruge ByteOrder.LITTLE_ENDIAN , val vil være -1095041334 (0xBEBAFECA):
buffer.order(ByteOrder.LITTLE_ENDIAN);
int val = buffer.getInt();7.4. Sammenligner
ByteBuffer klasse giver equals() og compareTo() metoder til at sammenligne to bufferforekomster. Begge disse metoder udfører sammenligningen baseret på de resterende dataelementer, som er i området [position, limit) .
For eksempel kan to bufferforekomster med forskellige underliggende data og indekser være ens:
byte[] bytes1 = "World".getBytes(StandardCharsets.UTF_8);
byte[] bytes2 = "HelloWorld".getBytes(StandardCharsets.UTF_8);
ByteBuffer buffer1 = ByteBuffer.wrap(bytes1);
ByteBuffer buffer2 = ByteBuffer.wrap(bytes2);
buffer2.position(5);
boolean equal = buffer1.equals(buffer2); // true
int result = buffer1.compareTo(buffer2); // 08. Konklusion
I denne artikel forsøgte vi at behandle ByteBuffer klasse som løgmodel. Først forenklede vi det til en beholder med byte array med ekstra indekser. Derefter talte vi om, hvordan man bruger ByteBuffer klasse til at overføre data fra/til andre datatyper.
Dernæst så vi på de samme underliggende data med forskellige synspunkter. Til sidst diskuterede vi direkte buffer og nogle forskellige metoder.
Som sædvanlig kan kildekoden til denne tutorial findes på GitHub.