Hibernate Performance Tuning Tips – 2022 Edition
Redaktørens bemærkning:
Efter at have opdateret mit Hibernate Performance Tuning-kursus i Persistence Hub, var det tid til at gense denne artikel og opdatere den til 2022. Den giver dig nu de bedste tip til tuning af ydeevne til Hibernate 4, 5 og 6.
En af de største misforståelser om Hibernate er, at det forårsager ydeevneproblemer, hvis du bruger det på en enorm database eller med mange parallelle brugere. Men det er ikke tilfældet. Mange succesfulde projekter bruger det til at implementere et meget skalerbart og let vedligeholdeligt persistenslag. Så hvad er forskellen mellem disse projekter og dem, der lider af præstationsproblemer?
I mine konsulentprojekter ser jeg 2 hovedfejl, der forårsager de fleste præstationsproblemer:
- At kontrollere ingen eller de forkerte log-meddelelser under udvikling gør det umuligt at finde potentielle problemer.
- Misbrug af nogle af Hibernates funktioner tvinger den til at udføre yderligere SQL-sætninger, som hurtigt eskalerer i produktionen.
I det første afsnit af denne artikel vil jeg vise dig en logningskonfiguration, der hjælper dig med at identificere ydeevneproblemer under udvikling. Derefter vil jeg vise dig, hvordan du undgår disse problemer ved at bruge Hibernate 4, 5 og 6. Og hvis du vil dykke dybere ned i Hibernate og andre Java persistens-relaterede emner, anbefaler jeg, at du tilslutter dig Persistence Hub. Det giver dig adgang til et sæt eksklusive certificeringskurser, ekspertsessioner og Q&A-opkald.
1. Find ydeevneproblemer under udvikling
At finde ydeevneproblemerne, før de forårsager problemer i produktionen, er altid den mest kritiske del. Men det er ofte ikke så nemt, som det lyder. De fleste præstationsproblemer er næppe synlige på et lille testsystem. De er forårsaget af ineffektivitet, der skaleres baseret på størrelsen af din database og antallet af parallelle brugere. På grund af det har de næsten ingen effekt på ydeevnen, når du kører dine tests ved hjælp af en lille database og kun én bruger. Men det ændrer sig dramatisk, så snart du implementerer din applikation til produktion.
Selvom præstationsproblemerne er svære at finde på dit testsystem, kan du stadig se ineffektiviteten, hvis du tjekker Hibernates interne statistik. En måde at gøre dette på er at aktivere Hibernates statistikkomponent ved at indstille systemegenskaben hibernate.generate_statistics til sand og logniveauet for org.hibernate.stat kategori for at DEBUG . Hibernate vil derefter indsamle masser af interne statistikker og opsummere de vigtigste metrics i slutningen af hver session. For hver udført forespørgsel udskriver den også sætningen, dens udførelsestid og antallet af returnerede rækker.
Her kan du se et eksempel på sådan en oversigt:
07:03:29,976 DEBUG [org.hibernate.stat.internal.StatisticsImpl] - HHH000117: HQL: SELECT p FROM ChessPlayer p LEFT JOIN FETCH p.gamesWhite LEFT JOIN FETCH p.gamesBlack ORDER BY p.id, time: 10ms, rows: 4
07:03:30,028 INFO [org.hibernate.engine.internal.StatisticalLoggingSessionEventListener] - Session Metrics {
46700 nanoseconds spent acquiring 1 JDBC connections;
43700 nanoseconds spent releasing 1 JDBC connections;
383099 nanoseconds spent preparing 5 JDBC statements;
11505900 nanoseconds spent executing 4 JDBC statements;
8895301 nanoseconds spent executing 1 JDBC batches;
0 nanoseconds spent performing 0 L2C puts;
0 nanoseconds spent performing 0 L2C hits;
0 nanoseconds spent performing 0 L2C misses;
26450200 nanoseconds spent executing 1 flushes (flushing a total of 17 entities and 10 collections);
12322500 nanoseconds spent executing 1 partial-flushes (flushing a total of 1 entities and 1 collections)
}
Som du kan se i kodestykket, fortæller Hibernate dig, hvor mange JDBC-sætninger den udførte, om den brugte JDBC-batching, hvordan den brugte 2. niveaus cache, hvor mange flushes den udførte, og hvor lang tid de tog.
Det viser dig, hvilke databaseoperationer din use case udførte. Ved at tjekke dette regelmæssigt kan du undgå de mest almindelige problemer forårsaget af langsomme forespørgsler, for mange forespørgsler og manglende cachebrug. Og husk, at du arbejder med en lille testdatabase. 5 eller 10 yderligere forespørgsler under din test kan blive til flere hundrede eller tusinder, hvis du skifter til den større produktionsdatabase.
Hvis du bruger Dvaletilstand i mindst version 5.4.5 , bør du også konfigurere en tærskel for Hibernates langsomme forespørgselslog. Du kan gøre det ved at konfigurere egenskaben hibernate.session.events.log.LOG_QUERIES_SLOWER_THAN_MS i din persistence.xml-fil.
<persistence> <persistence-unit name="my-persistence-unit"> ... <properties> <property name="hibernate.session.events.log.LOG_QUERIES_SLOWER_THAN_MS" value="1" /> ... </properties> </persistence-unit> </persistence>
Hibernate måler derefter den rene udførelsestid for hver forespørgsel og skriver en logmeddelelse for hver enkelt, der tager længere tid end den konfigurerede tærskel.
12:23:20,545 INFO [org.hibernate.SQL_SLOW] - SlowQuery: 6 milliseconds. SQL: 'select a1_0.id,a1_0.firstName,a1_0.lastName,a1_0.version from Author a1_0'
2. Forbedre langsomme forespørgsler
Ved at bruge den tidligere beskrevne konfiguration vil du jævnligt finde langsomme forespørgsler. Men de er ikke et ægte JPA- eller Hibernate-problem. Denne form for ydeevneproblemer opstår med alle rammer, selv med almindelig SQL over JDBC. Det er derfor, din database giver forskellige værktøjer til at analysere en SQL-sætning.
Når du forbedrer dine forespørgsler, kan du bruge nogle databasespecifikke forespørgselsfunktioner. JPQL og Criteria API understøtter ikke disse. Men bare rolig. Du kan stadig bruge din optimerede forespørgsel med Hibernate. Du kan udføre det som en indbygget forespørgsel.
Author a = (Author) em.createNativeQuery("SELECT * FROM Author a WHERE a.id = 1", Author.class).getSingleResult();
Hibernate analyserer ikke en indbygget forespørgselssætning. Det giver dig mulighed for at bruge alle SQL og proprietære funktioner, som din database understøtter. Men det har også en ulempe. Du får forespørgselsresultatet som et Objekt[] i stedet for de stærkt indtastede resultater, der returneres af en JPQL-forespørgsel.
Hvis du vil tilknytte forespørgselsresultatet til entitetsobjekter, behøver du kun at vælge alle kolonner, der er kortlagt af din enhed, og angive dens klasse som den 2. parameter. Dvale anvender derefter automatisk enhedstilknytningen til dit forespørgselsresultat. Det gjorde jeg i det forrige kodestykke.
Og hvis du vil kortlægge resultatet til en anden datastruktur, skal du enten kortlægge det programmatisk eller bruge JPA's @SqlResultSetMapping anmærkninger. Jeg forklarede det meget detaljeret i en række artikler:
- Resultatsætkortlægning:Grundlæggende
- Resultatsætkortlægning:komplekse kortlægninger
- Resultatsætkortlægning:Konstruktørresultatkortlægninger
- Mapping af resultatsæt:Dvale specifikke funktioner
3. Undgå unødvendige forespørgsler – Vælg den rigtige FetchType
Et andet almindeligt problem, du vil finde efter aktivering af Hibernates statistik, er udførelsen af unødvendige forespørgsler. Dette sker ofte, fordi Hibernate skal initialisere en ivrigt hentet association, som du ikke engang bruger i din virksomhedskode.
Det er en typisk kortlægningsfejl, der definerer den forkerte FetchType. Det er angivet i entitetstilknytningen og definerer, hvornår en tilknytning vil blive indlæst fra databasen. FetchType.LAZY fortæller din persistensudbyder om at initialisere en tilknytning, når du bruger den første gang. Dette er åbenbart den mest effektive tilgang. FetchType.EAGER tvinger Hibernate til at initialisere tilknytningen, når entitetsobjektet instansieres. I værste fald forårsager dette en ekstra forespørgsel for hver tilknytning af hver hentede enhed. Afhængigt af din use case og størrelsen af din database kan dette hurtigt tilføje op til et par hundrede yderligere forespørgsler.
For at undgå dette skal du ændre FetchType af alle dine to-one-tilknytninger til FetchType.LAZY . Du kan gøre det ved at indstille hentningsattributten på @ManyToOne- eller @OneToOne-annotationen.
@ManyToOne(fetch=FetchType.LAZY)
Alle til-mange foreninger bruger FetchType.LAZY som standard, og det bør du ikke ændre.
Når du har sikret dig, at alle dine tilknytninger bruger FetchType.LAZY , bør du se nærmere på alle use cases, der bruger en dovent hentet association for at undgå følgende ydeevneproblem.
4. Undgå unødvendige forespørgsler – Brug forespørgselsspecifik hentning
Som jeg forklarede i det foregående afsnit, skal du bruge FetchType.LAZY for alle jeres foreninger. Det sikrer, at du kun henter dem, du bruger i din virksomhedskode. Men hvis du kun ændrer FetchType , bruger Hibernate en separat forespørgsel til at initialisere hver af disse tilknytninger. Det forårsager et andet ydeevneproblem, der kaldes n+1 select-problem.
Følgende kodestykke viser et typisk eksempel med Author og Bestil entitet med en dovent hentet mange-til-mange-forening mellem dem. getBooks() metode krydser denne sammenhæng.
List<Author> authors = em.createQuery("SELECT a FROM Author a", Author.class).getResultList();
for (Author author : authors) {
log.info(author + " has written " + author.getBooks().size() + " books.");
}
JPQL-forespørgslen får kun Author enhed fra databasen og initialiserer ikke bøgerne forening. Derfor skal Hibernate udføre en ekstra forespørgsel, når getBooks() metode for hver Forfatter enhed bliver kaldt for første gang. På min lille testdatabase, som kun indeholder 11 Forfatter entiteter, forårsager det forrige kodestykke udførelse af 12 SQL-sætninger.
12:30:53,705 DEBUG [org.hibernate.SQL] - select a1_0.id,a1_0.firstName,a1_0.lastName,a1_0.version from Author a1_0
12:30:53,731 DEBUG [org.hibernate.stat.internal.StatisticsImpl] - HHH000117: HQL: SELECT a FROM Author a, time: 38ms, rows: 11
12:30:53,739 DEBUG [org.hibernate.SQL] - select b1_0.authorId,b1_1.id,p1_0.id,p1_0.name,p1_0.version,b1_1.publishingDate,b1_1.title,b1_1.version from BookAuthor b1_0 join Book b1_1 on b1_1.id=b1_0.bookId left join Publisher p1_0 on p1_0.id=b1_1.publisherid where b1_0.authorId=?
12:30:53,746 INFO [com.thorben.janssen.hibernate.performance.TestIdentifyPerformanceIssues] - Author firstName: Joshua, lastName: Bloch has written 1 books.
12:30:53,747 DEBUG [org.hibernate.SQL] - select b1_0.authorId,b1_1.id,p1_0.id,p1_0.name,p1_0.version,b1_1.publishingDate,b1_1.title,b1_1.version from BookAuthor b1_0 join Book b1_1 on b1_1.id=b1_0.bookId left join Publisher p1_0 on p1_0.id=b1_1.publisherid where b1_0.authorId=?
12:30:53,750 INFO [com.thorben.janssen.hibernate.performance.TestIdentifyPerformanceIssues] - Author firstName: Gavin, lastName: King has written 1 books.
12:30:53,750 DEBUG [org.hibernate.SQL] - select b1_0.authorId,b1_1.id,p1_0.id,p1_0.name,p1_0.version,b1_1.publishingDate,b1_1.title,b1_1.version from BookAuthor b1_0 join Book b1_1 on b1_1.id=b1_0.bookId left join Publisher p1_0 on p1_0.id=b1_1.publisherid where b1_0.authorId=?
12:30:53,753 INFO [com.thorben.janssen.hibernate.performance.TestIdentifyPerformanceIssues] - Author firstName: Christian, lastName: Bauer has written 1 books.
12:30:53,754 DEBUG [org.hibernate.SQL] - select b1_0.authorId,b1_1.id,p1_0.id,p1_0.name,p1_0.version,b1_1.publishingDate,b1_1.title,b1_1.version from BookAuthor b1_0 join Book b1_1 on b1_1.id=b1_0.bookId left join Publisher p1_0 on p1_0.id=b1_1.publisherid where b1_0.authorId=?
12:30:53,756 INFO [com.thorben.janssen.hibernate.performance.TestIdentifyPerformanceIssues] - Author firstName: Gary, lastName: Gregory has written 1 books.
12:30:53,757 DEBUG [org.hibernate.SQL] - select b1_0.authorId,b1_1.id,p1_0.id,p1_0.name,p1_0.version,b1_1.publishingDate,b1_1.title,b1_1.version from BookAuthor b1_0 join Book b1_1 on b1_1.id=b1_0.bookId left join Publisher p1_0 on p1_0.id=b1_1.publisherid where b1_0.authorId=?
12:30:53,759 INFO [com.thorben.janssen.hibernate.performance.TestIdentifyPerformanceIssues] - Author firstName: Raoul-Gabriel, lastName: Urma has written 1 books.
12:30:53,759 DEBUG [org.hibernate.SQL] - select b1_0.authorId,b1_1.id,p1_0.id,p1_0.name,p1_0.version,b1_1.publishingDate,b1_1.title,b1_1.version from BookAuthor b1_0 join Book b1_1 on b1_1.id=b1_0.bookId left join Publisher p1_0 on p1_0.id=b1_1.publisherid where b1_0.authorId=?
12:30:53,762 INFO [com.thorben.janssen.hibernate.performance.TestIdentifyPerformanceIssues] - Author firstName: Mario, lastName: Fusco has written 1 books.
12:30:53,763 DEBUG [org.hibernate.SQL] - select b1_0.authorId,b1_1.id,p1_0.id,p1_0.name,p1_0.version,b1_1.publishingDate,b1_1.title,b1_1.version from BookAuthor b1_0 join Book b1_1 on b1_1.id=b1_0.bookId left join Publisher p1_0 on p1_0.id=b1_1.publisherid where b1_0.authorId=?
12:30:53,764 INFO [com.thorben.janssen.hibernate.performance.TestIdentifyPerformanceIssues] - Author firstName: Alan, lastName: Mycroft has written 1 books.
12:30:53,765 DEBUG [org.hibernate.SQL] - select b1_0.authorId,b1_1.id,p1_0.id,p1_0.name,p1_0.version,b1_1.publishingDate,b1_1.title,b1_1.version from BookAuthor b1_0 join Book b1_1 on b1_1.id=b1_0.bookId left join Publisher p1_0 on p1_0.id=b1_1.publisherid where b1_0.authorId=?
12:30:53,768 INFO [com.thorben.janssen.hibernate.performance.TestIdentifyPerformanceIssues] - Author firstName: Andrew Lee, lastName: Rubinger has written 2 books.
12:30:53,769 DEBUG [org.hibernate.SQL] - select b1_0.authorId,b1_1.id,p1_0.id,p1_0.name,p1_0.version,b1_1.publishingDate,b1_1.title,b1_1.version from BookAuthor b1_0 join Book b1_1 on b1_1.id=b1_0.bookId left join Publisher p1_0 on p1_0.id=b1_1.publisherid where b1_0.authorId=?
12:30:53,771 INFO [com.thorben.janssen.hibernate.performance.TestIdentifyPerformanceIssues] - Author firstName: Aslak, lastName: Knutsen has written 1 books.
12:30:53,772 DEBUG [org.hibernate.SQL] - select b1_0.authorId,b1_1.id,p1_0.id,p1_0.name,p1_0.version,b1_1.publishingDate,b1_1.title,b1_1.version from BookAuthor b1_0 join Book b1_1 on b1_1.id=b1_0.bookId left join Publisher p1_0 on p1_0.id=b1_1.publisherid where b1_0.authorId=?
12:30:53,775 INFO [com.thorben.janssen.hibernate.performance.TestIdentifyPerformanceIssues] - Author firstName: Bill, lastName: Burke has written 1 books.
12:30:53,775 DEBUG [org.hibernate.SQL] - select b1_0.authorId,b1_1.id,p1_0.id,p1_0.name,p1_0.version,b1_1.publishingDate,b1_1.title,b1_1.version from BookAuthor b1_0 join Book b1_1 on b1_1.id=b1_0.bookId left join Publisher p1_0 on p1_0.id=b1_1.publisherid where b1_0.authorId=?
12:30:53,777 INFO [com.thorben.janssen.hibernate.performance.TestIdentifyPerformanceIssues] - Author firstName: Scott, lastName: Oaks has written 1 books.
12:30:53,799 INFO [org.hibernate.engine.internal.StatisticalLoggingSessionEventListener] - Session Metrics {
37200 nanoseconds spent acquiring 1 JDBC connections;
23300 nanoseconds spent releasing 1 JDBC connections;
758803 nanoseconds spent preparing 12 JDBC statements;
23029401 nanoseconds spent executing 12 JDBC statements;
0 nanoseconds spent executing 0 JDBC batches;
0 nanoseconds spent performing 0 L2C puts;
0 nanoseconds spent performing 0 L2C hits;
0 nanoseconds spent performing 0 L2C misses;
17618900 nanoseconds spent executing 1 flushes (flushing a total of 20 entities and 26 collections);
21300 nanoseconds spent executing 1 partial-flushes (flushing a total of 0 entities and 0 collections)
}
Det kan du undgå ved at bruge forespørgselsspecifik ivrig hentning, som du kan definere på forskellige måder.
Brug en JOIN FETCH-klausul
Du kan tilføje en JOIN FETCH klausul til din JPQL-forespørgsel. Den yderligere FETCH nøgleordet fortæller Hibernate ikke kun at forbinde de to enheder i forespørgslen, men også at hente de tilknyttede enheder fra databasen.
List<Author> authors = em.createQuery("SELECT a FROM Author a JOIN FETCH a.books b", Author.class).getResultList();
Som du kan se i logoutputtet, genererer Hibernate en SQL-sætning, der vælger alle kolonner, der er kortlagt af Author og Book entitet og kortlægger resultatet til administrerede enhedsobjekter.
12:43:02,616 DEBUG [org.hibernate.SQL] - select a1_0.id,b1_0.authorId,b1_1.id,b1_1.publisherid,b1_1.publishingDate,b1_1.title,b1_1.version,a1_0.firstName,a1_0.lastName,a1_0.version from Author a1_0 join (BookAuthor b1_0 join Book b1_1 on b1_1.id=b1_0.bookId) on a1_0.id=b1_0.authorId
12:43:02,650 DEBUG [org.hibernate.stat.internal.StatisticsImpl] - HHH000117: HQL: SELECT a FROM Author a JOIN FETCH a.books b, time: 49ms, rows: 11
12:43:02,667 INFO [org.hibernate.engine.internal.StatisticalLoggingSessionEventListener] - Session Metrics {
23400 nanoseconds spent acquiring 1 JDBC connections;
26401 nanoseconds spent releasing 1 JDBC connections;
157701 nanoseconds spent preparing 1 JDBC statements;
2950900 nanoseconds spent executing 1 JDBC statements;
0 nanoseconds spent executing 0 JDBC batches;
0 nanoseconds spent performing 0 L2C puts;
0 nanoseconds spent performing 0 L2C hits;
0 nanoseconds spent performing 0 L2C misses;
13037201 nanoseconds spent executing 1 flushes (flushing a total of 17 entities and 23 collections);
20499 nanoseconds spent executing 1 partial-flushes (flushing a total of 0 entities and 0 collections)
}
Hvis du bruger Hibernate 4 eller 5 , bør du inkludere DISTINCT søgeord i din forespørgsel. Ellers returnerer Hibernate hver forfatter lige så ofte, som de har skrevet en bog.
Og du bør også indstille forespørgselstippet hibernate.query.passDistinctThrough til false . Det fortæller Hibernate ikke at inkludere DISTINCT nøgleord i den genererede SQL-sætning, og brug det kun, når du kortlægger forespørgselsresultatet.
List<Author> authors = em.createQuery("SELECT DISTINCT a FROM Author a JOIN FETCH a.books b", Author.class)
.setHint(QueryHints.PASS_DISTINCT_THROUGH, false)
.getResultList();
Brug en @NamedEntityGraph
En anden mulighed er at bruge en @NamedEntityGraph . Dette var en af de funktioner, der blev introduceret i JPA 2.1, og Hibernate har understøttet det siden version 4.3. Det giver dig mulighed for at definere en graf over enheder, der skal hentes fra databasen.
@NamedEntityGraph(name = "graph.AuthorBooks", attributeNodes = @NamedAttributeNode(value = "books"))
Kombination af enhedsgrafen med en forespørgsel, der vælger en Forfatter enhed giver dig det samme resultat som det foregående eksempel. EntityManager henter alle kolonner kortlagt af Forfatteren og Book entitet og tilknytter dem til administrerede enhedsobjekter.
List<Author> authors = em
.createQuery("SELECT a FROM Author a", Author.class)
.setHint(QueryHints.JAKARTA_HINT_FETCH_GRAPH, graph)
.getResultList();
Du kan finde en mere detaljeret beskrivelse om @NamedEntityGraphs og hvordan man bruger dem til at definere mere komplekse grafer i JPA Entity Graphs – Del 1:Navngivne entitetsgrafer.
Og hvis du bruger en dvaleversion <5.3 , skal du tilføje DISTINCT søgeord og indstil forespørgselstip hibernate.query.passDistinctThrough til falsk for at lade Hibernate fjerne alle dubletter fra dit forespørgselsresultat.
Brug en EntityGraph
Hvis du har brug for en mere dynamisk måde at definere din enhedsgraf på, kan du også gøre dette via en Java API. Det følgende kodestykke definerer den samme graf som de tidligere beskrevne annoteringer.
EntityGraph graph = em.createEntityGraph(Author.class);
Subgraph bookSubGraph = graph.addSubgraph(Author_.books);
List<Author> authors = em
.createQuery("SELECT a FROM Author a", Author.class)
.setHint(QueryHints.JAKARTA_HINT_FETCH_GRAPH, graph)
.getResultList();
I lighed med de foregående eksempler vil Hibernate bruge grafen til at definere en forespørgsel, der vælger alle kolonner, der er kortlagt af Forfatteren og Bestil entitet og tilknytte forespørgselsresultatet til de tilsvarende entitetsobjekter.
Hvis du bruger en dvaleversion <5.3 , bør du tilføje DISTINCT søgeord og indstil forespørgselstip hibernate.query.passDistinctThrough til falsk for at lade Hibernate fjerne alle dubletter fra dit forespørgselsresultat.
5. Lad være med at modellere en mange-til-mange-forening som en liste
En anden almindelig fejl, som jeg ser i mange kodegennemgange, er en mange-til-mange-forening modelleret som en java.util.List . En liste kan være den mest effektive samlingstype i Java. Men desværre administrerer Hibernate mange-til-mange associationer meget ineffektivt, hvis du modellerer dem som en Liste . Hvis du tilføjer eller fjerner et element, fjerner Hibernate alle elementer af tilknytningen fra databasen, før den indsætter alle de resterende.
Lad os tage et kig på et simpelt eksempel. bogen enhed modellerer en mange-til-mange-tilknytning til Forfatteren enhed som en Liste .
@Entity
public class Book {
@ManyToMany
private List<Author> authors = new ArrayList<Author>();
...
}
Når jeg tilføjer en forfatter til listen over tilknyttede forfattere , Dvaletilstand sletter alle tilknytningsposter for den givne bog og indsætter en ny post for hvert element i listen .
Author a = new Author();
a.setId(100L);
a.setFirstName("Thorben");
a.setLastName("Janssen");
em.persist(a);
Book b = em.find(Book.class, 1L);
b.getAuthors().add(a);
14:13:59,430 DEBUG [org.hibernate.SQL] -
select
b1_0.id,
b1_0.format,
b1_0.publishingDate,
b1_0.title,
b1_0.version
from
Book b1_0
where
b1_0.id=?
14:13:59,478 DEBUG [org.hibernate.SQL] -
insert
into
Author
(firstName, lastName, version, id)
values
(?, ?, ?, ?)
14:13:59,484 DEBUG [org.hibernate.SQL] -
update
Book
set
format=?,
publishingDate=?,
title=?,
version=?
where
id=?
and version=?
14:13:59,489 DEBUG [org.hibernate.SQL] -
delete
from
book_author
where
book_id=?
14:13:59,491 DEBUG [org.hibernate.SQL] -
insert
into
book_author
(book_id, author_id)
values
(?, ?)
14:13:59,494 DEBUG [org.hibernate.SQL] -
insert
into
book_author
(book_id, author_id)
values
(?, ?)
14:13:59,495 DEBUG [org.hibernate.SQL] -
insert
into
book_author
(book_id, author_id)
values
(?, ?)
14:13:59,499 DEBUG [org.hibernate.SQL] -
insert
into
book_author
(book_id, author_id)
values
(?, ?)
14:13:59,509 INFO [org.hibernate.engine.internal.StatisticalLoggingSessionEventListener] - Session Metrics {
26900 nanoseconds spent acquiring 1 JDBC connections;
35000 nanoseconds spent releasing 1 JDBC connections;
515400 nanoseconds spent preparing 8 JDBC statements;
24326800 nanoseconds spent executing 8 JDBC statements;
0 nanoseconds spent executing 0 JDBC batches;
0 nanoseconds spent performing 0 L2C puts;
0 nanoseconds spent performing 0 L2C hits;
0 nanoseconds spent performing 0 L2C misses;
43404700 nanoseconds spent executing 1 flushes (flushing a total of 6 entities and 5 collections);
0 nanoseconds spent executing 0 partial-flushes (flushing a total of 0 entities and 0 collections)
}
Du kan nemt undgå denne ineffektivitet ved at modellere din mange-til-mange-forening som et java.util.Set .
@Entity
public class Book {
@ManyToMany
private Set<Author> authors = new HashSet<Author>();
...
}
6. Lad databasen håndtere datatunge operationer
OK, dette er en anbefaling, som de fleste Java-udviklere ikke rigtig kan lide, fordi den flytter dele af forretningslogikken fra forretningsniveauet (implementeret i Java) ind i databasen.
Og misforstå mig ikke, der er gode grunde til at vælge Java til at implementere forretningslogikken og en database til at gemme dine data. Men du skal også overveje, at en database håndterer enorme datasæt meget effektivt. Derfor kan det være en god idé at flytte ikke alt for komplekse og meget datatunge operationer ind i databasen.
Der er flere måder at gøre det på. Du kan bruge databasefunktioner til at udføre simple operationer i JPQL og native SQL-forespørgsler. Hvis du har brug for mere komplekse operationer, kan du kalde en lagret procedure. Siden JPA 2.1/Hibernate 4.3 kan du kalde lagrede procedurer via @NamedStoredProcedureQuery eller den tilsvarende Java API. Hvis du bruger en ældre Hibernate-version, kan du gøre det samme ved at skrive en indbygget forespørgsel.
Følgende kodestykke viser en @NamedStoredProcedure definition for getBooks gemt procedure. Denne procedure returnerer en REF_CURSOR som kan bruges til at gentage det returnerede datasæt.
@NamedStoredProcedureQuery(
name = "getBooks",
procedureName = "get_books",
resultClasses = Book.class,
parameters = { @StoredProcedureParameter(mode = ParameterMode.REF_CURSOR, type = void.class) }
)
I din kode kan du derefter instansiere @NamedStoredProcedureQuery og udføre det.
List<Book> books = (List<Book>) em.createNamedStoredProcedureQuery("getBooks").getResultList();
7. Brug caches for at undgå at læse de samme data flere gange
Modulært applikationsdesign og parallelle brugersessioner resulterer ofte i, at de samme data læses flere gange. Dette er naturligvis en overhead, som du bør forsøge at undgå. En måde at gøre dette på er at cache de data, der ofte læses, men sjældent ændres.
Som du kan se nedenfor, tilbyder Hibernate 3 forskellige caches, som du kan kombinere med hinanden.
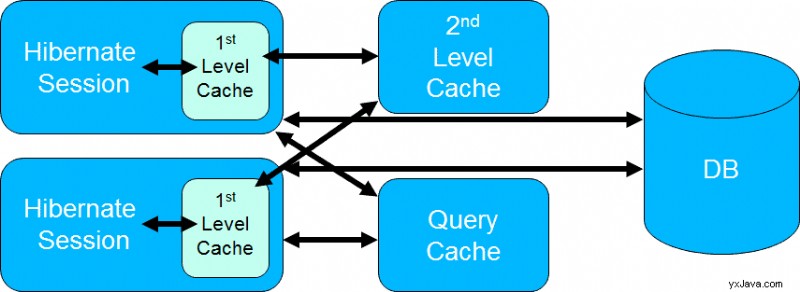
Caching er et komplekst emne og kan forårsage alvorlige bivirkninger. Det er derfor, mit Hibernate Performance Tuning-kursus (inkluderet i Persistence Hub) indeholder et helt modul om det. I denne artikel kan jeg kun give dig et hurtigt overblik over Hibernates 3 forskellige caches. Jeg anbefaler, at du gør dig bekendt med alle detaljerne i Hibernates caches, før du begynder at bruge nogen af dem.
1st Level Cache
Cachen på 1. niveau er aktiveret som standard og indeholder alle administrerede enheder. Disse er alle enheder, som du har brugt i den aktuelle session .
Cache på 2. niveau
Den sessionsuafhængige cache på 2. niveau gemmer også enheder. Du skal aktivere den ved at indstille delt-cache-tilstand ejendom i din persistence.xml fil. Jeg anbefaler, at du indstiller den til ENABLE_SELECTIVE og aktivér kun caching for enhedsklasserne, som du læser mindst 9-10 gange for hver skriveoperation.
<persistence>
<persistence-unit name="my-persistence-unit">
...
<! – enable selective 2nd level cache – >
<shared-cache-mode>ENABLE_SELECTIVE</shared-cache-mode>
</persistence-unit>
</persistence>
Du kan aktivere caching for en enhedsklasse ved at annotere den med jakarta.persistence.Cacheable eller org.hibernate.annotations.Cache .
@Entity
@Cacheable
public class Author { ... }
Når du har gjort det, tilføjer Hibernate automatisk ny forfatter entiteter og dem du hentede fra databasen til cachen på 2. niveau. Den kontrollerer også, om cachen på 2. niveau indeholder den anmodede Forfatter enhed, før den krydser en tilknytning eller genererer en SQL-sætning til kaldet af EntityManager.find metode. Men vær opmærksom på, at Hibernate ikke bruger 2. niveaus cache, hvis du definerer din egen JPQL, Criteria eller native forespørgsel.
Forespørgselscache
Forespørgselscachen er den eneste, der ikke gemmer enheder. Den cacherer forespørgselsresultater og indeholder kun enhedsreferencer og skalarværdier. Du skal aktivere cachen ved at indstille hibernate.cache.use_query_cache egenskaben i persistence.xml fil og indstil den cachebare ejendom på Forespørgsel .
Query<Author> q = session.createQuery("SELECT a FROM Author a WHERE id = :id", Author.class);
q.setParameter("id", 1L);
q.setCacheable(true);
Author a = q.uniqueResult();
8. Udfør opdateringer og sletninger på én gang
At opdatere eller slette den ene enhed efter den anden føles ret naturligt i Java, men det er også meget ineffektivt. Hibernate opretter én SQL-forespørgsel for hver enhed, der blev opdateret eller slettet. En bedre tilgang ville være at udføre disse operationer i bulk ved at oprette opdateringer eller slette erklæringer, der påvirker flere poster på én gang.
Du kan gøre dette via JPQL eller SQL-sætninger eller ved at bruge CriteriaUpdate og Kriterier Slet operationer. Følgende kodestykke viser et eksempel på en CriteriaUpdate udmelding. Som du kan se, bruges den på samme måde som den allerede kendte CriteriaQuery udsagn.
CriteriaBuilder cb = this.em.getCriteriaBuilder();
// create update
CriteriaUpdate<Order> update = cb.createCriteriaUpdate(Order.class);
// set the root class
Root e = update.from(Order.class);
// set update and where clause
update.set("amount", newAmount);
update.where(cb.greaterThanOrEqualTo(e.get("amount"), oldAmount));
// perform update
this.em.createQuery(update).executeUpdate(); Konklusion
Som du har set, er der flere Hibernate-funktioner, du kan bruge til at opdage og undgå ineffektivitet og øge din applikations ydeevne. Efter min erfaring er de vigtigste Hibernate-statistikkerne, som giver dig mulighed for at finde disse problemer, definitionen af den rigtige FetchType i entitetstilknytningen og forespørgselsspecifik ivrig hentning.
Du kan få mere information om disse og alle andre Hibernate-funktioner i de kurser, der er inkluderet i Persistence Hub.