Kürzliche Leistungsverbesserungen der Drools DMN-Open-Source-Engine
Wir sind stets bestrebt, die Leistung der Drools DMN-Open-Source-Engine zu verbessern. Wir haben kürzlich einen DMN-Anwendungsfall überprüft, bei dem die tatsächliche Eingabepopulation von Eingabedatenknoten in gewissem Maße variierte; Dies zeigte ein suboptimales Verhalten der Engine, das wir in den letzten Versionen verbessert haben. Ich möchte unsere Erkenntnisse teilen!
Benchmark-Entwicklung
Als wir damit begannen, einen unterstützenden Benchmark für diesen Anwendungsfall auszuführen, insbesondere bei der Untersuchung des Szenarios großer DMN-Modelle mit spärlich gefüllten Eingabedatenknoten, stellten wir einige seltsame Ergebnisse fest:Die Flamegraph-Daten zeigten einen erheblichen Leistungseinbruch beim Protokollieren von Nachrichten, der sehr viel verbrauchte erhebliche Zeit im Vergleich zur Anwendungslogik selbst.
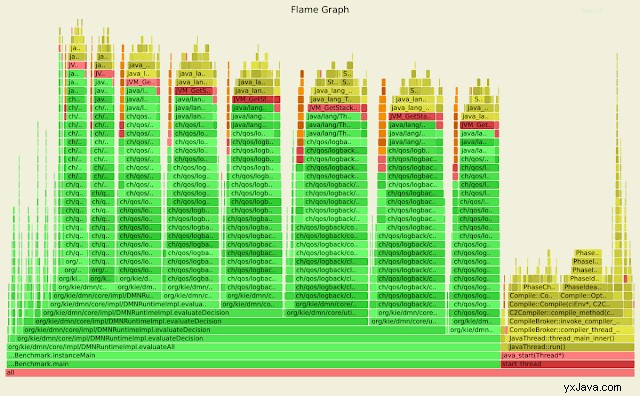
Dieses Flammendiagramm hebt insbesondere hervor, dass ein großer Teil der Zeit durch die Stacktrace-Synthese verbraucht wird, die künstlich durch das Protokollierungs-Framework induziert wird. Die Korrektur bestand in diesem Fall darin, die Protokollierungskonfiguration zu optimieren, um dieses Problem zu vermeiden; Insbesondere haben wir eine Funktion des Protokollierungsframeworks deaktiviert, die während der Debugging-Aktivitäten sehr praktisch ist und ein schnelles Auffinden der ursprünglichen aufrufenden Klasse und Methoden ermöglicht:Leider geht diese Funktion zu Lasten der Synthetisierung von Stacktraces, die ursprünglich die Benchmark-Ergebnisse verunreinigten. Hier gelernt:Überprüfen Sie immer zuerst, ob nicht-funktionale Anforderungen tatsächlich das eigentliche Problem überdecken!
Dies war ein notwendiger und propädeutischer Schritt, bevor der Anwendungsfall genauer untersucht wurde.
Verbesserung der Leistung
Um weiterzugehen und uns nun auf DMN-Optimierungen zu konzentrieren, haben wir speziell einen Benchmark entwickelt, um allgemein genug zu sein, aber auch den Anwendungsfall hervorzuheben, der uns präsentiert wurde. Dieser Benchmark besteht aus einem DMN-Modell mit vielen (500) zu bewertenden Entscheidungsknoten. Ein weiterer Parameter steuert die spärliche Valorisierung der Eingangsdatenknoten für die Auswertung; von einem Wert von 1, bei dem alle Eingänge belegt sind, bis zu 2, bei dem nur einer von zwei Eingängen belegt ist, usw.
Dieser spezifische Benchmark erwies sich als sehr hilfreiches Instrument, um einige potenzielle Verbesserungen aufzuzeigen.
Die erste mit DROOLS-4204 implementierte Optimierung, die auf die Drools-Version 7.23.0.Final gesetzt wurde, konzentrierte sich auf die Verbesserung der Kontexthandhabung bei der Bewertung von FEEL-Ausdrücken und zeigte eine ~3-fache Verbesserung, während sich die weitere Optimierung mit DROOLS-4266 auf Spezifisches konzentrierte Fall für Entscheidungstabellen-Eingabeklauseln zeigte eine zusätzliche ~2x-Verbesserung zusätzlich zu DROOLS-4204.
Wir haben diese Messungen auch in den folgenden Grafiken gesammelt. 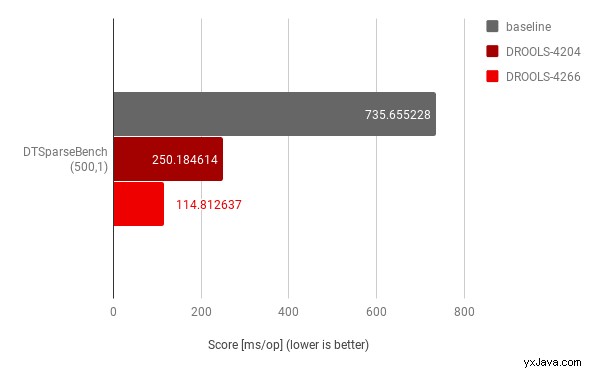
Dieses Diagramm hebt die Compounding-Verbesserungen im Fall eines Sparseness-Faktors gleich 1 hervor, bei dem alle Eingaben belegt sind; dies war ein sehr wichtiges Ergebnis, da es tatsächlich das Hauptergebnis darstellte , „Happy Path“-Szenario im ursprünglichen Anwendungsfall.
Mit anderen Worten, wir haben eine ~6-fache Verbesserung im Vergleich zur Ausführung desselben Anwendungsfalls erzielt
7.23.0.Final. Die Lektion, die ich hier gelernt habe, ist, immer nach dieser Art von Zusammensetzung zu streben Verbesserungen, wenn möglich, da sie wirklich aufeinander aufbauen, für bessere Ergebnisse!
Der Vollständigkeit halber haben wir die Analyse mit einem Sparseness-Faktor gleich 2 (1 alle 2 Eingänge ist tatsächlich belegt) und 50 (1 alle 50 Eingänge ist tatsächlich belegt) mit den folgenden Messungen wiederholt: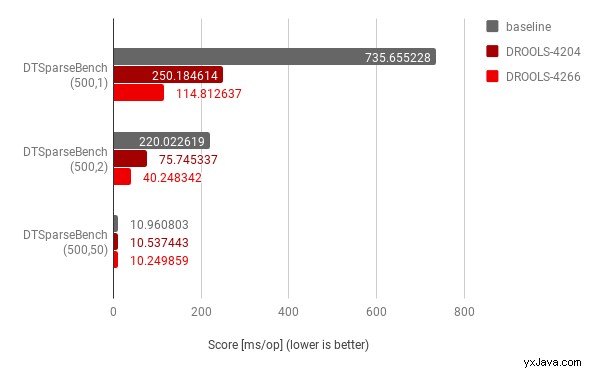
Die Ergebnisse zeigen, dass die Optimierungen auch für den Sparseness-Faktor gleich 2 signifikant waren, aber nicht so relevante Verbesserungen, wenn dieser Faktor wächst – was zu erwarten ist, da die Auswirkungen der Auswertungen der Entscheidungsknoten auf die Gesamtlogik der Ausführung nun weniger relevant werden.
Der Vollständigkeit halber wurde die Analyse auch mit einem anderen, bereits vorhandenen Benchmark für eine einzelne Entscheidungstabelle durchgeführt, die aus vielen Regelzeilen besteht: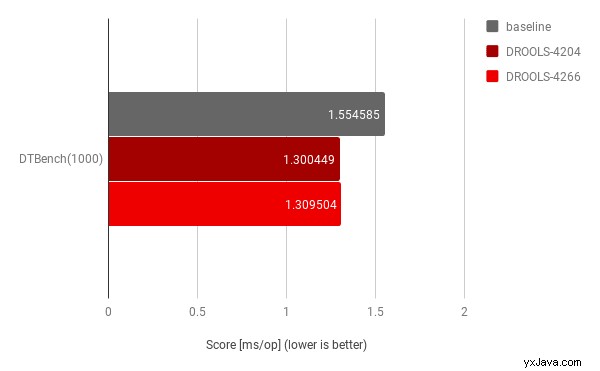
Die Ergebnisse zeigen, dass diese Codeänderungen insgesamt betrachtet immer noch eine relevante Verbesserung boten; obwohl eindeutig nicht in der gleichen Größe wie für den ursprünglichen Anwendungsfall. Dies war eine weitere wichtige Überprüfung, um sicherzustellen, dass diese Verbesserungen nicht zu sehr auf den spezifischen Anwendungsfall zugeschnitten sind.
Schlussfolgerungen
Unter Berücksichtigung von Drools Version 7.23.0.Final als Basis und einem Referenz-Benchmark, bestehend aus einem DMN-Modell mit vielen zu evaluierenden Entscheidungsknoten, haben wir mehrere Optimierungen implementiert, die, wenn sie kombiniert wurden, gezeigt haben, dass sie in diesem speziellen Fall insgesamt eine etwa 6-fache Beschleunigung bieten Anwendungsfall!
Ich hoffe, dies war ein interessanter Beitrag, um einige der Dimensionen hervorzuheben, die untersucht werden müssen, um bessere Leistungen zu erzielen. teilen Sie uns Ihre Meinung und Ihr Feedback mit.
Sie können bereits heute von diesen Kie DMN-Open-Source-Engine-Verbesserungen in den neuesten Versionen von Drools profitieren!