So reduzieren Sie die Cloud-Kosten um 99 % für EDA-Kafka-Anwendungen
Während die Cloud großen Komfort und Flexibilität bietet, können die Betriebskosten für Anwendungen, die in der Cloud bereitgestellt werden, manchmal erheblich sein. Dieser Artikel zeigt eine Möglichkeit, die Betriebskosten in latenzempfindlichen EDA-Java-Anwendungen durch die Migration von Kafka zu Chronicle Queue Open Source, einer ressourceneffizienteren Warteschlangenimplementierung mit geringerer Latenz, erheblich zu senken.
Was ist EDA?
Eine EDA-Anwendung ist eine verteilte Anwendung, in der Ereignisse (in Form von Nachrichten oder DTOs) erzeugt, erkannt, konsumiert und darauf reagiert wird. Verteilt bedeutet, dass es auf verschiedenen Computern oder auf demselben Computer ausgeführt werden kann, jedoch in separaten Prozessen oder Threads. Das letztere Konzept wird in diesem Artikel verwendet, wobei Nachrichten in Warteschlangen gespeichert werden.
In Szene setzen
Angenommen, wir haben eine EDA-Anwendung mit einer Kette von fünf Diensten, und wir haben die Anforderung, dass 99,9 % der Nachrichten, die vom ersten Erzeuger zum letzten Verbraucher gesendet werden, eine Latenzzeit von weniger als 100 ms bei einer Nachrichtenrate von 1.000 Nachrichten pro haben sollten zweitens.

Mit anderen Worten, die Zeit, die vom Senden einer Nachricht (dh unter Verwendung von Thema 0) durch den Benchmark-Thread bis zum erneuten Empfang einer resultierenden Nachricht durch den Benchmark-Thread (dh über Thema 5) vergeht, darf nur größer als 100 ms sein für im Durchschnitt eine von 1.000 Nachrichten, die jede Sekunde gesendet werden.
Die in diesem Artikel verwendeten Botschaften sind einfach. Sie enthalten einen langen Nanosekunden-Zeitstempel, der den anfänglichen Zeitstempel enthält, wenn eine Nachricht zum ersten Mal über Thema 0 gepostet wird, und einen int-Wert, der jedes Mal um eins erhöht wird, wenn die Nachricht von einem Dienst zum nächsten weitergegeben wird (dieser Wert wird nicht wirklich verwendet, veranschaulicht aber eine rudimentäre Dienstlogik). Wenn eine Nachricht beim Benchmark-Thread zurückkommt, wird die aktuelle Nanozeit mit der ursprünglichen Nanozeit in der ursprünglichen Nachricht verglichen, die zu Thema 0 gesendet wurde, um die Berechnung der Gesamtlatenz über die gesamte Dienstkette hinweg zu ermöglichen. Die Latenz-Samples werden anschließend zur späteren Analyse in ein Histogramm eingespeist.
Wie in Abbildung 1 oben zu sehen ist, ist die Anzahl der Themen/Warteschlangen gleich der Anzahl der Dienste plus eins. Daher gibt es sechs Themen/Warteschlangen, weil es fünf Dienste gibt.
Die Frage
Die Frage in diesem Artikel lautet:Wie viele Instanzen dieser Ketten können wir auf einer bestimmten Hardware einrichten und trotzdem die Latenzanforderungen erfüllen? Oder anders formuliert:Wie viele dieser Anwendungen können wir ausführen und trotzdem den gleichen Preis für die verwendete Hardware bezahlen?
Standardeinstellung
In diesem Artikel habe ich mich für Apache Kafka entschieden, da es einer der am häufigsten verwendeten Warteschlangentypen auf dem Markt ist. Ich habe mich auch für Chronicle Queue entschieden, da es eine geringe Latenzzeit und Ressourceneffizienz bietet.
Sowohl Kafka als auch Chronicle Queue verfügen über mehrere konfigurierbare Optionen, einschließlich der Replikation von Daten über mehrere Server. In diesem Artikel wird eine einzelne nicht replizierte Warteschlange verwendet. Aus Leistungsgründen wird der Kafka-Broker auf demselben Computer wie die Dienste ausgeführt, wodurch die Verwendung der lokalen Loopback-Netzwerkschnittstelle ermöglicht wird.
Die KafkaProducer-Instanzen sind so konfiguriert, dass sie für niedrige Latenz optimiert sind (z. B. durch Festlegen von „acks=1“), ebenso wie die KafkaConsumer-Instanzen.
Die Chronicle-Warteschlangeninstanzen werden mit dem Standard-Setup ohne explizite Optimierung erstellt. Daher werden die fortgeschritteneren Leistungsfunktionen in Chronicle Queue wie CPU-Core-Pinning und Busy Spin Waiting nicht verwendet.
Kafka
Apache Kafka ist eine verteilte Open-Source-Event-Streaming-Plattform für leistungsstarke Datenpipelines, Streaming-Analysen, Datenintegration und unternehmenskritische Anwendungen, die häufig in verschiedenen EDA-Anwendungen verwendet werden, insbesondere wenn mehrere Informationsquellen, die sich an verschiedenen Standorten befinden, aggregiert und aggregiert werden sollen verbraucht.
In diesem Benchmark erstellt jede Testinstanz sechs verschiedene Kafka-Themen mit den Namen topicXXXX0, topicXXXX1, …, topicXXXX5, wobei XXXXX eine Zufallszahl ist.
Chronik-Warteschlange
Open-Source Chronicle Queue ist ein persistentes Messaging-Framework mit niedriger Latenz für leistungsstarke und kritische Anwendungen. Interessanterweise verwendet Chronicle Queue Off-Heap-Speicher und Memory-Mapping, um den Speicherdruck und die Auswirkungen der Garbage-Collection zu reduzieren, was das Produkt im Fintech-Bereich beliebt macht, wo deterministisches Messaging mit geringer Latenz entscheidend ist.
In diesem anderen Benchmark erstellt jede Testinstanz sechs Chronicle-Warteschlangeninstanzen mit den Namen topicXXXX0, topicXXXX1, …, topicXXXX5, wobei XXXXX eine Zufallszahl ist.
Code
Die inneren Schleifen für die zwei verschiedenen Service-Thread-Implementierungen sind unten dargestellt. Sie fragen beide ihre Eingangswarteschlange ab, bis sie zum Herunterfahren aufgefordert werden, und wenn keine Nachrichten vorhanden sind, warten sie ein Achtel der erwarteten Zeit zwischen den Nachrichten, bevor ein neuer Versuch unternommen wird.
Hier ist der Code:
Kafka
while (!shutDown.get()) {
ConsumerRecords<Integer, Long> records =
inQ.poll(Duration.ofNanos(INTER_MESSAGE_TIME_NS / 8));
for (ConsumerRecord<Integer, Long> record : records) {
long beginTimeNs = record.value();
int value = record.key();
outQ.send(new ProducerRecord<>(topic, value + 1, beginTimeNs));
}
}
Die Verwendung von record key() zum Übertragen eines int-Werts mag etwas unorthodox sein, ermöglicht uns jedoch, die Leistung zu verbessern und den Code zu vereinfachen.
Chronik-Warteschlange
while (!shutDown.get()) {
try (final DocumentContext rdc = tailer.readingDocument()) {
if (rdc.isPresent()) {
ValueIn valueIn = rdc.wire().getValueIn();
long beginTime = valueIn.readLong();
int value = valueIn.readInt();
try (final DocumentContext wdc =
appender.writingDocument()) {
final ValueOut valueOut = wdc.wire().getValueOut();
valueOut.writeLong(beginTime);
valueOut.writeInt(value + 1);
}
} else {
LockSupport.parkNanos(INTER_MESSAGE_TIME_NS / 8);
}
}
}
Benchmarks
Die Benchmarks hatten eine anfängliche Aufwärmphase, während der der C2-Compiler der JVM Code für eine viel bessere Leistung profilierte und kompilierte. Die Probenahmeergebnisse aus der Aufwärmphase wurden verworfen.
Immer mehr Testinstanzen wurden manuell gestartet (jede mit ihren eigenen fünf Diensten), bis die Latenzanforderungen nicht mehr erfüllt werden konnten. Während der Ausführung der Benchmarks wurde auch die CPU-Auslastung für alle Instanzen mit dem „top“-Befehl beobachtet und über wenige Sekunden gemittelt.
Die Benchmarks berücksichtigten keine koordinierte Auslassung und wurden auf Ubuntu Linux (5.11.0-49-generic) mit AMD Ryzen 9 5950X 16-Core-Prozessoren bei 3,4 GHz mit 64 GB RAM ausgeführt, wobei die Anwendungen auf den isolierten Kernen 2 ausgeführt wurden -8 (insgesamt 7 CPU-Kerne) und Warteschlangen wurden auf einem 1-TB-NVMe-Flash-Gerät gespeichert. Es wurde OpenJDK 11 (11.0.14.1) verwendet.
Alle Latenzzahlen sind in ms angegeben, 99 % bedeutet 99-Perzentil und 99,9 % bedeutet 99,9-Perzentil.
Kafka
Der Kafka-Broker und die Benchmarks wurden alle mit dem Präfix „taskset -c 2-8“ gefolgt von dem entsprechenden Befehl ausgeführt (zB tasket -c 2-8 mvn exec:java@Kafka). Die folgenden Ergebnisse wurden für Kafka:
| Instanzen | erhaltenmittlere Latenz | 99 % | 99,9 % | CPU-Auslastung |
| 1 | 0,9 | 19 | 30 | 670 % |
| 2 | 16 | 72 | 106 (*) | 700 % (gesättigt) |
Tabelle 1, zeigt Kafka-Instanzen im Vergleich zu Latenzen und CPU-Auslastung.
(*) Über 100 ms auf dem 99,9-Perzentil.
Wie zu sehen ist, konnte nur eine Instanz des EDA-Systems gleichzeitig ausgeführt werden. Das Ausführen von zwei Instanzen erhöhte das 99,9-Perzentil, sodass die Grenze von 100 ms überschritten wurde. Die Instanzen und der Kafka-Broker sättigten schnell die verfügbaren CPU-Ressourcen.
Hier ist eine Momentaufnahme der Ausgabe des Befehls „top“, wenn zwei Instanzen und ein Broker ausgeführt werden (PID 3132946):
3134979 per.min+ 20 0 20.5g 1.6g 20508 S 319.6 2.6 60:27.40 java 3142126 per.min+ 20 0 20.5g 1.6g 20300 S 296.3 2.5 19:36.17 java 3132946 per.min+ 20 0 11.3g 1.0g 22056 S 73.8 1.6 9:22.42 java
Chronik-Warteschlange
Die Benchmarks wurden mit dem Befehl „taskset -c 2-8 mvn exec:java@ChronicleQueue“ ausgeführt und die folgenden Ergebnisse wurden erzielt:
| Instanzen | mittlere Latenz | 99 % | 99,9 % | CPU-Auslastung |
| 1 | 0,5 | 0,8 | 0,9 | 5,2 % |
| 10 | 0,5 | 0,9 | 0,9 | 79 % |
| 25 | 0,5 | 0,9 | 3.6 | 180 % |
| 50 | 0,5 | 0,9 | 5.0 | 425 % |
| 100 | 1.0 | 5 | 20 | 700 % (gesättigt) |
| 150 | 2.0 | 7 | 53 | 700 % (gesättigt) |
| 200 | 3.1 | 9 | 59 | 700 % (gesättigt) |
| 250 | 4.8 | 12 | 62 | 700 % (gesättigt) |
| 375 | 8.7 | 23 | 75 | 700 % (gesättigt) |
| 500 | 11 | 36 | 96 | 700 % (gesättigt) |
Tabelle 2, zeigt Chronicle-Warteschlangeninstanzen im Vergleich zu Latenzen und CPU-Auslastung.
Die schiere Effizienz von Chronicle Queue wird in diesen Benchmarks deutlich, wenn 500 Instanzen gleichzeitig ausgeführt werden können, was bedeutet, dass wir 3.000 gleichzeitige Warteschlangen und 3.000.000 Nachrichten pro Sekunde auf nur 7 Kernen mit weniger als 100 ms Verzögerung beim 99,9-Perzentil verarbeiten.
Vergleich
Hier ist ein Diagramm, das die Anzahl der Instanzen im Vergleich zum 99,9-Perzentil für die beiden verschiedenen Warteschlangentypen zeigt: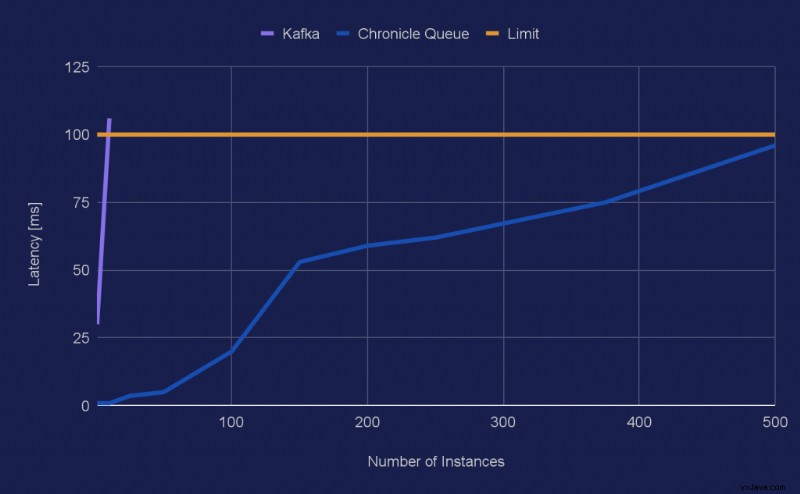
Wie zu sehen ist, geht die Kurve für Kafka in nur einem Schritt von 30 ms auf 106 ms, sodass das Latenzwachstum für Kafka in dieser Größenordnung wie eine Wand aussieht.
Schlussfolgerung
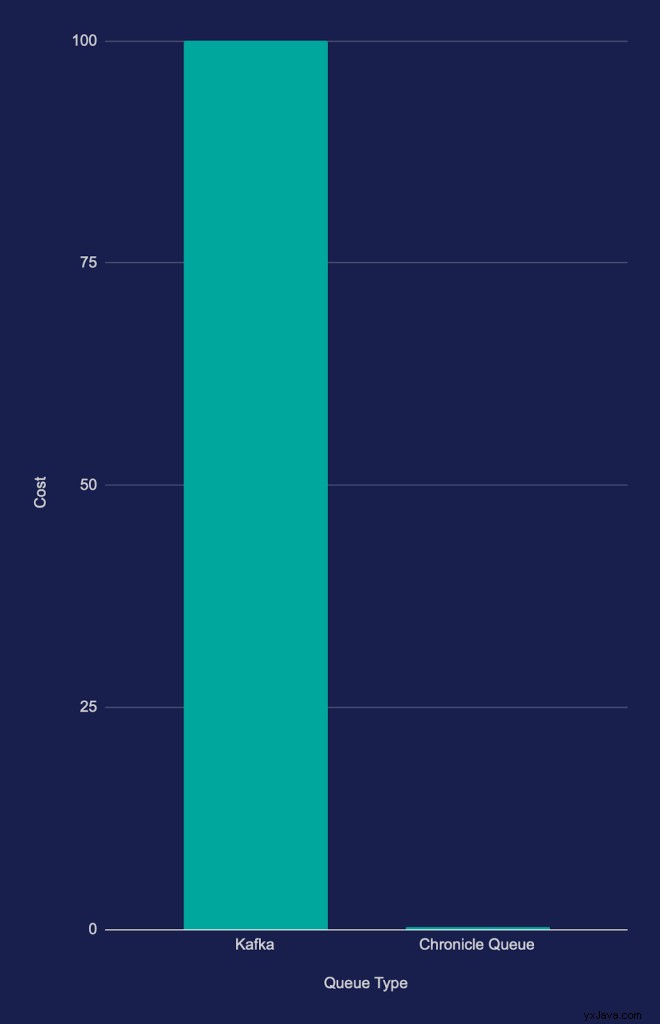
Etwa vierhundert Mal mehr Anwendungen können auf derselben Hardware ausgeführt werden, wenn für bestimmte latenzempfindliche EDA-Anwendungen von Kafka auf Chronicle Queue umgestellt wird.
Etwa vierhundertmal mehr Anwendungen entsprechen einem Potenzial zur Reduzierung der Cloud- oder Hardwarekosten um etwa 99,8 %, wie in Diagramm 2 unten dargestellt (weniger ist besser). Tatsächlich sind die Kosten in der verwendeten Skala kaum zu erkennen: