Ereignisgesteuerte Microservices mit Spring Cloud Stream
In letzter Zeit habe ich mich viel mit ereignisgesteuerten Architekturen beschäftigt, weil ich glaube, dass dies der beste Ansatz für Microservices ist, der viel stärker entkoppelte Dienste als Punkt-zu-Punkt-Kommunikation ermöglicht. Es gibt zwei Hauptansätze für ereignisgesteuerte Kommunikation:
- Feed :Jede Anwendung hat einen (synchronen) Endpunkt, von dem jeder Domänenereignisse in Form eines Feeds abrufen kann.
- Makler :Es gibt einen dedizierten Broker, der für die Verteilung der Ereignisse verantwortlich ist, wie Kafka.
Jeder Ansatz hat seine Vor- und Nachteile. Mit einem Broker müssen Sie mehr Infrastruktur handhaben, aber Sie haben auch einen zentralen Ort, an dem Ihre Ereignisse gespeichert werden. Auf Feeds kann nicht zugegriffen werden, wenn die produzierende Anwendung heruntergefahren ist. Die Skalierung ist mit einem Broker einfacher – was passiert, wenn Sie Ihre verbrauchenden Anwendungen plötzlich wegen Last verdoppeln müssen? Wer abonniert den Feed? Wenn beide abonnieren, werden Ereignisse zweimal verarbeitet. Mit einem Broker wie Kafka erstellen Sie ganz einfach Verbrauchergruppen, und jedes Ereignis wird nur von einer Anwendung dieser Gruppe verarbeitet. Also haben wir den Maklerweg vorgezogen und uns für Kafka entschieden.
Soweit so gut – aber wir waren ungeduldig. Wir wollten etwas über ereignisgesteuerte Architekturen lernen, wir wollten nicht wochenlang mit Kafka kämpfen. Und da kam Spring Cloud Stream zur Rettung.
Ja, wir haben ein wenig Zeit damit verbracht, unseren eigenen kleinen Spielplatz mit Docker-Compose einzurichten, einschließlich natürlich Kafka und Zookeeper, aber auch Spring Cloud Config, Spring Boot Admin und ein integriertes Continuous-Delivery-Setup mit Jenkins, Nexus und Sonar. Sie finden es hier:https://github.com/codecentric/event-driven-microservices-platform. Dann dachten wir, dass der schwierige Teil kommen würde – die Verbindung zu und die Verwendung von Kafka. Wir sind über Spring Cloud Stream gestolpert – und die Verwendung von Kafka war eine Sache von Minuten.
Abhängigkeiten
Sie müssen Ihrem Pom eine Abhängigkeit hinzufügen:
<dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-stream-kafka</artifactId> </dependency> |
Als Elternteil verwende ich den spring-cloud-starter-parent in der aktuellsten Version (zum Zeitpunkt des Schreibens von Brixton.RC1 ). Es löst die gesamte Versionsverwaltung für mich.
<parent> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-parent</artifactId> <version>Brixton.RC1</version> </parent> |
Bei Verwendung von Actuator fügt Spring Cloud Stream automatisch einen HealthIndicator hinzu für den Kafka-Binder und einen neuen Aktuator-Endpunkt /channels mit allen in der Anwendung verwendeten Kanälen.
Ereignisse produzieren
In unserer Beispielanwendung erzeugen wir alle 10 Sekunden ein Ereignis mit einem Poller.
@SpringBootApplication
@EnableBinding(Source.class)
public class EdmpSampleStreamApplication {
public static void main(String[] args) {
SpringApplication.run(EdmpSampleStreamApplication.class, args);
}
@Bean
@InboundChannelAdapter(value = Source.OUTPUT, poller = @Poller(fixedDelay = "10000", maxMessagesPerPoll = "1"))
public MessageSource<TimeInfo> timerMessageSource() {
return () -> MessageBuilder.withPayload(new TimeInfo(new Date().getTime()+"","Label")).build();
}
public static class TimeInfo{
private String time;
private String label;
public TimeInfo(String time, String label) {
super();
this.time = time;
this.label = label;
}
public String getTime() {
return time;
}
public String getLabel() {
return label;
}
}
} |
@SpringBootApplication @EnableBinding(Source.class) öffentliche Klasse EdmpSampleStreamApplication { public static void main(String[] args) { SpringApplication.run(EdmpSampleStreamApplication.class, args); } @Bean @InboundChannelAdapter(value =Source.OUTPUT, poller =@Poller(fixedDelay ="10000", maxMessagesPerPoll ="1")) public MessageSource
Bei Verwendung von @EnableBinding(Source.class) Spring Cloud Stream erstellt automatisch einen Nachrichtenkanal mit dem Namen output die von @InboundChannelAdapter verwendet wird . Sie können diesen Nachrichtenkanal auch automatisch verdrahten und Nachrichten manuell darauf schreiben. Unsere application.properties sieht so aus:
spring.cloud.stream.bindings.output.destination=timerTopic spring.cloud.stream.bindings.output.content-type=application/json spring.cloud.stream.kafka.binder.zkNodes=kafka spring.cloud.stream.kafka.binder.brokers=kafka
Es besagt im Grunde, dass wir den Ausgabenachrichtenkanal an den Kafka timerTopic binden wollen , und es heißt, dass wir die Nutzlast in JSON serialisieren möchten. Und dann müssen wir Spring Cloud Stream den Hostnamen mitteilen, auf dem Kafka und Zookeeper ausgeführt werden – Standardwerte sind localhost , führen wir sie in einem Docker-Container namens kafka aus .
Konsumierende Ereignisse
Unsere Beispielanwendung zum Konsumieren von Ereignissen sieht folgendermaßen aus:
@SpringBootApplication
@EnableBinding(Sink.class)
public class EdmpSampleStreamSinkApplication {
private static Logger logger = LoggerFactory.getLogger(EdmpSampleStreamSinkApplication.class);
public static void main(String[] args) {
SpringApplication.run(EdmpSampleStreamSinkApplication.class, args);
}
@StreamListener(Sink.INPUT)
public void loggerSink(SinkTimeInfo sinkTimeInfo) {
logger.info("Received: " + sinkTimeInfo.toString());
}
public static class SinkTimeInfo{
private String time;
private String label;
public String getTime() {
return time;
}
public void setTime(String time) {
this.time = time;
}
public void setSinkLabel(String label) {
this.label = label;
}
public String getLabel() {
return label;
}
@Override
public String toString() {
return "SinkTimeInfo [time=" + time + ", label=" + label + "]";
}
}
} |
@SpringBootApplication @EnableBinding(Sink.class) öffentliche Klasse EdmpSampleStreamSinkApplication { privater statischer Logger logger =LoggerFactory.getLogger(EdmpSampleStreamSinkApplication.class); public static void main(String[] args) {SpringApplication.run(EdmpSampleStreamSinkApplication.class, args); } @StreamListener(Sink.INPUT) public void loggerSink(SinkTimeInfo sinkTimeInfo) { logger.info("Received:" + sinkTimeInfo.toString()); } öffentliche statische Klasse SinkTimeInfo{ private String-Zeit; privates String-Label; public String getTime() { Rückgabezeit; } public void setTime (String time) { this.time =time; } public void setSinkLabel (String label) { this.label =label; } public String getLabel() {Rückgabelabel; } @Override public String toString() { return "SinkTimeInfo [time=" + time + ", label=" + label + "]"; } } }
Bei Verwendung von @EnableBinding(Sink.class) Spring Cloud Stream erstellt automatisch einen Nachrichtenkanal mit dem Namen input die von @StreamListener verwendet wird Oben. Unsere application.properties sehen so aus:
spring.cloud.stream.bindings.input.destination=timerTopic spring.cloud.stream.bindings.input.content-type=application/json spring.cloud.stream.bindings.input.group=timerGroup spring.cloud.stream.kafka.bindings.input.consumer.resetOffsets=true spring.cloud.stream.kafka.binder.zkNodes=kafka spring.cloud.stream.kafka.binder.brokers=kafka
Wir sehen die Bindung von input bis timerTopic , dann sehen wir den Inhaltstyp, den wir erwarten. Beachten Sie, dass wir die Klasse nicht mit der produzierenden Anwendung teilen – wir deserialisieren nur den Inhalt in einer eigenen Klasse.
Dann geben wir die Verbrauchergruppe an, zu der diese Anwendung gehört – also wenn eine andere Instanz dieser Anwendung bereitgestellt wird , Ereignisse werden auf alle Instanzen verteilt.
Für Entwicklungszwecke setzen wir resetOffsets des Kanals input auf true, was bedeutet, dass bei einer neuen Bereitstellung alle Ereignisse erneut verarbeitet werden, da der Kafka-Offset zurückgesetzt wird. Es könnte auch eine Strategie sein, dies bei jedem Start zu tun – den ganzen Zustand nur im Gedächtnis zu haben – und in Kafka. Dann sind Verbrauchergruppen natürlich nicht sinnvoll, und die Verarbeitung der Ereignisse sollte keine anderen Ereignisse erzeugen – die Verarbeitung der Ereignisse wird nur verwendet, um einen internen Zustand zu erzeugen.
Schlussfolgerung
Was kann ich sagen? Spring Cloud Stream war wirklich einfach zu bedienen, und das werde ich sicherlich in Zukunft tun. Wenn Sie es selbst mit einem echten Kafka ausprobieren möchten, kann ich Sie noch einmal auf https://github.com/codecentric/event-driven-microservices-platform verweisen.
Installieren Sie Docker Toolbox, dann tun Sie Folgendes:
$ docker-machine create -d virtualbox --virtualbox-memory "6000" --virtualbox-disk-size "40000" default $ eval "$(docker-machine env default)" $ git clone [email protected]:codecentric/event-driven-microservices-platform.git $ cd event-driven-microservices-platform $ docker-compose up
Holen Sie sich jetzt einen Kaffee, unterhalten Sie sich mit den Kollegen oder surfen Sie im Internet, während Docker es herunterlädt. Gehen Sie dann zu http://${docker-machine ip default}:18080/ und Sie sollten so etwas sehen:
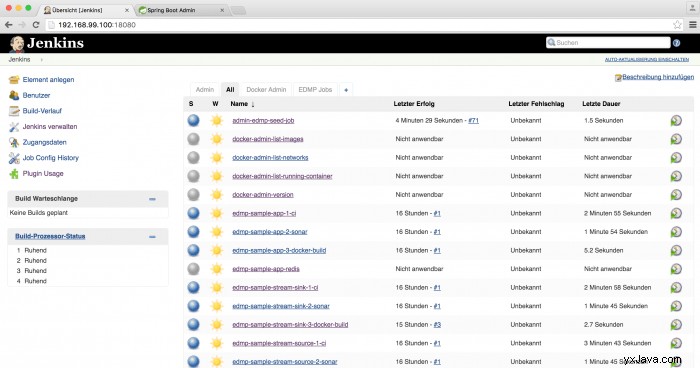
Gehen Sie dann zu Spring Boot Admin unter http://${docker-machine ip default}:10001/ und Sie sollten so etwas sehen:
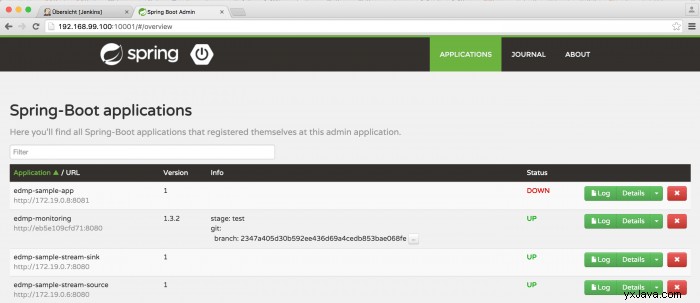
Und wenn Sie sich die Protokolle von edmp-sample-stream-sink ansehen, werden Sie Ich werde die eingehenden Ereignisse sehen.