Spring Data JPA-Tutorial:Einführung
Das Erstellen von Repositories, die die Java Persistence API verwenden, ist ein umständlicher Prozess, der viel Zeit in Anspruch nimmt und eine Menge Boilerplate-Code erfordert. Wir können einige Boilerplate-Codes eliminieren, indem wir diesen Schritten folgen:
- Erstellen Sie eine abstrakte Basis-Repository-Klasse, die CRUD-Operationen für Entitäten bereitstellt.
- Erstellen Sie die konkrete Repository-Klasse, die die abstrakte Basis-Repository-Klasse erweitert.
Das Problem bei diesem Ansatz ist, dass wir immer noch den Code schreiben müssen, der unsere Datenbankabfragen erstellt und aufruft. Erschwerend kommt hinzu, dass wir dies jedes Mal tun müssen, wenn wir eine neue Datenbankabfrage erstellen möchten. Das ist Zeitverschwendung .
Was würden Sie sagen, wenn ich Ihnen sagen würde, dass wir JPA-Repositories erstellen können, ohne Boilerplate-Code zu schreiben?
Die Chancen stehen gut, dass Sie mir vielleicht nicht glauben, aber Spring Data JPA hilft uns dabei, genau das zu tun. Auf der Website des Spring Data JPA-Projekts heißt es:
Die Implementierung einer Datenzugriffsschicht einer Anwendung war lange Zeit umständlich. Es muss zu viel Boilerplate-Code geschrieben werden, um einfache Abfragen sowie Paginierung und Auditing auszuführen. Spring Data JPA zielt darauf ab, die Implementierung von Datenzugriffsschichten erheblich zu verbessern, indem der Aufwand auf das tatsächlich erforderliche Maß reduziert wird. Als Entwickler schreiben Sie Ihre Repository-Schnittstellen, einschließlich benutzerdefinierter Suchmethoden, und Spring stellt die Implementierung automatisch bereit
Dieser Blogbeitrag bietet eine Einführung in Spring Data JPA. Wir werden lernen, was Spring Data JPA wirklich ist, und einen kurzen Blick auf die Spring Data-Repository-Schnittstellen werfen.
Fangen wir an.
Was ist Spring Data JPA?
Spring Data JPA ist kein JPA-Anbieter . Es ist eine Bibliothek / ein Framework, das eine zusätzliche Abstraktionsebene über unserem JPA-Provider hinzufügt. Wenn wir uns für Spring Data JPA entscheiden, enthält die Repository-Schicht unserer Anwendung drei Schichten, die im Folgenden beschrieben werden:
- Spring Data JPA bietet Unterstützung für die Erstellung von JPA-Repositories durch Erweiterung der Spring Data-Repository-Schnittstellen.
- Spring Data Commons stellt die Infrastruktur bereit, die von den datenspeicherspezifischen Spring Data-Projekten gemeinsam genutzt wird.
- Der JPA-Provider implementiert die Java Persistence API.
Die folgende Abbildung veranschaulicht die Struktur unserer Repository-Schicht:

Zunächst scheint es, dass Spring Data JPA unsere Anwendung komplizierter macht, und das stimmt in gewisser Weise. Es fügt unserer Repository-Schicht eine zusätzliche Schicht hinzu, befreit uns aber gleichzeitig davon, Boilerplate-Code zu schreiben.
Das klingt nach einem guten Kompromiss. Recht?
Einführung in Spring Data Repositories
Die Stärke von Spring Data JPA liegt in der Repository-Abstraktion, die vom Spring Data Commons-Projekt bereitgestellt und durch die datenspeicherspezifischen Unterprojekte erweitert wird.
Wir können Spring Data JPA verwenden, ohne auf die tatsächliche Implementierung der Repository-Abstraktion zu achten, aber wir müssen mit den Spring Data-Repository-Schnittstellen vertraut sein. Diese Schnittstellen werden im Folgenden beschrieben:
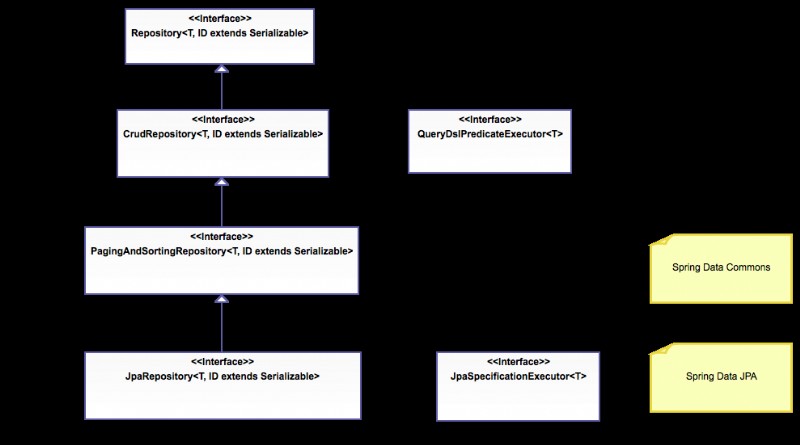
Zuerst stellt das Spring Data Commons-Projekt die folgenden Schnittstellen bereit:
- Das Repository
- Es erfasst den Typ der verwalteten Entität und den Typ der Entitäts-ID.
- Es hilft dem Spring-Container, die "konkreten" Repository-Schnittstellen während des Classpath-Scannens zu erkennen.
- Das CrudRepository
- Das PagingAndSortingRepository
- Der QueryDslPredicateExecutor
Schnittstelle ist keine "Repository-Schnittstelle". Es deklariert die Methoden, die zum Abrufen von Entitäten aus der Datenbank mithilfe von QueryDsl Predicate verwendet werden Objekte.
Zweiter stellt das Spring Data JPA-Projekt die folgenden Schnittstellen bereit:
- Das JpaRepository
- Der JpaSpecificationExecutor
Schnittstelle ist keine "Repository-Schnittstelle". Es deklariert die Methoden, die zum Abrufen von Entitäten aus der Datenbank verwendet werden, indem Specification verwendet wird Objekte, die die JPA-Kriterien-API verwenden.
Die Repository-Hierarchie sieht wie folgt aus:
Das ist schön, aber wie können wir sie nutzen?
Das ist eine berechtigte Frage. Die nächsten Teile dieses Tutorials werden diese Frage beantworten, aber im Wesentlichen müssen wir diesen Schritten folgen:
- Erstellen Sie eine Repository-Schnittstelle und erweitern Sie eine der von Spring Data bereitgestellten Repository-Schnittstellen.
- Fügen Sie der erstellten Repository-Schnittstelle benutzerdefinierte Abfragemethoden hinzu (falls wir sie brauchen).
- Injizieren Sie die Repository-Schnittstelle in eine andere Komponente und verwenden Sie die Implementierung, die automatisch von Spring bereitgestellt wird.
Fahren wir fort und fassen zusammen, was wir aus diesem Blogbeitrag gelernt haben.
Zusammenfassung
Dieser Blogpost hat uns zwei Dinge gelehrt:
- Spring Data JPA ist kein JPA-Anbieter. Es "versteckt" einfach die Java Persistence API (und den JPA-Provider) hinter seiner Repository-Abstraktion.
- Spring Data bietet mehrere Repository-Schnittstellen, die für unterschiedliche Zwecke verwendet werden.
Der nächste Teil dieses Tutorials beschreibt, wie wir die erforderlichen Abhängigkeiten erhalten können.