Schritt für Schritt Spring Batch Tutorial
In diesem Beitrag möchte ich zeigen, wie Sie Spring Batch verwenden können. Dies ist ein schrittweises Spring Batch Tutorial.
In Unternehmensanwendungen ist die Stapelverarbeitung üblich. Aber mit der zunehmenden Verbreitung von Daten im Internet ist es auch wichtig geworden, wie wir diese Daten verarbeiten. Es sind mehrere Lösungen verfügbar. Apache Storm oder Apache Spark helfen bei der Verarbeitung und Umwandlung der Daten in das erforderliche Format. In diesem Beitrag werden wir uns Spring Batch genauer ansehen.
Was ist Spring Batch?
Spring Batch ist ein leichtgewichtiges Framework, das zur Erleichterung der Stapelverarbeitung entwickelt wurde . Es ermöglicht Entwicklern, Batch-Anwendungen zu erstellen. Diese Stapelanwendungen verarbeiten wiederum die eingehenden Daten und wandeln sie für die weitere Verwendung um.
Ein weiterer großer Vorteil des Einsatzes von Spring Batch ist die performante Verarbeitung dieser Daten. Bei Anwendungen, die stark auf Daten angewiesen sind, ist es von größter Bedeutung, dass Daten sofort verfügbar sind.
Spring Batch ermöglicht es einem Entwickler, einen POJO-basierten Ansatz zu verwenden. Bei diesem Ansatz kann ein Entwickler die stapelverarbeiteten Daten in Datenmodelle umwandeln, die er für die Anwendungsgeschäftslogik weiter verwenden kann.
In diesem Beitrag werde ich ein Beispiel behandeln, bei dem wir eine datenintensive CSV-Datei für Mitarbeiterdatensätze stapelweise verarbeiten und diese Daten transformieren und validieren, um sie in unsere Datenbank zu laden.
Was ist Stapelverarbeitung?
Stapelverarbeitung ist ein Datenverarbeitungsmodus. Dabei werden alle Daten konsumiert, diese Daten verarbeitet, transformiert und dann an eine andere Datenquelle gesendet. Normalerweise geschieht dies durch einen automatisierten Job. Entweder ein auslösendes System oder ein Benutzer löst einen Job aus und dieser Job verarbeitet die Jobdefinition. Bei der Jobdefinition geht es darum, die Daten aus ihrer Quelle zu konsumieren.
Der Hauptvorteil der Stapelverarbeitung besteht darin, dass große Datenmengen verarbeitet werden. Trotzdem kann dieser Vorgang asynchron sein. Die meisten Anwendungen führen die Stapelverarbeitung getrennt von der Benutzerinteraktion in Echtzeit durch.
Als Nächstes lernen wir das Spring Batch-Framework und seine Bestandteile kennen.
Spring Batch Framework
Die folgende Architektur zeigt die Komponenten des Spring Batch-Frameworks.
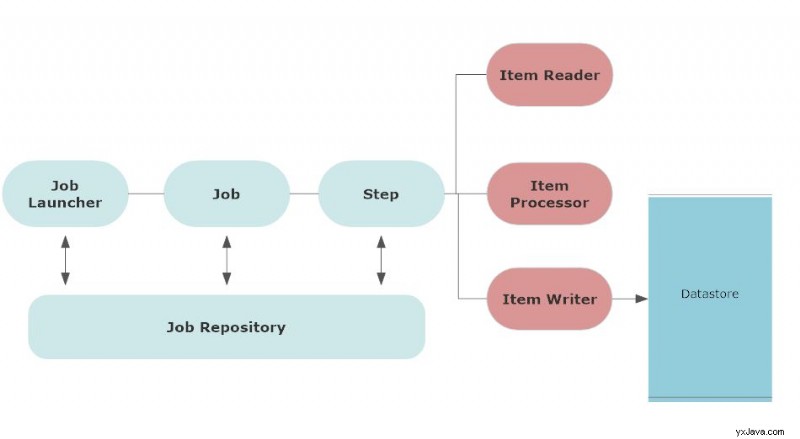
Erstens beinhaltet der Batch-Prozess einen Job. Der Benutzer plant, dass ein Job zu einer bestimmten Zeit oder basierend auf einer bestimmten Bedingung ausgeführt wird. Dabei kann es sich auch um einen Job-Trigger handeln.
Das Spring Batch-Framework enthält auch
- Protokollierung und Verfolgung
- Transaktionsverwaltung
- Auftragsverarbeitungsstatistiken
- Auftragsneustart
- Ressourcenverwaltung
Wenn Sie einen Job konfigurieren, wird er normalerweise im Job-Repository gespeichert. Job-Repository speichert die Metadaten aller Jobs. Ein Trigger startet diese Jobs zur geplanten Zeit.
Ein Job Launcher ist eine Schnittstelle, um einen Job zu starten oder einen Job auszuführen, wenn die geplante Zeit des Jobs eintrifft.
Stelle wird mit Jobparametern definiert. Wenn ein Job startet, wird eine Jobinstanz für diesen Job ausgeführt. Jede Ausführung einer Jobinstanz hat eine Jobausführung und verfolgt den Status des Jobs. Ein Job kann mehrere Schritte haben.
Schritt ist eine eigenständige Phase einer Tätigkeit. Ein Job kann aus mehr als einem Schritt bestehen. Ähnlich wie beim Job hat jeder Schritt eine Schrittausführung, die den Schritt ausführt und den Status des Schritts verfolgt.
Jeder Schritt hat einen Artikelleser der im Wesentlichen die Eingabedaten liest, ein Elementprozessor der die Daten verarbeitet und umwandelt, und einen Elementschreiber der die verarbeiteten Daten aufnimmt und ausgibt.
Sehen wir uns nun all diese Komponenten in unserer Demo an.
Step by Step Spring Batch Tutorial mit einem Beispiel
Als Teil der Demo werden wir eine CSV-Datei über Spring Batch Framework hochladen. Erstellen Sie also zunächst das Spring-Projekt und fügen Sie die folgende Abhängigkeit hinzu:
implementation 'org.springframework.boot:spring-boot-starter-batch'
Dies ist die Hauptabhängigkeit unseres Projekts. Auch unsere Hauptanwendung wird wie folgt aussehen:
package com.betterjavacode.springbatchdemo;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
public class SpringbatchdemoApplication
{
public static void main(String[] args)
{
SpringApplication.run(SpringbatchdemoApplication.class, args);
}
}
DTO-Objekt erstellen
Ich werde Mitarbeiterdaten über eine CSV-Datei hochladen, daher werde ich mein DTO-Objekt für Mitarbeiter wie folgt erstellen:
package com.betterjavacode.springbatchdemo.dtos;
import com.betterjavacode.springbatchdemo.models.Company;
import com.betterjavacode.springbatchdemo.models.Employee;
import com.betterjavacode.springbatchdemo.repositories.CompanyRepository;
import org.springframework.beans.factory.annotation.Autowired;
import java.io.Serializable;
public class EmployeeDto implements Serializable
{
private static final long serialVersionUID = 710566148641281929L;
@Autowired
public CompanyRepository companyRepository;
private int employeeId;
private int companyId;
private String firstName;
private String lastName;
private String email;
private String jobTitle;
public EmployeeDto()
{
}
public EmployeeDto(int employeeId, String firstName, String lastName, String email,
String jobTitle, int companyId)
{
this.employeeId = employeeId;
this.firstName = firstName;
this.lastName = lastName;
this.email = email;
this.jobTitle = jobTitle;
this.companyId = companyId;
}
public Employee employeeDtoToEmployee()
{
Employee employee = new Employee();
employee.setEmployeeId(this.employeeId);
employee.setFirstName(this.firstName);
employee.setLastName(this.lastName);
employee.setEmail(this.email);
Company company = companyRepository.findById(this.companyId).get();
employee.setCompany(company);
employee.setJobTitle(this.jobTitle);
return employee;
}
public int getEmployeeId ()
{
return employeeId;
}
public void setEmployeeId (int employeeId)
{
this.employeeId = employeeId;
}
public int getCompanyId ()
{
return companyId;
}
public void setCompanyId (int companyId)
{
this.companyId = companyId;
}
public String getFirstName ()
{
return firstName;
}
public void setFirstName (String firstName)
{
this.firstName = firstName;
}
public String getLastName ()
{
return lastName;
}
public void setLastName (String lastName)
{
this.lastName = lastName;
}
public String getEmail ()
{
return email;
}
public void setEmail (String email)
{
this.email = email;
}
public String getJobTitle ()
{
return jobTitle;
}
public void setJobTitle (String jobTitle)
{
this.jobTitle = jobTitle;
}
}
Diese DTO-Klasse verwendet auch ein Repository CompanyRepository um ein Firmenobjekt zu erhalten und DTO in ein Datenbankobjekt umzuwandeln.
Einrichten der Spring Batch-Konfiguration
Jetzt richten wir eine Stapelkonfiguration für unseren Job ein, der ausgeführt wird, um eine CSV-Datei in die Datenbank hochzuladen. Unsere Klasse BatchConfig eine Anmerkung @EnableBatchProcessing enthalten . Diese Anmerkung aktiviert Spring Batch-Funktionen und bietet eine Basiskonfiguration zum Einrichten von Batch-Jobs in einem @Configuration Klasse.
@Configuration
@EnableBatchProcessing
public class BatchConfig
{
}
Diese Stapelkonfiguration enthält eine Definition unseres Jobs und der Schritte, die an dem Job beteiligt sind. Es wird auch beinhalten, wie wir unsere Dateidaten lesen und weiterverarbeiten wollen.
@Bean
public Job processJob(Step step)
{
return jobBuilderFactory.get("processJob")
.incrementer(new RunIdIncrementer())
.listener(listener())
.flow(step).end().build();
}
@Bean
public Step orderStep1(JdbcBatchItemWriter writer)
{
return stepBuilderFactory.get("orderStep1").<EmployeeDto, EmployeeDto> chunk(10)
.reader(flatFileItemReader())
.processor(employeeItemProcessor())
.writer(writer).build();
}
Die obige Bean deklariert den Job processJob . incrementer fügt Auftragsparameter hinzu. listener hört auf den Job und verarbeitet den Jobstatus. Die Bohne für listener verarbeitet die Benachrichtigung über den Abschluss des Jobs oder das Fehlschlagen eines Jobs. Wie in der Spring Batch-Architektur besprochen, umfasst jeder Job mehr als einen Schritt.
@Bean für step verwendet stepBuilderFactory einen Schritt zu erstellen. Dieser Schritt verarbeitet einen Datenblock in einer Größe von 10. Er hat einen Flat File Reader flatFileItemReader() . Ein Prozessor employeeItemReader verarbeitet die Daten, die vom Flat File Item Reader gelesen wurden.
@Bean
public FlatFileItemReader flatFileItemReader()
{
return new FlatFileItemReaderBuilder()
.name("flatFileItemReader")
.resource(new ClassPathResource("input/employeedata.csv"))
.delimited()
.names(format)
.linesToSkip(1)
.lineMapper(lineMapper())
.fieldSetMapper(new BeanWrapperFieldSetMapper(){{
setTargetType(EmployeeDto.class);
}})
.build();
}
@Bean
public LineMapper lineMapper()
{
final DefaultLineMapper defaultLineMapper = new DefaultLineMapper<>();
final DelimitedLineTokenizer delimitedLineTokenizer = new DelimitedLineTokenizer();
delimitedLineTokenizer.setDelimiter(",");
delimitedLineTokenizer.setStrict(false);
delimitedLineTokenizer.setNames(format);
defaultLineMapper.setLineTokenizer(delimitedLineTokenizer);
defaultLineMapper.setFieldSetMapper(employeeDtoFieldSetMapper);
return defaultLineMapper;
}
@Bean
public EmployeeItemProcessor employeeItemProcessor()
{
return new EmployeeItemProcessor();
}
@Bean
public JobExecutionListener listener()
{
return new JobCompletionListener();
}
@Bean
public JdbcBatchItemWriter writer(final DataSource dataSource)
{
return new JdbcBatchItemWriterBuilder()
.itemSqlParameterSourceProvider(new BeanPropertyItemSqlParameterSourceProvider<>())
.sql("INSERT INTO employee(employeeId, firstName, lastName, jobTitle, email, " +
"companyId) VALUES(:employeeId, :firstName, :lastName, :jobTitle, :email," +
" " +
":companyId)")
.dataSource(dataSource)
.build();
}
Wir werden uns jetzt jede dieser Bohnen ansehen.
FlatFileItemReader liest die Daten aus der Flatfile. Wir verwenden einen FlatFileItemReaderBuilder, um einen FlatFileItemReader vom Typ EmployeeDto zu erstellen .
resource gibt den Speicherort der Datei an.
delimited – Dies erstellt einen begrenzten Tokenizer.
names – zeigt die Reihenfolge der Felder in der Datei an.
lineMapper ist eine Schnittstelle, um Zeilen von einer Datei auf ein Domänenobjekt abzubilden.
fieldSetMapper ordnet die Daten aus Fieldset einem Objekt zu.
lineMapper Bean benötigt Tokenizer und Fieldsetmapper.
employeeDtoFieldSetMapper ist eine weitere Bohne, die wir in dieser Klasse automatisch verdrahtet haben.
package com.betterjavacode.springbatchdemo.configurations.processor;
import com.betterjavacode.springbatchdemo.dtos.EmployeeDto;
import org.springframework.batch.item.file.mapping.FieldSetMapper;
import org.springframework.batch.item.file.transform.FieldSet;
import org.springframework.stereotype.Component;
import org.springframework.validation.BindException;
@Component
public class EmployeeDtoFieldSetMapper implements FieldSetMapper
{
@Override
public EmployeeDto mapFieldSet (FieldSet fieldSet) throws BindException
{
int employeeId = fieldSet.readInt("employeeId");
String firstName = fieldSet.readRawString("firstName");
String lastName = fieldSet.readRawString("lastName");
String jobTitle = fieldSet.readRawString("jobTitle");
String email = fieldSet.readRawString("email");
int companyId = fieldSet.readInt("companyId");
return new EmployeeDto(employeeId, firstName, lastName, jobTitle, email, companyId);
}
}
Wie Sie sehen können, ordnet dieser FieldSetMapper Felder einzelnen Objekten zu, um einen EmployeeDto zu erstellen .
EmployeeItemProcessor implementiert die Schnittstelle ItemProcessor . Grundsätzlich validieren wir in dieser Klasse EmployeeDto Daten, um zu überprüfen, ob das Unternehmen, dem der Mitarbeiter angehört, existiert.
JobCompletionListener prüft den Abschlussstatus des Jobs.
@Override
public void afterJob(JobExecution jobExecution)
{
if (jobExecution.getStatus() == BatchStatus.COMPLETED)
{
// Log statement
System.out.println("BATCH JOB COMPLETED SUCCESSFULLY");
}
}
Schauen wir uns nun ItemWriter an . Diese Bean verwendet grundsätzlich JdbcBatchItemWriter . JdbcBatchItemWriter verwendet INSERT SQL-Anweisung zum Einfügen des verarbeiteten EmployeeDto Daten in die konfigurierte Datenquelle.
Anwendungseigenschaften konfigurieren
Bevor wir unsere Anwendung ausführen, um eine Datei zu verarbeiten, schauen wir uns application.properties an .
spring.datasource.url=jdbc:mysql://127.0.0.1/springbatchdemo?autoReconnect=true&useSSL=false
spring.datasource.username = root
spring.datasource.password=*******
spring.datasource.driver-class-name=com.mysql.cj.jdbc.Driver
spring.jpa.show-sql=true
spring.jpa.properties.hibernate.dialect = org.hibernate.dialect.MySQL5Dialect
spring.datasource.hikari.connection-test-query=SELECT 1
spring.batch.initialize-schema=ALWAYS
Anders als normale Datenquelleneigenschaften sollten wir die Eigenschaft spring.batch.initialize-schema=ALWAYS verstehen . Wenn wir diese Eigenschaft nicht verwenden und die Anwendung starten, wird die Anwendung Table batch_job_instance doesn't exist beanstanden .
Um diesen Fehler zu vermeiden, raten wir grundsätzlich dazu, beim Start Batch-Job-bezogene Metadaten zu erstellen. Diese Eigenschaft erstellt zusätzliche Datenbanktabellen in Ihrer Datenbank wie batch_job_execution , batch_job_execution_context , batch_job_execution_params , batch_job_instance usw.
Demo
Wenn ich jetzt meine Spring Boot-Anwendung ausführe, wird sie ausgeführt und der Job ausgeführt. Es gibt verschiedene Möglichkeiten, einen Job auszulösen. In einer Unternehmensanwendung erhalten Sie eine Datei oder Daten an einem Speicherort (S3 oder Amazon SNS-SQS) und Sie haben einen Job, der diesen Speicherort überwacht, um den Spring Batch-Job zum Laden der Datei auszulösen.
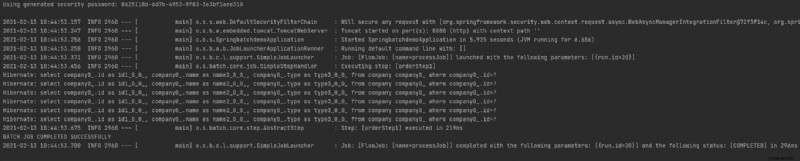
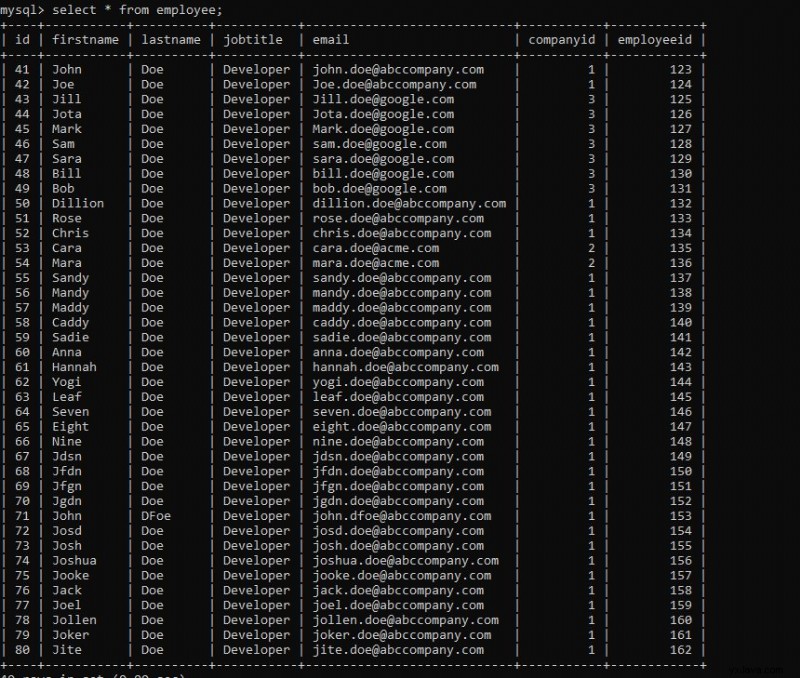
Sie können in der Ausführung eine Meldung über den Abschluss des Jobs sehen – „BATCH JOB ERFOLGREICH ABGESCHLOSSEN “. Wenn wir unsere Datenbanktabelle überprüfen, sehen wir die geladenen Daten.
Sie können den Code für diese Demo aus meinem Github-Repository herunterladen.
Was noch?
Ich habe hier ein Spring Batch-Tutorial behandelt, aber das ist noch nicht alles. Spring Batch bietet mehr als nur diesen einführenden Teil. Sie können verschiedene Eingabedatenquellen haben oder Sie können die Daten auch von Datei zu Datei mit verschiedenen Datenverarbeitungsregeln laden.
Es gibt auch Möglichkeiten, diese Jobs zu automatisieren und ein hohes Datenvolumen performant zu verarbeiten.
Schlussfolgerung
In diesem Beitrag habe ich ein schrittweises Spring Batch Tutorial gezeigt. Es gibt viele Möglichkeiten, Batch-Jobs zu handhaben, aber Spring Batch hat dies sehr einfach gemacht.
Außerdem habe ich vor Kurzem mein neues Buch „Simplifying Spring Security“ veröffentlicht. Wenn Sie mehr über Spring Security erfahren möchten, können Sie das Buch hier kaufen. Begleiten Sie dieses Buch mit diesem Post mit Fragen zu Spring-Boot-Interviews und Sie sind bereit für Ihr nächstes Vorstellungsgespräch.