Eine vollständige Anleitung zur Verwendung von ElasticSearch mit Spring Boot
In diesem Beitrag werde ich die Details zur Verwendung von Elasticsearch mit Spring Boot behandeln. Ich werde auch die Grundlagen von Elasticsearch behandeln und wie es in der Branche verwendet wird.
Was ist Elasticsearch?
Elasticsearch ist eine verteilte, kostenlose und offene Such- und Analysemaschine für alle Arten von Daten, einschließlich textueller, numerischer, räumlicher, strukturierter und unstrukturierter Daten.
Es basiert auf Apache Lucene. Elasticsearch ist oft Teil des ELK-Stacks (Elastic, LogStash und Kibana). Man kann Elasticsearch verwenden, um Daten für
zu speichern, zu suchen und zu verwalten- Protokolle
- Metriken
- Ein Such-Backend
- Anwendungsüberwachung
Die Suche ist in vielen Bereichen mit ständig wachsenden Datenmengen zu einem zentralen Begriff geworden. Da die meisten Anwendungen datenintensiv werden, ist es wichtig, große Datenmengen schnell und flexibel zu durchsuchen. ElasticSearch bietet beides.
In diesem Beitrag werden wir uns Spring Data Elasticsearch ansehen. Es bietet eine einfache Schnittstelle zum Suchen, Speichern und Ausführen von Analysevorgängen. Wir zeigen, wie wir Spring Data verwenden können, um Protokolldaten zu indizieren und zu durchsuchen.
Schlüsselkonzepte von Elasticsearch
Elasticsearch hat Indizes, Dokumente und Felder. Die Idee ist einfach und Datenbanken sehr ähnlich. Elasticsearch speichert Daten als Dokumente (Zeilen) in Indizes (Datenbanktabellen). Ein Benutzer kann diese Daten mithilfe von Feldern durchsuchen (Spalten).
Normalerweise durchlaufen die Daten in Elasticsearch verschiedene Analysatoren, um diese Daten aufzuteilen. Der Standardanalysator teilt die Daten nach Satzzeichen wie Leerzeichen oder Komma auf.
Wir werden spring-data-elasticsearch verwenden Bibliothek, um die Demo dieses Beitrags zu erstellen. In Spring Data ist ein Dokument nichts anderes als ein POJO-Objekt. Wir werden verschiedene Anmerkungen von Elasticsearch in derselben Klasse hinzufügen.
Wie bereits erwähnt, kann Elasticsearch verschiedene Arten von Daten speichern. Trotzdem werden wir uns in dieser Demo die einfachen Textdaten ansehen.
Spring Boot-Anwendung erstellen
Lassen Sie uns eine einfache Spring-Boot-Anwendung erstellen. Wir werden spring-data-elasticsearch verwenden Abhängigkeit.
dependencies {
implementation 'org.springframework.boot:spring-boot-starter-data-elasticsearch'
implementation 'org.springframework.boot:spring-boot-starter-thymeleaf'
implementation 'org.springframework.boot:spring-boot-starter-web'
testImplementation 'org.springframework.boot:spring-boot-starter-test'
}
Anschließend müssen wir die Elasticsearch-Client-Bean erstellen. Nun gibt es zwei Möglichkeiten, diese Bean zu erstellen.
Die einfache Methode zum Hinzufügen dieser Bean besteht darin, die Eigenschaften in application.properties hinzuzufügen .
spring.elasticsearch.rest.uris=localhost:9200
spring.elasticsearch.rest.connection-timeout=1s
spring.elasticsearch.rest.read-timeout=1m
spring.elasticsearch.rest.password=
spring.elasticsearch.rest.username=
Aber in unserer Anwendung werden wir diese Bean programmgesteuert erstellen. Wir werden Java High-Level Rest Client (JHLC) verwenden. JHLC ist ein Standardclient von Elasticsearch.
@Configuration
@EnableElasticsearchRepositories
public class ElasticsearchClientConfiguration extends AbstractElasticsearchConfiguration
{
@Override
@Bean
public RestHighLevelClient elasticsearchClient ()
{
final ClientConfiguration clientConfiguration =
ClientConfiguration.builder().connectedTo("localhost:9200").build();
return RestClients.create(clientConfiguration).rest();
}
}
Von nun an haben wir eine Client-Konfiguration, die auch Eigenschaften von application.properties verwenden kann . Wir verwenden RestClients um elasticsearchClient zu erstellen .
Außerdem verwenden wir LogData als unser Modell. Grundsätzlich werden wir ein Dokument für LogData erstellen in einem Index speichern.
@Document(indexName = "logdataindex")
public class LogData
{
@Id
private String id;
@Field(type = FieldType.Text, name = "host")
private String host;
@Field(type = FieldType.Date, name = "date")
private Date date;
@Field(type = FieldType.Text, name = "message")
private String message;
@Field(type = FieldType.Double, name = "size")
private double size;
@Field(type = FieldType.Text, name = "status")
private String status;
// Getters and Setters
}
@Document– gibt unseren Index an.@Id– stellt das Feld _id unseres Dokuments dar und ist für jede Nachricht eindeutig.@Field– stellt einen anderen Feldtyp dar, der in unseren Daten enthalten sein könnte.
Es gibt zwei Möglichkeiten, einen Index mit Elasticsearch zu suchen oder zu erstellen –
- Spring Data Repository verwenden
- Verwendung von ElasticsearchRestTemplate
Spring Data Repository mit Elasticsearch
Insgesamt ermöglicht uns Spring Data Repository das Erstellen von Repositories, die wir zum Schreiben einfacher CRUD-Methoden zum Suchen oder Indizieren in Elasticsearch verwenden können. Wenn Sie jedoch mehr Kontrolle über die Abfragen wünschen, sollten Sie vielleicht ElasticsearchRestTemplate verwenden . Insbesondere können Sie damit effizientere Abfragen schreiben.
public interface LogDataRepository extends ElasticsearchRepository<LogData, String>
{
}
Dieses Repository bietet grundlegende CRUD-Methoden, um die sich Spring aus Implementierungsperspektive kümmert.
Verwendung von ElasticsearchRestTemplate
Wenn wir erweiterte Abfragen wie Aggregation und Vorschläge verwenden möchten, können wir ElasticsearchRestTemplate verwenden . Die Spring Data-Bibliothek stellt diese Vorlage bereit.
public List getLogDatasByHost(String host) {
Query query = new NativeSearchQueryBuilder()
.withQuery(QueryBuilders.matchQuery("host", host))
.build();
SearchHits searchHits = elasticsearchRestTemplate.search(query, LogData.class);
return searchHits.get().map(SearchHit::getContent).collect(Collectors.toList());
}
Ich werde weiter die Verwendung von ElasticsearchRestTemplate zeigen wenn wir komplexere Abfragen durchführen.
ElasticsearchRestTemplate implementiert ElasticsearchOperations . Es gibt Schlüsselabfragen, die Sie mit ElasticsearchRestTemplate verwenden können das macht die Verwendung im Vergleich zu Spring Data Repositories einfacher.
index() ODER bulkIndex() ermöglichen die Erstellung eines einzelnen Indexes oder von Indizes in großen Mengen. Man kann ein Indexabfrageobjekt bauen und es in index() verwenden Methodenaufruf.
private ElasticsearchRestTemplate elasticsearchRestTemplate;
public List createLogData
(final List logDataList) {
List queries = logDataList.stream()
.map(logData ->
new IndexQueryBuilder()
.withId(logData.getId().toString())
.withObject(logData).build())
.collect(Collectors.toList());;
return elasticsearchRestTemplate.bulkIndex(queries,IndexCoordinates.of("logdataindex"));
}
search() Methode hilft bei der Suche nach Dokumenten in einem Index. Man kann Suchoperationen durchführen, indem man Query baut Objekt. Es gibt drei Arten von Query man kann bauen. NativeQuery , CriteriaQuery , und StringQuery .
Controller zurücksetzen, um die Elasticsearch-Instanz abzufragen
Lassen Sie uns einen Rest-Controller erstellen, den wir verwenden, um den Großteil der Daten in unsere Elasticsearch-Instanz hinzuzufügen und dieselbe Instanz abzufragen.
@RestController
@RequestMapping("/v1/betterjavacode/logdata")
public class LogDataController
{
@Autowired
private LogDataService logDataService;
@GetMapping
public List searchLogDataByHost(@RequestParam("host") String host)
{
List logDataList = logDataService.getAllLogDataForHost(host);
return logDataList;
}
@GetMapping("/search")
public List searchLogDataByTerm(@RequestParam("term") String term)
{
return logDataService.findBySearchTerm(term);
}
@PostMapping
public LogData addLogData(@RequestBody LogData logData)
{
return logDataService.createLogDataIndex(logData);
}
@PostMapping("/createInBulk")
public List addLogDataInBulk(@RequestBody List logDataList)
{
return (List) logDataService.createLogDataIndices(logDataList);
}
}
Laufende Elasticsearch-Instanz
Bisher haben wir gezeigt, wie man einen Index erstellt und den Elasticsearch-Client verwendet. Wir haben jedoch nicht gezeigt, dass dieser Client mit unserer Elasticsearch-Instanz verbunden wird.
Wir werden eine Docker-Instanz verwenden, um Elasticsearch in unserer lokalen Umgebung auszuführen. AWS bietet einen eigenen Service zum Ausführen von Elasticsearch.
Um Ihre eigene Docker-Instanz von Elasticsearch auszuführen, verwenden Sie den folgenden Befehl –
docker run -p 9200:9200 -e "discovery.type=single-node" docker.elastic.co/elasticsearch/elasticsearch:7.10.0
Anschließend wird der Knoten Elasticsearch gestartet, den Sie überprüfen können, indem Sie http://localhost:9200 aufrufen
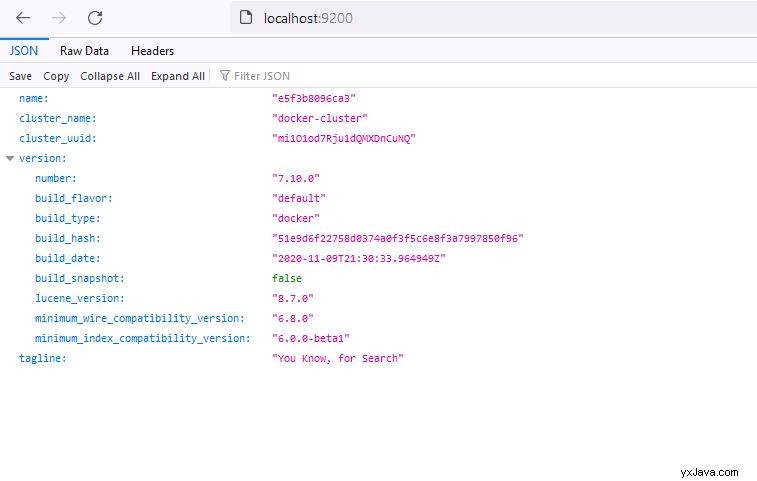
Index erstellen und nach Daten suchen
Alles in allem werden wir, wenn wir die Anwendung starten, einen Postboten verwenden, um einen Anfangsindex zu erstellen und weitere Dokumente hinzuzufügen.
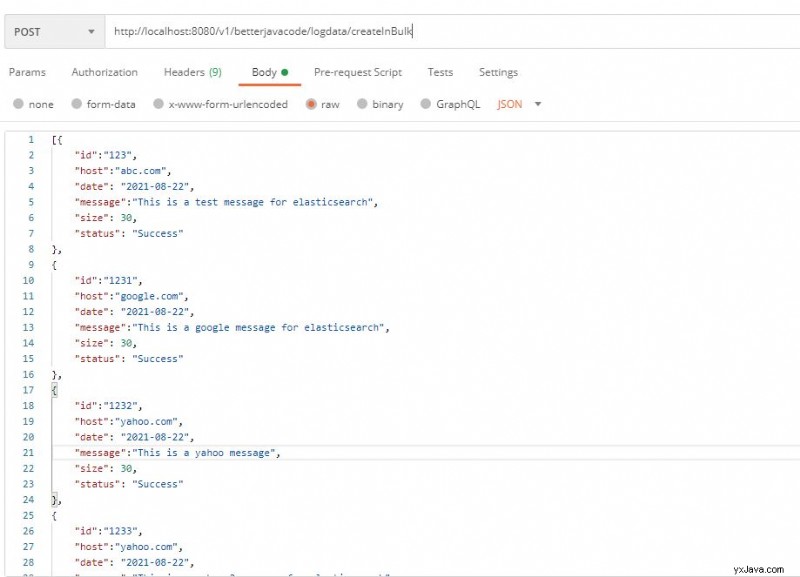
Dadurch wird auch ein Index erstellt und die Dokumente zu diesem Index hinzugefügt. Auf der Elasticsearch-Instanz können wir das Protokoll wie folgt sehen:
{
"type": "server",
"timestamp": "2021-08-22T18:48:46,579Z",
"level": "INFO",
"component": "o.e.c.m.MetadataCreateIndexService",
"cluster.name": "docker-cluster",
"node.name": "e5f3b8096ca3",
"message": "[logdataindex] creating index, cause [api], templates [], shards [1]/[1]",
"cluster.uuid": "mi1O1od7Rju1dQMXDnCuNQ",
"node.id": "PErAmAWPRiCS5tv-O7HERw"
}
Die Nachricht zeigt deutlich, dass sie einen Index logdataindex erstellt hat . Wenn Sie nun weitere Dokumente zu demselben Index hinzufügen, wird dieser Index aktualisiert.
Lassen Sie uns jetzt eine Suchanfrage ausführen. Ich werde eine einfache Abfrage ausführen, um nach dem Textbegriff „Google“
zu suchen
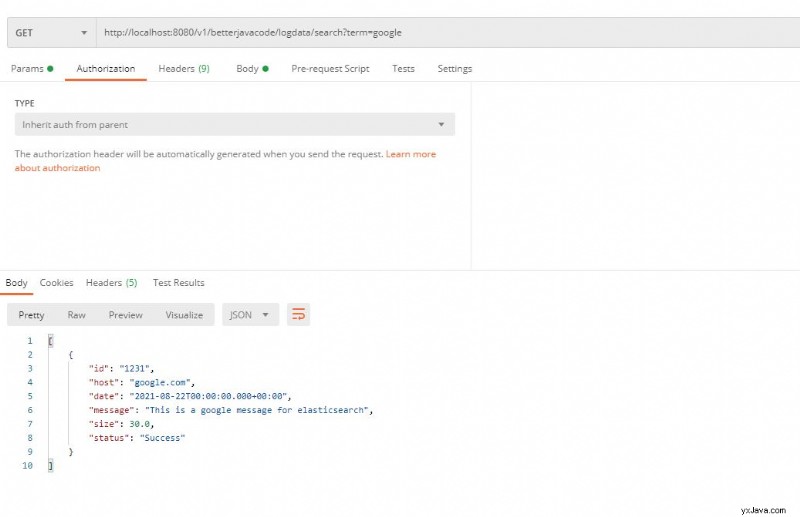
Dies war eine einfache Suchanfrage. Wie bereits erwähnt, können wir komplexere Suchanfragen schreiben, indem wir verschiedene Arten von Suchanfragen verwenden – String, Criteria oder Native.
Schlussfolgerung
Der Code für diese Demo ist in meinem GitHub-Repository verfügbar.
In diesem Beitrag haben wir die folgenden Dinge behandelt
- Elasticsearch und Schlüsselkonzepte von Elasticsearch
- Spring Data-Repository und ElasticsearchRestTemplate
- Integration in die Spring Boot-Anwendung
- Ausführung verschiedener Abfragen gegen Elasticsearch
Wenn Sie mein Buch über Spring Security noch nicht gelesen haben, können Sie es hier nachlesen.
Finden Sie Gradle als Build-Tool verwirrend? Warum ist es so kompliziert zu verstehen? Ich schreibe ein neues einfaches Buch über Gradle – Gradle For Humans. Folgen Sie mir hier für weitere Updates.