Abfragen von übergeordneten Zeilen, wenn alle untergeordneten Elemente den Filterkriterien mit SQL und Hibernate entsprechen müssen
Einführung
Das Hibernate-Forum ist eine unendliche Quelle der Inspiration, wenn es darum geht, reale Probleme zu lösen, auf die Sie bei der Entwicklung einer Unternehmensanwendung stoßen könnten.
Dieser Beitrag fragt beispielsweise nach einer JPQL-Abfrage, die eine bestimmte übergeordnete Entität abrufen soll, wenn alle untergeordneten Entitäten mit den angegebenen Filterkriterien übereinstimmen.
Wie man Elternzeilen abfragt, wenn alle Kinder den Filterkriterien entsprechen müssen, mit SQL und Hibernate @vlad_mihalcea https://t.co/lXIDCJXnL0 pic.twitter.com/SL4N0hvjkF
– Java (@java) 29. Juli 2018
Domänenmodell
Bedenken Sie, dass unsere Datenbank die folgenden Tabellen enthält, die eine Viele-zu-Viele-Beziehung bilden:
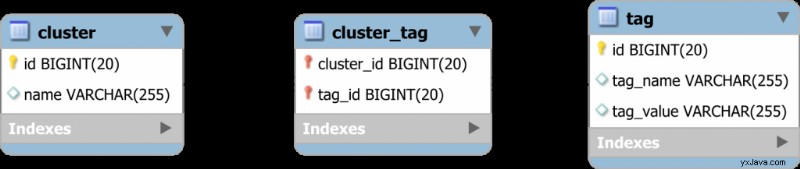
Sowohl die cluster und die tag Tabellen sind unabhängige Relationen. Zu diesem Zweck werden sie über die cluster_tag verknüpft Tabelle beitreten.
Unsere Datenbanktabellen enthalten folgende Einträge:
Die Cluster-Tabelle
| id | Name |
|---|---|
| 1 | Cluster 1 |
| 2 | Cluster 2 |
| 3 | Cluster 3 |
Die Tag-Tabelle
| id | tag_name | tag_value |
|---|---|---|
| 1 | Funke | 2.2 |
| 2 | Hadoop | 2.7 |
| 3 | Funke | 2.3 |
| 4 | Hadoop | 2.6 |
Die cluster_tag-Tabelle
| cluster_id | tag_id |
|---|---|
| 1 | 1 |
| 1 | 2 |
| 2 | 1 |
| 2 | 4 |
| 3 | 3 |
| 3 | 4 |
JPA-Einheiten
Wie ich in diesem Artikel erklärt habe, besteht eine sehr effiziente Möglichkeit, die Viele-zu-Viele-Tabellenbeziehung abzubilden, darin, die Join-Tabelle als JPA-Entität abzubilden.
Die Tag Entität sieht wie folgt aus:
@Entity(name = "Tag")
@Table(
name = "tag",
uniqueConstraints = @UniqueConstraint(
columnNames = {
"tag_name",
"tag_value"
}
)
)
public class Tag {
@Id
private Long id;
@Column(name = "tag_name")
private String name;
@Column(name = "tag_value")
private String value;
//Getters and setters omitted for brevity
}
Die Cluster Entität wird wie folgt zugeordnet:
@Entity(name = "Cluster")
@Table(name = "cluster")
public class Cluster {
@Id
private Long id;
private String name;
@OneToMany(
mappedBy = "cluster",
cascade = CascadeType.ALL,
orphanRemoval = true
)
private List<ClusterTag> tags = new ArrayList<>();
//Getters and setters omitted for brevity
public void addTag(Tag tag) {
tags.add(new ClusterTag(this, tag));
}
}
Die ClusterTag Entität wird wie folgt zugeordnet:
@Entity(name = "ClusterTag")
@Table(name = "cluster_tag")
public class ClusterTag {
@EmbeddedId
private ClusterTagId id;
@ManyToOne
@MapsId("clusterId")
private Cluster cluster;
@ManyToOne
@MapsId("tagId")
private Tag tag;
private ClusterTag() {}
public ClusterTag(Cluster cluster, Tag tag) {
this.cluster = cluster;
this.tag = tag;
this.id = new ClusterTagId(
cluster.getId(),
tag.getId()
);
}
//Getters and setters omitted for brevity
}
Wie in diesem Artikel erklärt, weil der ClusterTag Entität eine zusammengesetzte Kennung hat, verwenden wir den ClusterTagId einbettbar, die wie folgt aussieht:
@Embeddable
public class ClusterTagId
implements Serializable {
@Column(name = "cluster_id")
private Long clusterId;
@Column(name = "tag_id")
private Long tagId;
public ClusterTagId() {}
public ClusterTagId(
Long clusterId,
Long tagId) {
this.clusterId = clusterId;
this.tagId = tagId;
}
//Getters omitted for brevity
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass())
return false;
ClusterTagId that = (ClusterTagId) o;
return Objects.equals(clusterId, that.clusterId) &&
Objects.equals(tagId, that.tagId);
}
@Override
public int hashCode() {
return Objects.hash(clusterId, tagId);
}
}
Das ist es.
Das Problem
Wir wollen jetzt cluster holen Datensätze mit tag Einträge, die den folgenden zwei Bedingungen entsprechen:
- Der
tagnameistSparkund dievalueist2.2oder - Der
tagnameistHadoopund dievalueist2.7
Lassen Sie uns nun verschiedene Möglichkeiten ausprobieren, um dieses Problem zu lösen.
Ein gescheiterter erster Versuch
Eine der ersten Abfragen, die Ihnen in den Sinn kommen, ist, einfach allen Assoziationen beizutreten und nach den erforderlichen Kriterien zu filtern:
List<Cluster> clusters = entityManager
.createQuery(
"select distinct c " +
"from ClusterTag ct " +
"join ct.cluster c " +
"join ct.tag t " +
"where " +
" (t.name = :tagName1 and t.value = :tagValue1) or " +
" (t.name = :tagName2 and t.value = :tagValue2) "
, Cluster.class)
.setParameter("tagName1", "Spark")
.setParameter("tagValue1", "2.2")
.setParameter("tagName2", "Hadoop")
.setParameter("tagValue2", "2.7")
.getResultList();
Diese Abfrage gibt jedoch 2 Ergebnisse zurück:Cluster1 und Cluster2 weil beide einen tag haben Zeile, die einer der beiden Bedingungen entspricht.
Aber das wollen wir nicht! Wir wollen den cluster Datensätze, für die alle zugehörigen tag entweder dem ersten oder dem zweiten Prädikat entsprechen.
Native SQL – JOIN-Lösung
Bevor Sie herausfinden, wie Sie dieses Problem in JPQL lösen können, versuchen Sie es besser mit einfachem SQL.
Eine Lösung wäre, den cluster_tag auszuwählen Einträge, deren zugehöriger tag Zeilen entsprechen den Filterkriterien und da wir 2 Übereinstimmungen erwarten, zählen Sie die Anzahl der Übereinstimmungen, damit wir tag herausfiltern erfüllt nicht alle Bedingungen.
Indem Sie dem cluster beitreten Tabelle mit dem Tabellenergebnis von cluster_tag inneren Abfrage erhalten wir das gewünschte Ergebnis:
List<Cluster> clusters = entityManager
.createNativeQuery(
"SELECT * " +
"FROM cluster c " +
"JOIN (" +
" SELECT ct.cluster_id AS c_id " +
" FROM cluster_tag ct " +
" JOIN tag t ON ct.tag_id = t.id " +
" WHERE " +
" (t.tag_name = :tagName1 AND t.tag_value = :tagValue1) OR " +
" (t.tag_name = :tagName2 AND t.tag_value = :tagValue2) " +
" GROUP BY ct.cluster_id " +
" HAVING COUNT(*) = 2" +
") ct1 on c.id = ct1.c_id ", Cluster.class)
.setParameter("tagName1", "Spark")
.setParameter("tagValue1", "2.2")
.setParameter("tagName2", "Hadoop")
.setParameter("tagValue2", "2.7")
.getResultList();
Diese Abfrage hat jedoch einen großen Nachteil. Wir wollen nur den Cluster -Entität, sodass der oberste Join mehr Arbeit auf der Datenbankseite erzeugt (insbesondere wenn die zugrunde liegende Datenbank nur Nested Loops unterstützt), was vermieden werden könnte, wenn wir die Abfrage so umschreiben, dass sie stattdessen einen Semi-Join verwendet. Darüber hinaus kann die obige SQL-Abfrage nicht in JPQL ausgedrückt werden, was ein Problem sein könnte, wenn wir die Abfrage dynamisch mit der Criteria-API erstellen möchten.
Native SQL – SEMI-JOIN-Lösung
Die SEMI-JOIN-Abfrage sieht folgendermaßen aus:
List<Cluster> clusters = entityManager
.createNativeQuery(
"SELECT * " +
"FROM cluster c " +
"WHERE EXISTS (" +
" SELECT ct.cluster_id as c_id " +
" FROM cluster_tag ct " +
" JOIN tag t ON ct.tag_id = t.id " +
" WHERE " +
" c.id = ct.cluster_id AND ( " +
" (t.tag_name = :tagName1 AND t.tag_value = :tagValue1) OR " +
" (t.tag_name = :tagName2 AND t.tag_value = :tagValue2) " +
" )" +
" GROUP BY ct.cluster_id " +
" HAVING COUNT(*) = 2 " +
") ", Cluster.class)
.setParameter("tagName1", "Spark")
.setParameter("tagValue1", "2.2")
.setParameter("tagName2", "Hadoop")
.setParameter("tagValue2", "2.7")
.getResultList();
Das ist nicht nur effizienter, da wir letztlich nur den cluster selektieren und projizieren Records, aber die Abfrage ist noch einfacher zu lesen und kann auch an JPQL oder Criteria API angepasst werden.
JPQL – SEMI-JOIN-Lösung mit explizitem Verknüpfungsbeitritt
Wie bereits erwähnt, kann die SEMI-JOIN-Abfrage wie folgt in JPQL umgeschrieben werden:
List<Cluster> clusters = entityManager.createQuery(
"select c " +
"from Cluster c " +
"where exists (" +
" select ctc.id " +
" from ClusterTag ct " +
" join ct.cluster ctc " +
" join ct.tag ctt " +
" where " +
" c.id = ctc.id and ( " +
" (ctt.name = :tagName1 and ctt.value = :tagValue1) or " +
" (ctt.name = :tagName2 and ctt.value = :tagValue2) " +
" )" +
" group by ctc.id " +
" having count(*) = 2" +
") ", Cluster.class)
.setParameter("tagName1", "Spark")
.setParameter("tagValue1", "2.2")
.setParameter("tagName2", "Hadoop")
.setParameter("tagValue2", "2.7")
.getResultList();
Obwohl explizite Joins beim Schreiben von JPQL-Abfragen normalerweise bevorzugt werden, sieht es diesmal so aus, als würde Hibernate einen nutzlosen JOIN zwischen cluster_tag ausgeben und cluster in der inneren Abfrage:
SELECT c.id AS id1_0_,
c.NAME AS name2_0_
FROM cluster c
WHERE EXISTS (
SELECT ctc.id
FROM cluster_tag ct
INNER JOIN cluster ctc ON ct.cluster_id = ctc.id
INNER JOIN tag ctt ON ct.tag_id = ctt.id
WHERE c.id = ctc.id AND (
ctt.tag_name = ? AND ctt.tag_value = ? OR
ctt.tag_name = ? AND ctt.tag_value = ?
)
GROUP BY ctc.id
HAVING COUNT(*) = 2
)
Beachten Sie den INNER JOIN cluster ctc ON ct.cluster_id = ctc.id überflüssiger Join, den wir vermeiden möchten.
JPQL – SEMI-JOIN-Lösung mit implizitem Assoziationsbeitritt
Umschreiben der vorherigen Abfrage, um einen impliziten Join für ClusterTag.cluster zu verwenden kann wie folgt durchgeführt werden:
List<Cluster> clusters = entityManager
.createQuery(
"select c " +
"from Cluster c " +
"where exists (" +
" select ct.cluster.id " +
" from ClusterTag ct " +
" join ct.tag ctt " +
" where " +
" c.id = ct.cluster.id and ( " +
" (ctt.name = :tagName1 and ctt.value = :tagValue1) or " +
" (ctt.name = :tagName2 and ctt.value = :tagValue2) " +
" )" +
" group by ct.cluster.id " +
" having count(*) = 2" +
") ", Cluster.class)
.setParameter("tagName1", "Spark")
.setParameter("tagValue1", "2.2")
.setParameter("tagName2", "Hadoop")
.setParameter("tagValue2", "2.7")
.getResultList();
Beim Ausführen der obigen JPQL-Abfrage generiert Hibernate die folgende SQL-Abfrage:
SELECT c.id AS id1_0_,
c.NAME AS name2_0_
FROM cluster c
WHERE EXISTS (
SELECT ct.cluster_id
FROM cluster_tag ct
INNER JOIN tag ctt ON ct.tag_id = ctt.id
WHERE
c.id = ct.cluster_id AND (
ctt.tag_name = ? AND ctt.tag_value = ? OR
ctt.tag_name = ? AND ctt.tag_value = ?
)
GROUP BY ct.cluster_id
HAVING COUNT(*) = 2
)
Großartig!
Schlussfolgerung
Wenn es um das Abrufen von Daten geht, ist es am besten, sich zuerst die SQL-Abfrage vorzustellen und erst danach eine JPQL- oder Kriterien-API-Abfrage zu verwenden, um Entitäten abzurufen, die wir ändern möchten.