Ejemplo de repositorio de trabajo de Spring Batch
En este artículo discutiremos el concepto de JobRepository utilizado en el marco Spring Batch. Es una interfaz con SimpleJobRepository siendo su implementación más simple flotada por el marco. Por supuesto, como con la mayoría de las cosas en Spring, también se puede tener una implementación personalizada de un JobRepository. Para demostrar el concepto de JobRepository, prepararemos un ejemplo simple basado en la configuración XML. Será un proyecto maven. Las herramientas utilizadas en el ejemplo son las siguientes.
- Eclipse Helios
- Maven 2.2.1
- Primavera 4.0.5.LIBERACIÓN
- Lote de primavera 3.0.4.LIBERAR
- JDBC 4.0.5.LIBERACIÓN
- HSQL 1.8.0.7
- Apache Commons 1.4
Este artículo ha sido organizado como se muestra a continuación. Y como siempre, el código de ejemplo está disponible para descargar al final del artículo.
Índice
- 1. Introducción
- 2. Conceptos básicos de Spring Batch
- 2.1. Trabajo
- 2.2. Repositorio de trabajos
- 2.2.1 MapJobRepositoryFactoryBean
- 2.2.2 JobREpositoryFactoryBean
- 2.3. Paso
- 2.3.1 Procesamiento orientado a fragmentos
- 2.3.2 Procesamiento de TaskletStep
- 3. Código de ejemplo
- 3.1 Configuración del proyecto
- 3.2 Dependencias Maven
- 3.3 Configuración de la base de datos HSQL
- 3.4 POJO
- 3.5 TaskletStep
- 3.6 Configuración de contexto
- 3.7 Configuración del trabajo
- 3.8 Configuración de la aplicación
- 3.9 Salida
- 4. Conclusión
1. Introducción
Spring Batch es un marco de procesamiento por lotes de código abierto ampliamente utilizado. Incorpora muchas de las propiedades que ofrece Spring. Además, expone una gran cantidad de funciones, como configuraciones sencillas de trabajos, gestión de transacciones, registro, programación de trabajos, por nombrar algunas. Como se indicó anteriormente, este artículo se enfoca en usar y configurar un JobRepository . Es una entidad que ofrece el mecanismo de persistencia en el marco.
Cuando un Job está configurado, hay una serie de cosas en juego. Digamos, por ejemplo, ¿cuántos trabajos se han configurado? ¿Qué son los Steps en cada uno de estos trabajos? ¿Cuál es el estado de la ejecución del trabajo? ¿Debe iniciarse, reiniciarse o detenerse el trabajo? Y muchos más. ¿Dónde se almacenarían estos detalles? Por lo tanto, tenemos el JobRepository. Técnicamente, es solo una interfaz. SimpleJobRepository siendo su implementación más simple la que ofrece el framework. Para automatizar y facilitar la creación de SimpleJobRepository, un AbstractJobRepositoryFactoryBean ha sido introducido.
Dos de sus subclases son MapJobRepositoryFactoryBean y JobRepositoryFactoryBean . Como se indicó anteriormente, en este artículo detallaremos estos dos beans y demostraremos el uso del JobRepositoryFactoryBean con una fuente de datos HSQL a través de un ejemplo basado en una configuración XML.
2. Conceptos básicos de Spring Batch
La sección anterior ofrece un resumen justo de lo que tratará este texto. Pero antes de comenzar, echemos un vistazo rápido a algunos de los conceptos involucrados. Esto debería facilitar el seguimiento del código de ejemplo en las secciones posteriores.
2.1 Trabajo
Como se define en la documentación de Spring Batch, un job encapsula toda la idea del procesamiento por lotes. Digamos que queremos leer todos los registros de una tabla de base de datos determinada, procesar los registros e insertarlos en otra tabla. Y luego llame a algún procedimiento almacenado en esa tabla. Todos estos pasos, o fragmentos de tareas de ejecución, constituyen un trabajo.
Un trabajo es básicamente una interfaz. Tiene muchas implementaciones diferentes pero SimpleJob es una de sus implementaciones más simples proporcionada por el marco Spring Batch. Cuando se usa la configuración XML, simplemente se define usando las etiquetas como se muestra en el fragmento de código de configuración XML a continuación. El marco abstrae el hecho de que básicamente estamos creando una instancia de SimpleJob. Un trabajo consta de uno o más pasos.
Configuración de trabajos XML
<job id="myJob">
<step id="firstStep" next="secStep"/>
<step id="secStep" />
</job>
1.2 Repositorio de trabajos
Como su nombre indica, es un repositorio que ofrece un mecanismo de persistencia para todos los metadatos relacionados con la ejecución del Trabajo. Todas las operaciones CRUD relacionadas con las implementaciones de Job, Step, JobLauncher se almacenan en este repositorio. Al configurar estas características del marco, de forma predeterminada, un jobRepository se busca frijol. Pero desde JobRepository es una interfaz, también se puede tener una implementación personalizada del repositorio para usar con las características del marco. Su implementación más simple flotada por el marco es el SimpleJobRepository . También tenga en cuenta que el marco de trabajo por lotes abstrae muchos de los detalles esenciales de las implementaciones de JobRepository. A continuación se muestra un ejemplo sencillo de configuración de un repositorio de trabajos.
Configuración del repositorio de trabajos
<job-repository id="jobRepository"
data-source="dataSource"
transaction-manager="transactionManager"
table-prefix="JCG_BATCH_"
max-varchar-length="1000"/>
- “id” es el único atributo obligatorio en la configuración anterior. Los otros atributos, si no se especifican explícitamente, toman los valores predeterminados
- 'data-source' se puede configurar para que apunte a la base de datos que se usará para almacenar entidades de metadatos por lotes.
- 'transaction-manager' se refiere a la entidad utilizada para manejar la gestión de transacciones. La mayoría de las veces, usando un Spring Batch proporcionado
Resourceless TransactionManagersirve bien al propósito. - ‘prefijo de tabla’. Los metadatos de Spring Batch se almacenan en tablas que se nombran con 'SPRING_BATCH_' como prefijo. Si uno quiere que se modifiquen para usar algún otro prefijo, entonces se puede proporcionar este valor de atributo. Tenga en cuenta que este atributo solo puede modificar los prefijos de los nombres de las tablas, no afecta los nombres de las columnas en las tablas.
- 'max-varchar-length' tiene por defecto 2500 caracteres, que es el tamaño máximo permitido de caracteres varchar en las tablas de metadatos. En la configuración anterior, se ha restringido a 1000.
Mientras estamos en eso, tiene sentido mirar el AbstractJobRepositoryFactoryBean clase. Es un FactoryBean que automatiza la creación de un SimpleJobRepository. Declara métodos abstractos para implementaciones de objetos DAO. Tiene dos subclases bien conocidas.
2.2.1 MapJobRepositoryFactoryBean
MapJobRepositoryFactoryBean automatiza la creación de SimpleJobRepository mediante la implementación de DAO en memoria no persistente. Por lo tanto, esto se usa cuando uno no quiere conservar los objetos del dominio en una base de datos, por ejemplo, para escribir algunos casos de prueba o creación rápida de prototipos. Esto ayuda a acelerar el procesamiento por lotes, ya que escribir en la base de datos consume tiempo. Pero hay algunas cosas a tener en cuenta al usar esta versión de mapa en memoria del repositorio de trabajos.
- Es volátil; por lo tanto, no se puede persistir entre ejecuciones de trabajos.
- No permite reinicios entre instancias de JVM debido al punto anterior.
- No es adecuado para su uso en trabajos de subprocesos múltiples o pasos particionados.
- Tampoco puede garantizar que dos trabajos con los mismos parámetros se inicien simultáneamente.
- No requiere un administrador de transacciones, ya que la semántica de reversión se define en él, pero se puede usar un TransactionManager sin recursos para fines de prueba
- El siguiente ejemplo muestra la configuración de un repositorio de trabajos en memoria
Configuración del repositorio de trabajos en memoria<bean id="jobRepository" class="org.springframework.batch.core.repository.support.MapJobRepositoryFactoryBean"> <property name="transactionManager" ref="transactionManager"/> </bean> - Requiere configurar una base de datos. Admite la mayoría de las bases de datos RDBMS estándar.
- Intenta averiguar el tipo de base de datos a partir de la fuente de datos suministrada, pero para las bases de datos no estándar utilizadas, es posible que se tenga que especificar explícitamente el tipo de base de datos. También es posible que tenga que proporcionar una implementación de todos sus métodos y conectarlo manualmente.
- El siguiente fragmento muestra una posible configuración.
Configuración del repositorio de trabajos<bean id="jobRepository" class="org.springframework.batch.core.repository.support.JobRepositoryFactoryBean"> <property name="dataSource" ref="dataSource" /> <property name="transactionManager" ref="transactionManager" /> <property name="databaseType" value="hsql" /> </bean>
2.2.2. JobRepositoryFactoryBean
JobRepositoryFactoryBean automatiza la creación de un SimpleJobRepository mediante el uso de una implementación JDBC DAO que conserva los metadatos por lotes en una base de datos. Por lo tanto, esto requiere la configuración de una base de datos. Las siguientes son algunas de sus características más destacadas.
2.3 Paso
Un Step es donde ocurre la ejecución real. Es una fase secuencial de un trabajo por lotes. Un trabajo puede tener uno o varios pasos. La ejecución del Paso se puede procesar en fragmentos o en un tasklet, conceptos que se detallan a continuación.
2.3.1 Procesamiento orientado a fragmentos
Chunk-Oriented Processing es la implementación más común de un paso. Implica leer datos de una fuente de entrada, procesarlos mediante la aplicación de alguna lógica comercial y luego, finalmente, escribir los fragmentos de datos procesados dentro de un límite de transacción. Tenga en cuenta que el procesamiento es una parte opcional del procesamiento orientado a fragmentos. El siguiente es un fragmento de ejemplo de este tipo de procesamiento.
Procesamiento orientado a fragmentos
<job id="sampleJob" job-repository="jobRepository">
<step id="step1">
<tasklet transaction-manager="transactionManager">
<chunk reader="itemReader" processor="itemProcessor" writer="itemWriter" commit-interval="10"/>
</tasklet>
</step>
</job>
2.3.2 Procesamiento de Tasklet
Tasklet Processing se usa cuando el Paso no implica leer (y procesar ) y escribir datos pero solo una unidad de trabajo, por ejemplo, hacer una llamada a un procedimiento remoto, ejecutar algún método, etc. Tasklet es una interfaz simple que tiene un solo método execute() que TaskletStep llama repetidamente hasta que encuentra un estado RepeatStatus.FINISHED o una excepción que indica un error. A continuación se presenta un ejemplo de configuración de un TaskletStep.
Configuración de TaskletStep
<job id="myJob" xmlns="http://www.springframework.org/schema/batch" restartable="true"> <step id="step1" allow-start-if-complete="true"> <tasklet ref="myTasklet"> </tasklet> </step> </job>
3. Ejemplo
Ahora que hemos repasado los conceptos básicos de Spring Batch, deberíamos profundizar en el siguiente código de ejemplo. Este será un trabajo simple que tiene solo un TaskletStep. Usaremos una base de datos en memoria:HSQL. Crearemos una tabla en esta base de datos y simplemente leeremos los registros de esta tabla en nuestro TaskletStep. Además, como se indicó anteriormente, usaremos el JobRepositoryFactoryBean con esta base de datos HSQL como fuente de datos para conservar los metadatos del lote.
3.1 Configuración del proyecto
- Inicie Eclipse desde una ubicación adecuada y cree un proyecto Maven. Proporcione el nombre del proyecto como se muestra en las capturas de pantalla a continuación.
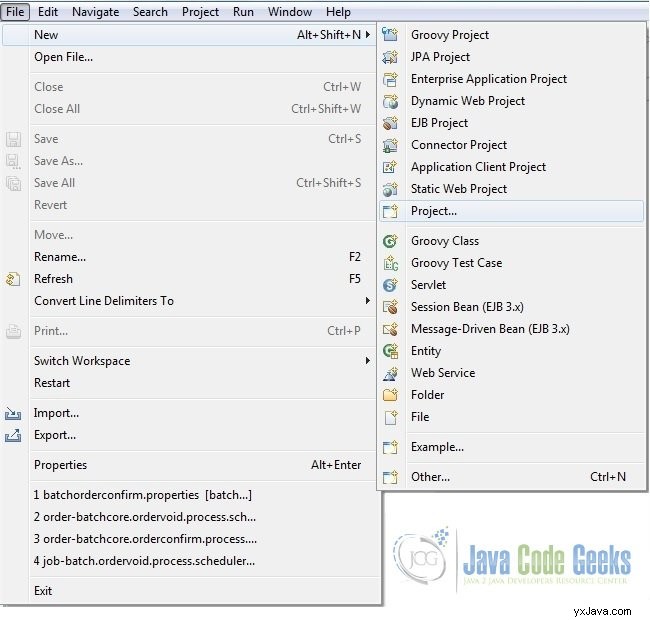
Fig.1 Crear proyecto
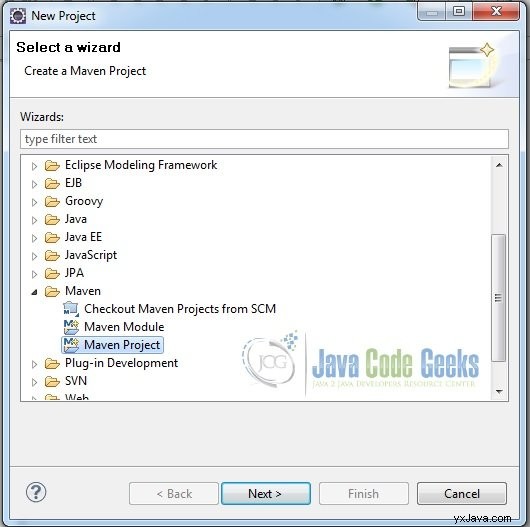
Fig.2 Elija la creación de un proyecto Maven
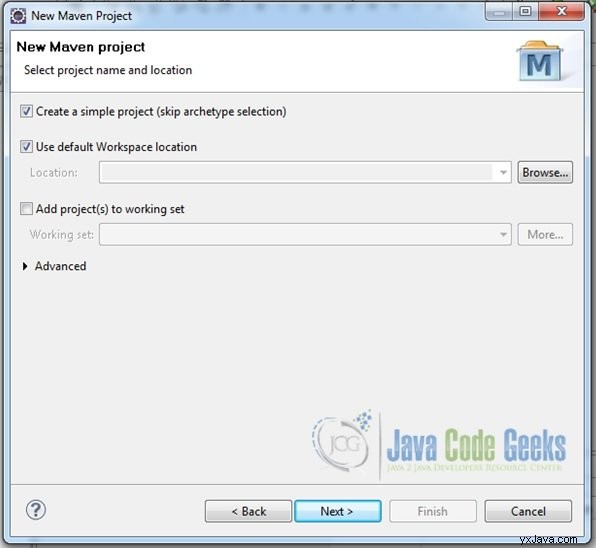
Fig.3 Omitir selección de tipo de arquetipo
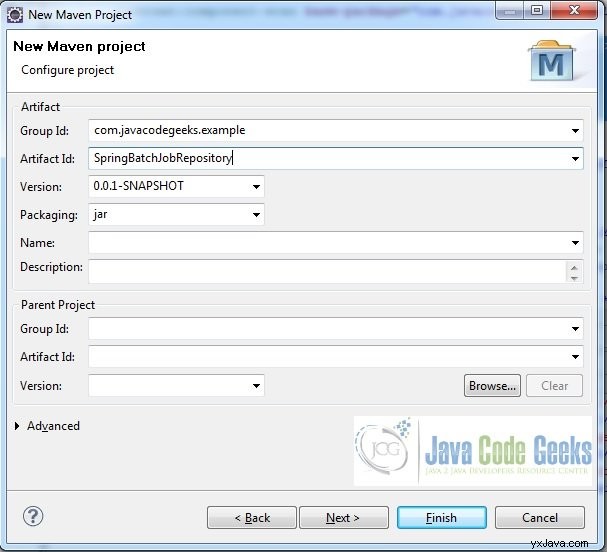
Fig.4 Proporcionar detalles del proyecto
- Agregue algunas carpetas y archivos para que tengamos la siguiente estructura de proyecto final.
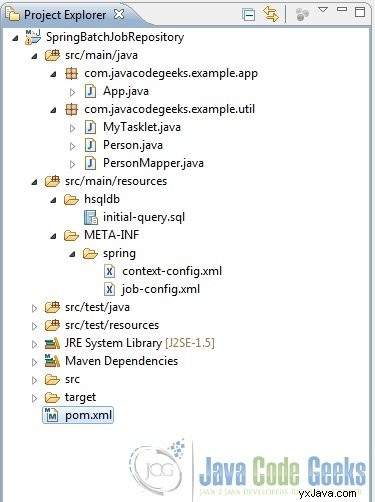
Fig.5 Estructura del proyecto final
3.2 Dependencias Maven
Abre el pom.xml y agréguele las siguientes dependencias.
pom.xml
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.javacodegeeks.example</groupId>
<artifactId>SpringBatchJobRepository</artifactId>
<version>0.0.1-SNAPSHOT</version>
<properties>
<spring.version>4.0.5.RELEASE</spring.version>
<spring.batch.version>3.0.4.RELEASE</spring.batch.version>
<spring.jdbc.version>4.0.5.RELEASE</spring.jdbc.version>
<hsql.version>1.8.0.7</hsql.version>
<commons.version>1.4</commons.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-context-support</artifactId>
<version>${spring.version}</version>
</dependency>
<dependency>
<groupId>org.springframework.batch</groupId>
<artifactId>spring-batch-core</artifactId>
<version>${spring.batch.version}</version>
</dependency>
<dependency>
<groupId>hsqldb</groupId>
<artifactId>hsqldb</artifactId>
<version>${hsql.version}</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-jdbc</artifactId>
<version>${spring.jdbc.version}</version>
</dependency>
<dependency>
<groupId>commons-dbcp</groupId>
<artifactId>commons-dbcp</artifactId>
<version>${commons.version}</version>
</dependency>
</dependencies>
</project>
3.3 Base de datos HSQL
En este ejemplo, usaremos HSQL, que es una base de datos en memoria para la persistencia de los metadatos del lote y también para nuestro trabajo. En el initial-query.xml archivo, crearemos una tabla simple e insertaremos algunos registros en ella. El TaskletStep en nuestro Trabajo leerá de esta tabla HSQL e imprimirá algunas declaraciones.
pom.xml
DROP TABLE person IF EXISTS;
CREATE TABLE person (
firstName VARCHAR(20),
lastName VARCHAR(20),
school VARCHAR(20),
rollNumber int);
INSERT INTO person VALUES ('Henry','Donald','Little Garden',1234901);
INSERT INTO person VALUES ('Eric','Osborne','Little Garden',1234991);
3.4 POJO
Ahora, escribiremos nuestras clases POJO. Uno es un simple Person.java clase que simplemente tiene algunos atributos y el otro es PersonMapper.java que simplemente mapea los atributos en el Person.java class con los campos leídos de nuestra tabla de base de datos HSQL establecida anteriormente.
Person.java
package com.javacodegeeks.example.util;
public class Person {
String firstName,lastName,school;
int rollNumber;
public String getFirstName() {
return firstName;
}
public void setFirstName(String firstName) {
this.firstName = firstName;
}
public String getLastName() {
return lastName;
}
public void setLastName(String lastName) {
this.lastName = lastName;
}
public String getSchool() {
return school;
}
public void setSchool(String school) {
this.school = school;
}
public int getRollNumber() {
return rollNumber;
}
public void setRollNumber(int rollNumber) {
this.rollNumber = rollNumber;
}
@Override
public String toString(){
return "Welcome, "+ firstName+" "+ lastName+" to "+ school+"!";
}
}
PersonMapper.java
package com.javacodegeeks.example.util;
import java.sql.ResultSet;
import java.sql.SQLException;
import org.springframework.jdbc.core.RowMapper;
public class PersonMapper implements RowMapper {
public Person mapRow(ResultSet rs, int rowNum) throws SQLException {
Person person = new Person();
person.setFirstName(rs.getString("firstName"));
person.setLastName(rs.getString("lastName"));
person.setSchool(rs.getString("school"));
person.setRollNumber(rs.getInt("rollNumber"));
return person;
}
}
3.5 TaskletPaso
A continuación, escribiremos el siguiente código que define el TaskletStep para ser ejecutado de nuestro trabajo. Es un Tasklet bastante simple que solo lee de la tabla de la base de datos e imprime algunas declaraciones.
MyTasklet.java
package com.javacodegeeks.example.util;
import java.util.ArrayList;
import java.util.List;
import javax.sql.DataSource;
import org.springframework.batch.core.StepContribution;
import org.springframework.batch.core.scope.context.ChunkContext;
import org.springframework.batch.core.step.tasklet.Tasklet;
import org.springframework.batch.repeat.RepeatStatus;
import org.springframework.jdbc.core.JdbcTemplate;
public class MyTasklet implements Tasklet{
private DataSource dataSource;
private String sql="select firstName,lastName,school,rollNumber from PERSON";
public RepeatStatus execute(StepContribution contribution,
ChunkContext chunkContext) throws Exception {
List personList = new ArrayList();
JdbcTemplate myTemplate = new JdbcTemplate(getDataSource());
personList = myTemplate.query(sql, new PersonMapper());
for(Person p: personList){
System.out.println(p.toString());
}
return RepeatStatus.FINISHED;
}
public DataSource getDataSource() {
return dataSource;
}
public void setDataSource(DataSource dataSource) {
this.dataSource = dataSource;
}
}
3.6 Configuración de contexto
En la siguiente sección configuraremos el contexto básico de nuestra aplicación. Algunas cosas a tener en cuenta aquí:
- Estamos usando el
JobRepositoryFactoryBeanconectado con nuestra base de datos HSQL para ser utilizado como fuente de datos. Tenga en cuenta cómo el tipo de base de datos se ha especificado en 'HSQL '. Si fuera una base de datos db2, el tipo habría sido 'db2 etc. - A
ResourcelessTransactionManagerse usa aquí. - Además, tenga en cuenta cómo se ha invocado la creación de las tablas de metadatos por lotes y nuestra tabla PERSONA.
contexto-config.xml
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:jdbc="http://www.springframework.org/schema/jdbc"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/jdbc
http://www.springframework.org/schema/jdbc/spring-jdbc.xsd">
<bean id="jobRepository"
class="org.springframework.batch.core.repository.support.JobRepositoryFactoryBean">
<property name="dataSource" ref="dataSource" />
<property name="transactionManager" ref="transactionManager" />
<property name="databaseType" value="hsql" />
</bean>
<bean id="jobLauncher"
class="org.springframework.batch.core.launch.support.SimpleJobLauncher">
<property name="jobRepository" ref="jobRepository" />
</bean>
<bean id="transactionManager"
class="org.springframework.batch.support.transaction.ResourcelessTransactionManager" />
<bean id="dataSource" class="org.apache.commons.dbcp.BasicDataSource"
lazy-init="true" destroy-method="close">
<property name="driverClassName" value="org.hsqldb.jdbcDriver" />
<property name="url"
value="jdbc:hsqldb:file:src/main/resources/hsqldb/batchcore.db;shutdown=true;" />
<property name="username" value="sa" />
<property name="password" value="" />
</bean>
<!-- Create meta-tables -->
<jdbc:initialize-database data-source="dataSource">
<jdbc:script location="classpath:hsqldb/initial-query.sql" />
<jdbc:script location="org/springframework/batch/core/schema-drop-hsqldb.sql" />
<jdbc:script location="org/springframework/batch/core/schema-hsqldb.sql" />
</jdbc:initialize-database>
</beans>
3.7 Configuración del trabajo
Bien, ya casi llegamos. Aquí vamos a configurar nuestro trabajo simple que tiene solo un TaskletStep . Es bastante simple y debería ser fácil de seguir.
job-config.xml
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:batch="http://www.springframework.org/schema/batch"
xmlns:task="http://www.springframework.org/schema/task"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xmlns:jdbc="http://www.springframework.org/schema/jdbc"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/batch
http://www.springframework.org/schema/batch/spring-batch.xsd
http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring-context.xsd
http://www.springframework.org/schema/jdbc
http://www.springframework.org/schema/jdbc/spring-jdbc.xsd
http://www.springframework.org/schema/task
http://www.springframework.org/schema/task/spring-task.xsd">
<job id="myJob" xmlns="http://www.springframework.org/schema/batch" restartable="true">
<step id="step1" allow-start-if-complete="true">
<tasklet ref="myTasklet">
</tasklet>
</step>
</job>
<bean id="myTasklet" class="com.javacodegeeks.example.util.MyTasklet">
<property name="dataSource" ref="dataSource"></property>
</bean>
</beans>
3.8 Ejecución de la aplicación
Ahora que hemos terminado con nuestra configuración, ejecutemos la aplicación. Invocaremos el JobLauncher e inicie nuestro Trabajo.
App.java
package com.javacodegeeks.example.app;
import org.springframework.batch.core.Job;
import org.springframework.batch.core.JobExecution;
import org.springframework.batch.core.JobParameters;
import org.springframework.batch.core.launch.JobLauncher;
import org.springframework.context.ApplicationContext;
import org.springframework.context.support.ClassPathXmlApplicationContext;
public class App {
public static void main(String[] args) {
String[] str = {"META-INF/spring/context-config.xml","META-INF/spring/job-config.xml"};
ApplicationContext ctx = new ClassPathXmlApplicationContext(str);
Job job = (Job) ctx.getBean("myJob");
JobLauncher jobLauncher = (JobLauncher) ctx.getBean("jobLauncher");
try{
JobExecution execution = jobLauncher.run(job, new JobParameters());
System.out.println("Job Execution Status: "+ execution.getStatus());
}catch(Exception e){
e.printStackTrace();
}
}
}
3.9 Salida
Finalmente, solo ejecuta el App.java como una aplicación Java. Si todo se ha seguido hasta el momento, debería ver el siguiente resultado en la consola.
Salida
INFO: Executing SQL script from class path resource [hsqldb/initial-query.sql]
Jul 29, 2015 8:03:44 AM org.springframework.jdbc.datasource.init.ScriptUtils executeSqlScript
INFO: Executed SQL script from class path resource [hsqldb/initial-query.sql] in 17 ms.
Jul 29, 2015 8:03:44 AM org.springframework.jdbc.datasource.init.ScriptUtils executeSqlScript
INFO: Executing SQL script from class path resource [org/springframework/batch/core/schema-drop-hsqldb.sql]
Jul 29, 2015 8:03:44 AM org.springframework.jdbc.datasource.init.ScriptUtils executeSqlScript
INFO: Executed SQL script from class path resource [org/springframework/batch/core/schema-drop-hsqldb.sql] in 10 ms.
Jul 29, 2015 8:03:44 AM org.springframework.jdbc.datasource.init.ScriptUtils executeSqlScript
INFO: Executing SQL script from class path resource [org/springframework/batch/core/schema-hsqldb.sql]
Jul 29, 2015 8:03:44 AM org.springframework.jdbc.datasource.init.ScriptUtils executeSqlScript
INFO: Executed SQL script from class path resource [org/springframework/batch/core/schema-hsqldb.sql] in 3 ms.
Jul 29, 2015 8:03:44 AM org.springframework.batch.core.launch.support.SimpleJobLauncher run
INFO: Job: [FlowJob: [name=myJob]] launched with the following parameters: [{}]
Jul 29, 2015 8:03:44 AM org.springframework.batch.core.job.SimpleStepHandler handleStep
INFO: Executing step: [step1]
Welcome, Henry Donald to Little Garden!
Welcome, Eric Osborne to Little Garden!
Jul 29, 2015 8:03:44 AM org.springframework.batch.core.launch.support.SimpleJobLauncher run
INFO: Job: [FlowJob: [name=myJob]] completed with the following parameters: [{}] and the following status: [COMPLETED]
Job Execution Status: COMPLETED
4. Conclusión
Esto nos lleva al final de este artículo. Aquí, demostramos el concepto de un repositorio de trabajo con un ejemplo simple. Como se prometió, el código de ejemplo está disponible para descargar a continuación.