La famille des structures de données arborescentes
Maintenant, nous ne sommes pas parler des gros plants de brocoli qui bordent les forêts. Nous parlons d'une structure de données récursive appelée arbre. Ces arbres ne fournissent pas d'oxygène, mais ils ont des branches. Dans cette leçon, nous allons couvrir ce qu'est exactement un arbre, discuter de certaines de ses propriétés et discuter de certaines de ses applications. En particulier, nous allons nous concentrer sur l'arbre de recherche binaire. Comme toujours, nous allons parcourir une implémentation de base et partager ses performances. Commençons !
Qu'est-ce qu'un arbre ?
Un arbre est une structure de données récursive construite à partir de nœuds, un peu comme toutes les structures de données liées aux listes chaînées dont nous avons déjà parlé. Cependant, la différence ici est que chaque nœud peut pointer vers plusieurs autres nœuds. Le hic, c'est que les arbres ne doivent contenir aucun cycle. En d'autres termes, les nœuds ne doivent avoir qu'un seul parent (un parent étant un nœud qui pointe vers un enfant). De plus, les nœuds ne peuvent pas se référencer eux-mêmes. Dans les deux cas, nous nous retrouverions avec une structure de données différente appelée graphe.
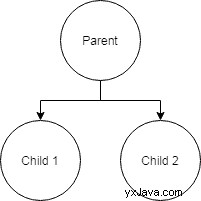
Nous pouvons imaginer un arbre assez facilement puisque nous les utilisons tous les jours. En fait, nos systèmes de fichiers utilisent un format arborescent pour les répertoires. Bien qu'il existe des moyens d'introduire des cycles avec des outils tels que des liens symboliques et physiques, les répertoires conservent par défaut la règle du parent unique pour les nœuds. Par exemple, les PC Windows ont généralement un lecteur nommé par une lettre comme racine (C://). Ce répertoire contient plusieurs répertoires que nous appelons généralement enfants. Chacun de ces répertoires peut également avoir des enfants, etc.
Propriétés des arbres
Les arbres en eux-mêmes sont des types de données abstraits, ce qui signifie qu'ils n'ont pas vraiment de propriétés au-delà de ce dont nous avons discuté ci-dessus. Un arbre n'est en réalité qu'une famille de structures de données qui partagent les mêmes règles fondamentales. Si nous voulons vraiment entrer dans les détails, nous devrons définir des structures de données concrètes :
- Arbres binaires
- Arbres de recherche binaires
- Arbres AVL
- Arbres rouge-noir
- Arbres étalés
- Arbres N-aires
- Arbres triés
- Arbres de suffixes
- Arbres Huffman
- Tas
- B-Arbres
Le mérite de cette liste revient à M. Chatterjee de Quora.
Pour les besoins de ce didacticiel, nous nous concentrerons sur les arbres de recherche binaires. Mais attendez! Nous devrons d'abord comprendre ce qu'est un arbre binaire. Un arbre binaire est un arbre où chaque parent peut avoir jusqu'à deux enfants. Cela rend la sémantique assez simple puisque nous pouvons nous référer aux enfants comme gauche et droite. Au-delà de cela, les arbres binaires n'ont pas vraiment de propriétés particulières. En fait, ils sont encore un peu trop abstraits. Heureusement, les arbres de recherche binaires réduisent un peu la portée pour rendre la structure de données pratique.
Un arbre de recherche binaire est l'une des nombreuses variantes de la structure arborescente binaire simple. Dans un arbre de recherche binaire, nous restreignons davantage où les données peuvent être stockées. En particulier, nous donnons des poids aux nœuds, puis utilisons ces poids pour décider où les nouveaux nœuds sont stockés. Par exemple, imaginons que nous ayons un arbre avec un nœud racine de poids 15. Si nous apportons un nœud de poids 7, où devons-nous le stocker ? Gauche ou droite ?
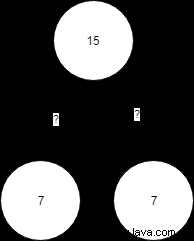
Évidemment, nous devons établir certaines règles. Sur un arbre de recherche binaire, le côté gauche d'un nœud est réservé aux petites valeurs tandis que son côté droit est réservé aux grandes valeurs. Dans ce cas, nous en enverrons 7 sur le côté gauche.
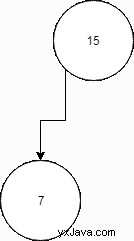
Maintenant, juste pour compliquer un peu les choses, que se passe-t-il si un nœud arrive avec un poids de 9 ? Nous devrons faire un peu de traversée. En d'autres termes, nous savons que 9 est inférieur à 15, nous allons donc essayer de placer le 9 là où nous venons de placer le 7. Cependant, il s'avère qu'il y a déjà un nœud, alors que faisons-nous ? Nous recommençons simplement le processus en traitant 7 comme le nouveau parent. Comme 9 est supérieur à 7, nous placerons le nouveau nœud à droite de 7.
Maintenant, cette structure a des propriétés assez intéressantes. C'est un peu comme un tableau trié, mais nous avons l'avantage d'accélérer les insertions et les suppressions. C'est le meilleur des deux mots type de structure de données, mais il a encore quelques inconvénients. Comme nous le verrons plus tard, les performances les plus défavorables à tous les niveaux sont O(N). Ce pire scénario ne se produit que si l'arbre de recherche binaire n'est en fait qu'une liste chaînée déguisée. Sinon, nous vivons généralement un O(log(N)) assez heureux.
Comme nous pouvons le voir ci-dessus, il existe plusieurs autres types d'arbres qui ont des propriétés différentes. Un bon point de départ serait probablement l'arbre rouge-noir. C'est une variante de l'arbre de recherche binaire classique qui ajoute une contrainte supplémentaire :l'arbre doit rester équilibré. À partir de là, il pourrait être approprié de commencer à explorer d'autres types d'arbres. Peut-être pourrions-nous passer en revue certains de ces types d'arbres dans une série de structures de données avancées.
Applications des arbres
Les arbres en général ont toutes sortes de buts. Cependant, puisque nous n'avons couvert que les arbres de recherche binaires, nous allons commencer par là. L'utilisation principale d'un arbre de recherche binaire est juste pour cela - recherche . Dans les applications où nous pouvons déplacer fréquemment des données, un arbre de recherche binaire constitue un excellent choix.
Les arbres ont également de nombreuses autres applications importantes telles que la recherche de chemin, les algorithmes de compression, la cryptographie et les compilateurs. Comme nous pouvons le constater, l'étude des structures de données commence à ouvrir des portes sur des sujets informatiques beaucoup plus intéressants. C'est pourquoi il est important d'avoir des fondamentaux solides. Ils constituent la base de presque tous les sujets que nous voudrions explorer.
Syntaxe de l'arborescence Java
Pour créer un arbre, nous devrons retravailler un peu notre ancienne classe de nœuds. En particulier, nous devrons changer ce prochain pointeur en un ensemble de pointeurs. Cependant, puisque nous avons passé tout ce temps à parler d'arbres de recherche binaires, autant aller de l'avant et en implémenter un. Cela signifie que notre nouvelle classe de nœuds doit prendre en charge deux pointeurs au lieu d'un. Appelons ces pointeurs gauche et droite.
public class Node {
private int payload;
private Node left;
private Node right;
// Implicit getters/setters/constructors
} Super! Maintenant que nous avons une nouvelle classe Node, nous pouvons définir la classe d'arbre de recherche binaire.
Définition de classe
Une arborescence de base doit au moins prendre en charge les fonctionnalités suivantes :insérer, supprimer, rechercher et parcourir. De plus, les arbres doivent également prendre en charge la fonctionnalité de rotation qui modifie la structure de l'arbre sans modifier l'ordre. Nous ne toucherons pas à la rotation pour l'instant, mais nous nous occuperons de tout le reste. Pour l'instant, implémentons une classe de base.
public class BinarySearchTree {
private Node root;
// Implicit getters/setters/constructors
} Et c'est tout! Un arbre est assez simple. Nous avons juste besoin d'une référence à la racine, et nous sommes prêts à commencer à stocker des données. La magie opère lors de l'insertion. C'est là que nous mettrons en œuvre notre logique pour déterminer le type d'arbre que nous avons.
Insertion
Puisque nous implémentons un arbre de recherche binaire, nous aurons besoin de notre insertion pour naviguer correctement dans l'arbre. Pour ce faire, nous pourrions utiliser une boucle. Cependant, cela peut devenir assez délicat car nous ne connaissons pas exactement la profondeur de l'arbre à un moment donné. Au lieu de cela, nous allons utiliser la récursivité. Après tout, les arbres sont une famille de structures de données récursives.
public Node insert(Node root, int payload) {
if (root == null) {
root = new Node(payload);
} else if (payload < root.getPayload()) {
root.setLeft(insert(root.getLeft(), payload));
} else if (payload > root.getPayload()) {
root.setRight(insert(root.getRight(), payload));
}
return root;
} Fondamentalement, la façon dont cela fonctionne est que nous vérifions d'abord si la racine est nulle. Si c'est le cas, nous commençons notre arbre à partir de zéro. Sinon, nous vérifions si le nouveau nœud va aller du côté gauche ou droit de la racine. Quel que soit le côté, nous effectuons ensuite à nouveau un appel récursif à la méthode d'insertion. Cependant, cette fois, nous changeons la racine. Ce processus se poursuit jusqu'à ce que nous atteignions notre cas de base qui est une racine nulle.
Nous pouvons imaginer que cela fonctionne car à un moment donné, nous n'avons affaire qu'à un maximum de trois nœuds. Ces trois nœuds forment un arbre miniature avec un seul parent et deux enfants. Nous continuerons à descendre jusqu'à ce que nous rencontrions un enfant vide. À ce stade, nous attribuons l'enfant à son parent et remontons l'arborescence. À la fin, nous renverrons la racine de l'arbre qui contient maintenant le nouveau nœud.
Suppression
La suppression est un peu plus délicate car nous devrons peut-être retirer certains nœuds. L'extrait de code suivant devrait faire exactement cela.
public Node delete(Node root, int payload) {
if (root == null) {
throw new NoSuchElementException("Element does not exist");
} else if (payload < root.getPayload()) {
root.setLeft(delete(root.getLeft(), payload));
} else if (payload > root.getPayload()) {
root.setRight(delete(root.getRight(), payload));
} else {
if (root.getLeft() == null) {
root = root.getRight();
} else if (root.getRight() == null) {
root = root.getLeft();
} else {
tempNode = root.getLeft();
while(tempNode.getRight() != null) {
tempNode = tempNode.getRight();
}
root.setPayload(tempNode.getPayload);
root.setLeft(delete(root.getLeft(), tempNode.getPayload()));
}
}
return root;
} Comme nous pouvons le voir, delete fonctionne presque exactement de la même manière que insert. Nous parcourons simplement l'arbre jusqu'à ce que nous trouvions le nœud dont nous avons besoin. Cependant, il y a un nouveau cas spécial qui se produit une fois que nous l'avons trouvé. Fondamentalement, nous vérifions simplement s'il existe un nœud gauche. Sinon, nous tirons le bon nœud et l'appelons un jour. De même, s'il n'y a pas de nœud droit, nous remontons le nœud gauche.
Malheureusement, la décision n'est pas toujours aussi simple. Si les nœuds gauche et droit existent, nous avons besoin d'un moyen de remplir le nœud que nous venons de supprimer. Pour ce faire, nous tirons en fait le nœud le plus à droite sur le côté gauche. Oui, cela semble déroutant, mais fondamentalement, nous voulons juste le plus grand nœud sur le côté gauche. De cette façon, nous pouvons confirmer que tout est toujours organisé.
Une fois que nous avons saisi le plus grand nœud du sous-arbre de gauche, nous stockons sa charge utile dans notre racine actuelle. Ensuite, nous supprimons ce nœud. Pour ce faire, nous effectuons en fait un autre appel récursif à delete. Cela finira par filtrer et détecter le cas où les deux enfants sont nuls. Dans ce cas, nous le définissons simplement sur null.
Rechercher
Maintenant que nous comprenons l'insertion et la suppression, la recherche devrait être une blague. Avec la recherche, nous avons deux cas de base :la racine est nulle ou la racine est égale à la valeur que nous essayons de trouver.
public boolean search(Node root, int payload) {
if (root == null) {
return false;
} else if (root.getPayload() == payload) {
return true;
} else if (payload < root.getPayload()) {
return search(root.getLeft());
} else {
return search(root.getRight());
}
} Cela devrait être tout ce dont nous avons besoin pour lancer une recherche rapide. En règle générale, nous voudrions éviter autant d'instructions de retour, mais dans ce cas, la méthode est assez simple.
Traversée
D'accord, il semble donc que nous en ayons fini avec les arbres. Cependant, nous n'avons pas tout à fait terminé. Nous devons aborder un sujet appelé traversée pendant un moment. La raison en est que nous devons parfois nous assurer que nous avons visité chaque nœud une fois. C'est un concept avec lequel nous devrons certainement nous familiariser avant de commencer à parler de graphiques.
Sur les listes, ce n'était pas vraiment un problème. Nous pouvons simplement courir du début à la fin pour terminer une traversée. Sur un arbre, cependant, nous avons des options :en commande, en précommande et après la commande. Ces trois traversées différentes ont des objectifs différents mais atteignent finalement le même objectif :visiter chaque nœud d'un arbre exactement une fois.
Le but du parcours dans l'ordre est de fournir une copie linéaire des données dans l'arbre. Pour un arbre de recherche binaire, cela signifie créer une liste triée à partir de toutes les données de l'arbre. La traversée de pré-ordre est généralement utilisée pour cloner un arbre, mais elle est également utilisée pour produire une expression de préfixe à partir d'un arbre d'expression. Enfin, Post-order est utilisé pour supprimer des arbres, mais il peut également être utilisé pour générer une expression postfixée à partir d'un arbre d'expression. Ce qui suit détaille l'ordre de traversée des nœuds pour chacune de ces méthodes de traversée :
- Dans l'ordre :gauche, racine, droite
- Précommande :racine, gauche, droite
- Post-commande :gauche, droite, racine
Bien qu'il existe d'autres stratégies de traversée, celles-ci sont fondamentales. Nous devrions nous familiariser avec eux.
Résumé
Comme indiqué à plusieurs reprises déjà, les arbres n'ont aucune propriété inhérente pour des raisons de performance. Par conséquent, le tableau suivant ne détaille que les performances des arbres de recherche binaires.
| Algorithme | Durée d'exécution |
|---|---|
| Accès | O(N) |
| Insérer | O(N) |
| Supprimer | O(N) |
| Rechercher | O(N) |
Gardez à l'esprit que tous les tableaux de cette série supposent le pire des cas. Un arbre de recherche binaire n'est que le pire des cas lorsqu'il dégénère en une liste chaînée. En d'autres termes, nous obtenons une chaîne de nœuds gauches sans nœuds droits ou vice versa.
Comme toujours, merci d'avoir pris le temps de vérifier The Renegade Coder aujourd'hui. J'espère que vous avez appris quelque chose !