La structure de données du tableau
Maintenant que nous avons éliminé une partie de la théorie importante, nous pouvons revoir notre vieil ami, le tableau. Lorsque nous avons commencé à parler de tableaux, il y avait cette mention selon laquelle ils étaient une structure de données assez simple. C'était plus une référence à la facilité avec laquelle les tableaux peuvent travailler syntaxiquement. En réalité, il se passe pas mal de choses sous le capot.
Dans cette leçon, nous allons plonger dans la structure physique réelle d'un tableau en mémoire. Ensuite, nous commencerons à parler de ses cas d'utilisation avant de finalement lier ses opérations à Big O.
Qu'est-ce qu'un tableau ?
Un tableau est une section contiguë de la mémoire qui est divisée en blocs ou éléments. Ces éléments sont de taille fixe et ne peuvent jamais changer pendant la durée de vie du tableau. Par conséquent, nous ne pouvons jamais modifier le type de données que nous stockons.
Il s'avère que cela est particulièrement vrai pour les types primitifs bien que nous ayons un peu plus de flexibilité avec les objets. C'est parce que les objets sont des types de référence, ils sont donc en fait stockés par une adresse mémoire. Java n'a pas à faire de travail supplémentaire pour décider de la taille de chaque élément puisque les adresses mémoire ont une taille fixe.
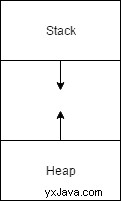
Cela nous amène à cette notion de tas. Vous vous souvenez de l'époque où nous parlions de méthodes ? Dans cette leçon, nous avons couvert la pile. Eh bien, le tas est son homologue. Si les appels de méthode reposent sur la pile, toutes ces références d'objet remplissent le tas.
Le tas et la pile sont situés aux extrémités opposées de la mémoire. Au fur et à mesure que chaque extrémité grandit, l'espace entre elles se rétrécit. La pile se nettoie lorsque les appels de méthode sortent, mais le tas s'appuie sur le ramasse-miettes. Au fur et à mesure que les références disparaissent de la pile, le tas peut commencer à effacer ses objets. Gardez cela à l'esprit lorsque nous commençons à jouer !
Propriétés des tableaux
En raison de sa structure, le tableau a des propriétés assez intéressantes.
Accès aléatoire
D'une part, l'accès aux données est une opération à temps constant ou O(1). Si on se rappelle de la dernière leçon, les éléments sont accessibles par un simple calcul :
memory_address_of(element_n) = memory_address_of(element_0) + size_of_element * index_of(element_n)
Nous appelons cet accès aléatoire car il coûte le même quel que soit l'index que nous choisissons.
Insertion et suppression linéaires
Maintenant, les choses se compliquent un peu si nous voulons faire des insertions ou des suppressions. Comme nous ne pouvons pas réellement ajouter ou supprimer un index au milieu d'un tableau, nous devons déplacer les informations.
[4, 6, 8, 0] \\ Let's delete 4 [6, 8, 0, 0] \\ Now, let's insert 5 at index 1 [6, 5, 8, 0] \\ Elements had two shift around in both cases
Dans le cas d'une insertion, le mieux que l'on puisse faire est O(N). En effet, tous les éléments à droite du point d'insertion doivent être décalés d'un indice vers le bas.
Naturellement, les suppressions suivent. La suppression d'un élément nécessite que tous les éléments à droite du point de suppression soient décalés d'un indice vers le haut.
Taille fixe
Une autre caractéristique importante des tableaux est qu'ils sont de taille fixe. Cela devient tout à fait le problème si nous voulons ajouter des données au tableau. Cette opération finit par être O(N) si nous n'avons pas de référence explicite au dernier élément vide. Même si nous le faisons, nous nous retrouvons toujours avec une opération O(N) car le tableau finira par atteindre sa capacité maximale.
À ce stade, soit nous ignorons la nouvelle valeur, soit nous allouons un tout nouveau tableau (généralement beaucoup plus grand que le premier). Ensuite, nous sommes obligés de copier chaque élément du tableau d'origine dans le nouveau tableau. Le coût de cette opération est O(N), et ce n'est généralement pas quelque chose que nous voulons faire très souvent. Au lieu de cela, nous essayons généralement d'allouer une taille dans le pire des cas pour le tableau. De cette façon, nous savons que nous ne dépasserons jamais ses limites.
Rechercher et trier
Grâce à la puissance de l'accès aléatoire, la recherche est plutôt bien optimisée. Si le tableau est trié, nous pouvons en fait demander un élément et trouver son index dans O(log(N)). C'est parce que nous pouvons exécuter un petit algorithme amusant appelé recherche binaire. Imaginons que nous ayons un tableau comme suit :
[3, 5, 6, 7, 11, 15, 18, 32, 33, 34, 79]
Si nous voulions voir si le tableau contenait la valeur 33, nous pourrions le découvrir en commençant à une extrémité et en itérant jusqu'à ce que nous le trouvions à l'index 8. Cependant, comme le tableau est déjà trié, nous pouvons utiliser une petite astuce appelée binaire chercher.
Avec la recherche binaire, nous testons l'index du milieu et déterminons dans quelle moitié rechercher ensuite. Ce processus se poursuit jusqu'à ce que nous identifions notre valeur demandée. La puissance de cet algorithme vient du fait que nous tuons la moitié de l'espace de recherche à chaque itération.
Donc, dans ce cas, la recherche binaire commencerait par saisir l'index 6. À l'index 6, nous avons la valeur 15, nous savons donc que 33 doit apparaître dans la moitié supérieure du tableau. Le prochain indice que nous saisissons est 8, ce qui donne notre résultat. Avec cet algorithme, nous avons identifié notre demande en seulement deux itérations contre neuf avec un balayage linéaire de base. Gardez cela à l'esprit lorsque nous passons aux listes liées.
Applications des tableaux
La puissance des tableaux vient de leur propriété d'accès aléatoire alors que leur point crucial est leur propriété de taille fixe. En conséquence, les applications typiques des tableaux incluent la gestion des entrées de l'utilisateur (voir l'exemple Grader mentionné précédemment), le tri, la multiplication matricielle et la mise en œuvre d'autres structures de données (c'est-à-dire les piles et les files d'attente). Bien sûr, il existe de nombreuses autres applications, mais nous n'en aborderons que quelques-unes ci-dessous.
Trier
Disons que nous avons des données que nous voulons trier et que nous savons combien de données nous avons. Eh bien, nous pouvons vider ces données dans un tableau et y effectuer un tri :
int[] x = {1, 6, -5, 4, 17};
Arrays.sort(x); L'extrait de code ci-dessus exploite le package Arrays de Java qui peut être utilisé pour trier un tableau en place. De nombreux langages ont une fonctionnalité similaire à celle de Python (où les tableaux ressemblent davantage à des listes de tableaux) :
x = [1, 6, -5, 4, 17] x.sort()
Quoi qu'il en soit, le tri est une application assez normale des tableaux.
Implémentation d'autres structures de données
Les tableaux étant des structures de données de première classe dans de nombreux langages, ils servent souvent de bloc de construction pour d'autres structures de données telles que les piles, les files d'attente et les listes de tableaux.
Si nous voulions implémenter une file d'attente à l'aide d'un tableau, nous aurions besoin de suivre deux points :avant et arrière. Le pointeur avant changeait chaque fois qu'un utilisateur ajoutait un élément à la file d'attente tandis que le pointeur arrière changeait chaque fois qu'un utilisateur supprimait un élément de la file d'attente.
De même, nous pourrions implémenter une pile à l'aide d'un tableau en ajoutant la fonctionnalité push et pop. Ici, nous n'aurions besoin de maintenir qu'un seul pointeur vers le haut de la pile.
Dans les deux cas, nous devons toujours tenir compte des limites de la taille d'un tableau lorsque nous l'utilisons pour créer d'autres structures de données. Naturellement, c'est pourquoi nous avons tendance à opter pour une liste de tableaux qui gère les situations où nous pourrions manquer d'espace.
Syntaxe de tableau Java
Ce ne serait pas un tutoriel Java si nous ne regardions pas au moins certains tableaux dans le code. Les sections suivantes décrivent la syntaxe de base entourant un tableau Java.
Création
Si nous nous souvenons de la dernière leçon de la série Java Basics, nous nous souviendrons qu'un tableau peut être défini comme suit :
int[] myIntegerArray = new int[10];
Dans ce code, nous déclarons un tableau d'entiers où le nombre maximum d'entiers que nous pouvons stocker est 10. Cependant, ce n'est pas la seule façon de créer un tableau :
int[] myIntegerArray = {5, 10, 15, 20, 26}; Dans cet exemple, nous créons un tableau de taille 5 avec des valeurs par défaut. Si nous choisissons d'utiliser le premier exemple, Java est assez agréable pour toutes les valeurs par défaut à 0.
Indexation
Maintenant, la syntaxe pour accéder à un élément ressemble à ceci :
int value = myIntegerArray[3];
Ici, nous accédons au 3e index du tableau qui pointe en fait vers ce que nous appellerions probablement le 4e élément :c'est parce que les indices du tableau commencent à 0.
[index 0, index 1, index 2, index 3]
Bien que cela puisse sembler un peu déroutant, cela suit directement l'équation d'accès aléatoire. Par exemple, si nous voulons l'adresse mémoire du premier élément, nous utiliserons un index de 0 dans l'équation d'accès aléatoire. Cet index nous permet d'éliminer le décalage de l'équation et de renvoyer simplement l'adresse mémoire de départ.
Soyez prudent lorsque vous indexez un tableau. Tout index en dehors de ses limites entraînera une ArrayIndexOutOfBoundsException . En d'autres termes, Java ne nous permettra pas de fouiller la mémoire en dehors des limites de ce dont nous avons dit avoir besoin.
Traversée
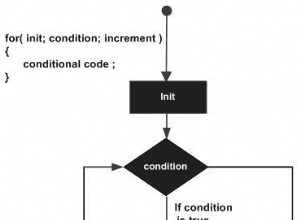
Pour parcourir tous les éléments d'un tableau, nous pouvons utiliser la boucle suivante :
for (int i = 0; i < myIntegerList.length; i++) {
System.out.println(myIntegerList[i]);
} Ici, nous pouvons voir que les tableaux ont une propriété appelée longueur. Cela nous permet d'obtenir la taille du tableau en temps constant. Encore une fois, soyez prudent. La longueur renvoie sa taille réelle, donc une longueur de 10 signifie qu'il y a 10 éléments dans le tableau. Cependant, l'indice du dernier élément sera 9. Par conséquent, ce qui suit générera toujours une erreur :
int value = myIntegerList[myIntegerList.length];
Insertion
Insérer un élément dans un tableau est aussi simple que :
myIntegerArray[5] = 17;
Cependant, que se passe-t-il si l'index 5 contient des données que nous souhaitons conserver ? Comme indiqué précédemment, l'insertion est vraiment un algorithme O(N) car nous devons décaler tous les éléments vers le bas. L'algorithme d'insertion pourrait alors ressembler davantage à ce qui suit :
public static void insert(int[] myIntegerList, int position, int value) {
for (int i = myIntegerList.length - 1; i > position; i--) {
myIntegerList[i] = myIntegerList[i - 1];
}
myIntegerList[position] = value;
} La suppression est presque exactement la même sauf que nous décalons les éléments restants vers le haut.
Résumé
Étant donné que toute cette série est axée sur les structures de données, nous ne lui rendrions pas justice si nous ne résumions pas les mesures de performances pour les différentes opérations sur un tableau.
| Algorithme | Durée d'exécution |
|---|---|
| Accès | O(1) |
| Insérer | O(N) |
| Supprimer | O(N) |
| Recherche (non triée) | O(N) |
| Recherche (triée) | O(log(N)) |
C'est ça! Connectez-vous la prochaine fois pour en savoir plus sur les listes liées. Dans cette leçon, nous examinerons les listes liées presque de la même manière. Ensuite, à la fin, nous ferons une petite comparaison et un contraste pour les deux structures de données que nous avons apprises jusqu'à présent.