Comment terminer un projet de programmation à partir de zéro
Actuellement, je suis dans mon dernier semestre d'enseignement d'un cours de programmation de deuxième année sur les composants logiciels en Java, et je suis à ce moment du semestre où nous décollons les roues d'entraînement. En d'autres termes, nous arrêtons de donner un modèle aux étudiants et leur demandons plutôt de réaliser un projet de programmation à partir de zéro.
Lorsque nous faisons cela, il y a toujours une montée de panique chez les étudiants. Comme nous avons toujours fourni un modèle jusqu'à ce point, ils ont très peu d'intuition pour commencer. En conséquence, j'ai pensé que je leur ferais un article qui partagerait quelques trucs et astuces que j'ai utilisés au fil des ans.
Dans cet article, je partagerai exactement le projet que nous demandons à nos étudiants de réaliser, et je partagerai quelques façons que je recommanderais de commencer.
Aperçu du projet
Au cours d'un semestre, nous demandons à nos étudiants de réaliser 11 projets Java. Chacun de ces projets est livré avec une quantité considérable de code de modèle qui sert de solution provisoire pour des projets plus intéressants.
Par exemple, pour le 4e projet, nous demandons aux élèves de créer un lecteur RSS qui affiche un flux RSS sous la forme d'une page Web HTML. Au lieu de leur demander de le faire à partir de zéro, nous fournissons 5 méthodes vides avec des contrats détaillés. Tout ce que les étudiants ont à faire est de remplir les méthodes, et ils auront un lecteur RSS fonctionnel.
Ce n'est qu'au 10ème projet que nous demandons aux élèves de proposer leurs propres méthodes. En particulier, nous leur demandons d'écrire un programme capable de prendre une liste de termes et de définitions et de la transformer en un glossaire HTML. Par conséquent, les étudiants doivent implémenter une série de fonctionnalités, notamment :
- Une invite de saisie pour demander un fichier de termes et de définitions ainsi qu'un nom de dossier pour les fichiers de sortie
- Un fichier d'index contenant tous les termes est classé par ordre alphabétique
- Une série de pages de termes contenant les définitions des mots ainsi que des liens vers d'autres termes dans les définitions
De plus, nous utilisons nos propres composants logiciels. En conséquence, les étudiants ne sont pas en mesure de se tourner vers les bibliothèques disponibles et ainsi de suite dans la nature pour résoudre ce problème. Au lieu de cela, ils doivent travailler dans les limites de nos progiciels internes. Ces contraintes constituent un défi intéressant pour les étudiants car ils ne peuvent pas utiliser des structures de données comme ArrayList, des utilitaires de lecture de fichiers comme Scanner ou des bibliothèques de formatage HTML comme StringTemplate.
Si les étudiants veulent aller plus loin, ils peuvent obtenir des points bonus pour tester entièrement leur projet à l'aide de JUnit. Bien sûr, beaucoup ne s'en soucient pas.
Comment démarrer
Évidemment, quand les élèves reçoivent ce projet, ils sont un peu dépassés. Ils n'ont presque aucune idée de comment démarrer, et nous n'offrons généralement aucun conseil ou astuce (jusqu'à présent).
D'accord, ce n'est pas tout à fait vrai . En fait, nous les préparons pas mal, mais ils n'en sont pas toujours conscients. Au fur et à mesure que nous nous rapprochons de la tâche du glossaire, nous demandons à nos étudiants de mettre en œuvre des méthodes qui pourraient être utiles dans le projet pendant les laboratoires - nous ne leur disons tout simplement pas explicitement leur valeur. L'idée étant qu'ils se souviendraient qu'ils ont mis en place quelque chose qui pourrait être utile. Malheureusement, ils ne font pas toujours ce lien.
Quoi qu'il en soit, nous sommes inévitablement submergés par toutes sortes de demandes d'aide d'étudiants. En fait, la semaine dernière, j'ai reçu une poignée d'e-mails avec toutes sortes de questions. Après avoir écrit un e-mail assez long à un étudiant, j'ai pensé que je pouvais faire demi-tour et convertir certains de mes conseils en une annonce officielle. Ensuite, j'ai pensé "pourquoi n'écrirais-je pas simplement un article qui pourrait aider encore plus de gens?" Donc, je l'ai fait.
Dans les sous-sections suivantes, nous examinerons quelques façons de démarrer un projet de programmation à partir de zéro.
Posez des questions de clarification
Avant de commencer un projet, c'est toujours une bonne idée de prendre du recul et de réfléchir à tout ce qu'on nous demande de faire. Comprenons-nous pleinement ce que veut le client ? Si quelque chose n'est pas clair, il est maintenant temps de contacter le client et de lui poser toutes les questions que nous avons.
Dans l'exemple ci-dessus, nous pourrions demander au client à quoi ressemble exactement le format du fichier d'entrée. Si possible, nous devrions leur demander de nous envoyer quelques échantillons, afin que nous ayons des informations que nous pouvons utiliser pour valider notre solution.
À ce stade du processus, nous ne devrions pas trop nous soucier de clouer chaque détail. Au lieu de cela, nous devrions demander au client d'identifier les éléments les plus importants du logiciel et de préciser ces exigences. Ensuite, lorsque nous commençons à mettre en œuvre la solution, nous pouvons recontacter le client si nous avons des questions supplémentaires.
Personne ne s'attend à ce que nous sachions exactement ce que nous ne savons pas.
Énumérer les tâches

Une fois que nous sommes à l'aise avec les exigences, c'est une bonne idée d'énumérer toutes les tâches que nous devrons accomplir. Ci-dessus, j'ai énuméré trois tâches principales décrivant trois éléments principaux de la conception :
- Une invite de saisie pour demander un fichier de termes et de définitions ainsi qu'un nom de dossier pour les fichiers de sortie
- Un fichier d'index qui contient tous les termes par ordre alphabétique
- Une série de pages de termes contenant les définitions des mots ainsi que des liens vers d'autres termes dans les définitions
La présentation de ces tâches est importante car elles peuvent être converties directement en méthodes. Par exemple, nous pourrions avoir une méthode qui lit les termes et les définitions d'un fichier et stocke le résultat dans une structure de données que nous pouvons utiliser plus tard. De même, nous pourrions également avoir une méthode qui génère la page d'index. Enfin, nous pourrions avoir une méthode qui génère chaque page de terme.
Si nous considérons les méthodes comme des tâches, nous serons sur la bonne voie pour mener à bien le projet.
Mapper le flux de données via les tâches
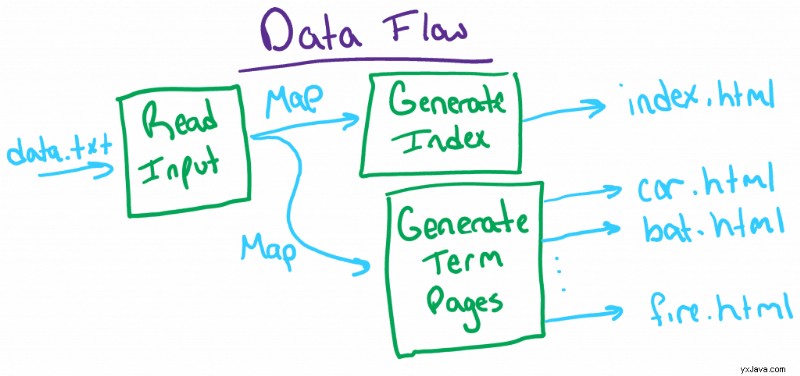
Maintenant que nous avons nos tâches, nous devons réfléchir à la manière dont les données circuleront dans chaque tâche. En d'autres termes, cela n'a aucun sens pour nous de nous plonger dans l'implémentation si nous ne savons même pas ce que chaque méthode doit attendre comme entrée ou produire comme sortie. Par exemple, nous ne pouvons pas écrire notre méthode de fichier d'index sans savoir comment les termes et les définitions sont stockés.
Pour cartographier le flux de données, il est probablement judicieux de travailler à partir de l'une des extrémités :soit le côté entrée du fichier de données, soit le côté sortie HTML. Dans les deux cas, nous savons exactement quelle sera la forme des données; nous avons juste besoin de relier les points.
Dans ce cas, il est probablement plus logique de commencer par la sortie et de réfléchir à la forme que doivent avoir les données pour faciliter notre travail. Plus précisément, nous savons que nous devons créer une page d'index de termes triés et des pages de termes avec des définitions. Pour la page d'index, nous voudrons probablement les termes dans une structure de données que nous pouvons trier. En ce qui concerne les pages de termes, nous voudrons probablement une structure de données qui facilite la récupération des termes et de leurs définitions.
Si nous étions très intelligents, nous trouverions une structure de données qui pourrait bien fonctionner dans les deux situations. Par exemple, si nous étions autorisés à utiliser des composants Java, nous pourrions opter pour un TreeMap qui est une carte spéciale où les clés sont triées selon leur ordre naturel.
Puisque nous savons que nous voulons un TreeMap, nous savons exactement comment nous devons stocker les termes et les définitions du fichier d'entrée. Maintenant, nous devons définir nos interfaces de tâches.
Définir les interfaces de tâche
À ce stade, le gros de la « réflexion » est terminé. Maintenant, nous pouvons commencer à créer notre propre modèle. Pour ce faire, nous devrons définir les interfaces de nos méthodes. Commençons par écrire nos trois méthodes sans aucune entrée ni sortie :
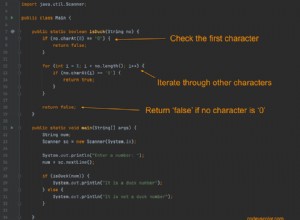
public static ... readTermsAndDefinitions( ... ) { ... }
public static ... generateIndexPage( ... ) { ... }
public static ... generateTermPages( ... ) { ... }
Avec ces méthodes esquissées, nous pouvons commencer à réfléchir à ce que chacun d'eux va faire. Tout d'abord, le readTermsAndDefinitions() La méthode analysera un fichier d'entrée et le convertira en TreeMap. En d'autres termes, il devrait probablement prendre un Scanner et renvoyer un TreeMap :
public static TreeMap<String, String> readTermsAndDefinitions(Scanner input) { ... } Pendant ce temps, les deux autres méthodes sont assez similaires. Ils intégreront tous les deux notre TreeMap et généreront des pages Web. Comme nous n'avons défini aucune fonctionnalité supplémentaire, nous allons continuer et supposer que ces méthodes ne renvoient rien (par exemple, une chaîne ou une liste de chaînes). Au lieu de cela, nous leur demanderons d'écrire directement dans les fichiers appropriés :
public static void generateIndexPage(TreeMap<String, String> termsAndDefs) { ... }
public static void generateTermPages(TreeMap<String, String> termsAndDefs) { ... }
Maintenant, nous avons fait quelques hypothèses assez importantes avec ces méthodes. Tout d'abord, nous avons supposé que tous les noms de fichiers pouvaient être déduits du termsAndDefs paramètre. Par exemple, nous pourrions nommer chaque page de terme après le terme (par exemple car.html, bat.html, etc.). De même, la page d'index a été supposée être index.html.
Étant donné que le client n'a fait aucune demande concernant la façon dont les pages sont nommées, nous n'avons aucune donnée supplémentaire que nous pourrions transmettre à partir de l'entrée. Par conséquent, c'est à nous de décider comment nous implémentons les conventions de nommage en interne. Si nous choisissons un schéma de nommage qui nécessite des informations supplémentaires, nous devrons peut-être modifier ces interfaces.
Pour l'instant cependant, passons à autre chose.
Comment remplir un modèle
Maintenant que nous avons conçu notre propre modèle, nous pouvons commencer à le remplir. Cependant, je veux faire une pause et dire que le développement de logiciels ne fait que devenir plus compliqué à partir d'ici. Bien qu'il puisse être agréable d'avoir notre propre modèle, nous découvrirons rapidement que les plans peuvent changer. Lorsque cela se produira, nous devrons être en mesure de nous ajuster en conséquence.
Quoi qu'il en soit, allons-y et parlons de la façon de remplir un modèle.
Décomposer les tâches en sous-tâches
Lorsque nous avons commencé à dresser notre liste de tâches dans la section précédente, nous pensions à une vue d'ensemble. Lorsqu'il s'agit de mettre en œuvre ces tâches, nous pouvons constater qu'il y a un peu de complexité.
Par exemple, parlons du readTermsAndDefinitions() méthode. Tout d'abord, nous devons lire et analyser un fichier. Selon la façon dont le fichier est formaté, cela pourrait être une tâche assez difficile. Par exemple, comment analyserions-nous le fichier suivant :
tâche ::un travail à faire ou à entreprendre.
labor::work, particulièrement un travail physique pénible.
effort::une tentative pour atteindre un objectif.
entreprise ::un projet ou une entreprise, généralement difficile ou nécessitant des efforts.
Ici, chaque terme et définition sont imprimés sur une ligne distincte. Le terme est ensuite séparé de la définition à l'aide d'un double-virgule.
Pour lire ceci, nous pourrions utiliser le Scanner pour lire chaque ligne. Nous pourrions ensuite transmettre cette ligne à une méthode d'assistance qui pourrait analyser la ligne en deux parties - terme et définition - et renvoyer le résultat dans une structure de données facile à utiliser. Encore mieux, nous pourrions passer un TreeMap et la chaîne à cette méthode où le TreeMap serait mis à jour directement.
Décomposer les tâches en sous-tâches peut être un peu compliqué. En général, il est probablement préférable de se lancer dans la mise en œuvre. Ensuite, au fur et à mesure que la méthode se développe, réfléchissez à des moyens d'extraire du code utile dans des méthodes d'assistance. Ce processus itératif de modification de la structure de code sous-jacente sans altérer le comportement externe est appelé refactoring, et c'est une compétence importante à apprendre.
Tester le comportement, pas la mise en œuvre
Je vais casser le caractère ici pendant une seconde et dire qu'une fois, j'ai « plaidé » pour le test des méthodes privées. L'argument que j'ai avancé dans cet article est que rien dans les logiciels n'est absolu :parfois, il est acceptable de tester des méthodes privées.
Cela dit, en règle générale, il faut éviter de tester des méthodes privées, et c'est encore plus vrai lorsqu'un projet ne fait que démarrer. À ce stade du développement, le code est si fragile qu'il est impossible de se fier aux interfaces. Au lieu de cela, testez le comportement, pas la mise en œuvre.
Ce que je veux dire, c'est qu'il est important de commencer à écrire des tests pour le code au niveau de la tâche uniquement. Ce sont des méthodes que nous avons pris le temps de concevoir correctement, donc leurs interfaces ne devraient pas beaucoup changer, voire pas du tout. En conséquence, nous pouvons écrire nos tests sans craindre qu'ils ne se cassent parce que nous avons changé les signatures de méthode.
Dans notre cas, nous ne devrions écrire des tests que pour nos trois méthodes au niveau des tâches :readTermsAndDefinitions() , generateIndexPage() , et generateTermPages() . L'idée ici est que nous pouvons alors changer tout ce qui se passe sous le capot sans avoir à réécrire notre code de test; cela fonctionnera indéfiniment.
Ma seule mise en garde avec ce type de conception est qu'il peut parfois être difficile d'écrire des tests qui utilisent du code dans certaines des méthodes les plus profondes, en particulier s'ils couvrent des cas extrêmes de cas extrêmes.
De plus, parfois, les méthodes au niveau des tâches prennent en compte des données si complexes qu'il est difficile de vraiment concevoir des cas de test. Par exemple, supposons qu'une de nos méthodes au niveau des tâches nécessite une connexion à la base de données. Il serait probablement plus facile de tester simplement l'implémentation sous-jacente plutôt que de se moquer des connexions de base de données ou de créer carrément des bases de données de test. Cela dit, nous devrions probablement résister à cette tentation au moins pour le moment.
Polonais et présent
À ce stade, la solution est en voie d'achèvement. Au fur et à mesure que chaque méthode est remplie, nous devrons continuellement tester le comportement et confirmer le comportement attendu avec le client. Finalement, nous pourrons l'appeler quitte. Malheureusement, cependant, le gros du travail consiste à peaufiner le projet.
Comme pour la plupart des choses dans la vie, la réalisation d'un projet suit la règle des 80/20. En d'autres termes, 80% de notre temps sera consacré à peaufiner les derniers 20% du projet. Une fois que nous aurons mis en place l'essentiel des fonctionnalités, nous passerons le reste de notre temps à nous assurer que tout est en parfait état de fonctionnement.
Dans un projet comme celui-ci, les 20 derniers % représenteront les types de tâches suivants :
- Corriger les cas extrêmes de logique métier
- Modification du style de sortie HTML
- Mise en forme du texte pour les invites de saisie
- Générer des données de test
- Refactoriser la structure de la méthode sous-jacente
- Amélioration des performances
- Code de documentation
Ensuite, lorsque nous aurons enfin terminé, nous devrons préparer la solution pour la présentation. Dans ma classe, il n'y a pas de présentation formelle, mais le code doit être dans un format facile à utiliser. Par conséquent, nous demandons aux étudiants de soumettre leur code sous forme de fichier zip qui peut être importé directement dans Eclipse avec tous les mêmes paramètres de projet.
Assurez-vous de revenir une fois de plus avec le client pour avoir une idée exacte de ce à quoi ressemblent ses directives de soumission. Si tout se passe bien, nous aurons fini !
Conseils supplémentaires
Dans ma classe, la plupart des étudiants ne sont pas exposés à la manière dont les logiciels sont développés dans la nature. Par exemple, ils ne sont pas exposés aux différentes méthodologies de gestion de projet comme Agile et Waterfall. De même, ils ont une exposition très limitée aux outils logiciels tels que les tests, l'intégration continue et le contrôle de version.
Bien sûr, tout cet outillage est important. En fait, je dirais que chaque projet logiciel devrait au moins être contrôlé en version. Heureusement, le logiciel de contrôle de version est fortement pris en charge par la communauté et la plupart des gens connaissent les hubs de contrôle de version populaires tels que BitBucket, GitHub et GitLab. Si vous souhaitez commencer à créer votre premier référentiel, j'ai un court tutoriel qui exploite Git et GitHub.
En plus du contrôle de version, il peut être utile d'intégrer une technologie d'intégration continue (CI). Personnellement, j'aime TravisCI car il s'intègre directement dans GitHub, mais il existe une tonne d'outils CI. Par exemple, je pense que l'outil le plus populaire est Jenkins. S'ils sont correctement configurés, ces outils peuvent être utilisés pour tester le code à chaque validation. Ensuite, lorsque le projet est prêt à l'emploi, ces outils peuvent également déployer l'intégralité de la solution en votre nom.
Enfin, le codage est une bête sociale. Par conséquent, il est utile d'avoir une forme d'examen par les pairs intégrée au processus de développement. Dans la communauté technologique, nous avons renommé la revue par les pairs en revue de code, mais c'est la même idée :un groupe de pairs vérifiant la qualité du travail de quelqu'un. Naturellement, les révisions de code ne nécessitent pas de processus formel, mais il existe une tonne de littérature expliquant pourquoi elles sont importantes et comment en tirer le meilleur parti. De même, il existe une tonne d'outils logiciels qui intègrent des révisions de code de manière transparente, notamment GitHub et Swarm.
Partagez vos astuces
En tant que personne ayant un mélange d'expérience académique et industrielle, je ne peux pas dire que je suis un expert en développement de logiciels. Cela dit, j'ai suffisamment d'expérience pour proposer un processus décent pour naviguer dans de nouveaux projets, alors j'ai pensé que je lui donnerais une part.
Qu'en pensez-vous? Comment abordez-vous un tout nouveau projet ? Plongez-vous simplement ou faites-vous un peu de planification? Utilisez-vous des outils pour vous aider dans le processus de développement ? Travaillez-vous en équipe ou préférez-vous travailler en solo ? Quelle est votre stratégie générale pour refactoriser votre code ? Et comment prévoyez-vous des fonctionnalités supplémentaires une fois le projet "terminé" ?
Le développement de logiciels est un processus désordonné, et nous n'avons pas entièrement développé de grands processus pour faire le travail. Une partie de moi pense que c'est parce que nous traitons le développement logiciel comme une science dure alors qu'il s'agit souvent plus d'un art créatif. En d'autres termes, les projets grandissent et changent de manière organique au fil du temps et il n'est pas toujours clair où le projet finira. Comment concilier la réalité du changement avec le désir d'élaborer tous les scénarios possibles ?
Pendant que vous réfléchissez à certaines de ces questions, je vais faire ma prise habituelle. Tout d'abord, ce site compte sur des gens comme vous pour l'aider à se développer. Si vous souhaitez en savoir plus sur les moyens de soutenir le site, j'ai dressé une belle liste d'options qui incluent sauter sur la liste de diffusion et devenir un Patreon.
Deuxièmement, voici quelques ressources de conception de logiciels d'Amazon (publicité) :
- Les lois intemporelles du développement logiciel
- Clean Code :Un manuel de savoir-faire logiciel agile
Enfin, si cet article vous a plu, voici quelques articles triés sur le volet :
- Comment créer un référentiel Git à partir de rien :Git Init, GitHub Desktop, etc.
- Comment obscurcir le code en Python :une expérience de réflexion
- Vous pouvez tester des méthodes privées
Sinon, n'hésitez pas à partager vos réflexions ci-dessous dans les commentaires. Et, prenez soin de vous ! A la prochaine.