9 Suggerimenti ad alte prestazioni quando si utilizza MySQL con JPA e Hibernate
Introduzione
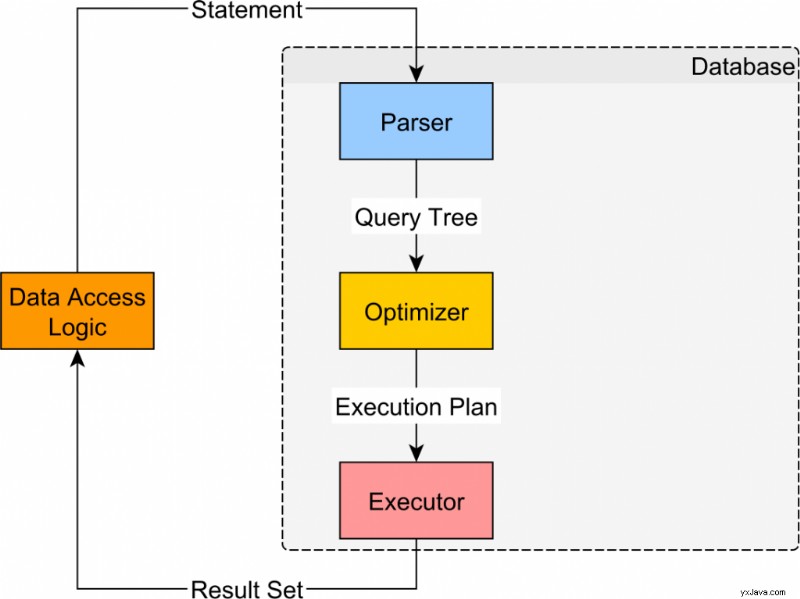
Sebbene esista uno standard SQL, ogni database relazionale è in definitiva univoco ed è necessario modificare il livello di accesso ai dati in modo da ottenere il massimo dal database relazionale in uso.
In questo articolo vedremo cosa puoi fare per aumentare le prestazioni quando usi MySQL con JPA e Hibernate.
Non utilizzare l'identificatore AUTO GeneratorType
Ogni entità deve avere un identificatore che identifichi in modo univoco il record della tabella associato a questa entità. JPA e Hibernate ti consentono di generare automaticamente identificatori di entità in base a tre diverse strategie:
- IDENTITÀ
- SEQUENZA
- TABELLA
Come spiegato in questo articolo, la strategia dell'identificatore TABLE non viene ridimensionata quando si aumenta il numero di connessioni al database. Inoltre, anche per una connessione al database, il tempo di risposta per la generazione dell'identificatore è 10 volte maggiore rispetto a quando si utilizza IDENTITY o SEQUENCE.
Se stai usando AUTO GenerationType :
@Id @GeneratedValue(strategy = GenerationType.AUTO) private Long id;
Hibernate 5 ricadrà sull'utilizzo del generatore TABLE, il che è negativo per le prestazioni.
Come ho spiegato in questo articolo, puoi facilmente risolvere questo problema con la seguente mappatura:
@Id @GeneratedValue(strategy= GenerationType.AUTO, generator="native") @GenericGenerator(name = "native", strategy = "native") private Long id;
Il generatore nativo sceglierà IDENTITY invece di TABLE.
Il generatore di IDENTITÀ disabilita gli inserimenti batch JDBC
Né MySQL 5.7 né 8.0 supportano gli oggetti SEQUENCE. Devi usare IDENTITY. Tuttavia, come spiegato in questo articolo, il generatore di IDENTITÀ impedisce a Hibernate di utilizzare gli inserimenti batch JDBC.
Gli aggiornamenti batch e le eliminazioni JDBC non sono interessati. Solo le istruzioni INSERT non possono essere raggruppate automaticamente da Hibernate perché, quando il contesto di persistenza viene svuotato, le istruzioni INSERT erano già state eseguite in modo che Hibernate sappia quale identificatore di entità assegnare alle entità che sono state mantenute.
Se vuoi risolvere questo problema, devi eseguire gli inserimenti batch JDBC con un framework diverso, come jOOQ.
Accelera i test di integrazione con Docker e tmpfs
MySQL e MariaDB sono notoriamente lenti quando devono scartare lo schema del database e ricrearlo ogni volta che sta per essere eseguito un nuovo test di integrazione. Tuttavia, puoi facilmente risolvere questo problema con l'aiuto di Docker e tmpfs.
Come spiegato in questo articolo, mappando la cartella dei dati in memoria, i test di integrazione verranno eseguiti quasi alla stessa velocità di un database in memoria come H2 o HSQLDB.
Utilizza JSON per i dati non strutturati
Anche quando si utilizza un RDBMS, molte volte si desidera archiviare dati non strutturati:
- dati provenienti dal client come JSON, che devono essere analizzati e inseriti nel nostro sistema.
- Risultati dell'elaborazione delle immagini che possono essere memorizzati nella cache per salvarli rielaborandoli
Sebbene non sia supportato in modo nativo, puoi facilmente mappare un oggetto Java su una colonna JSON. Puoi persino mappare il tipo di colonna JSON su un Jackson JsonNode.
Inoltre, non devi nemmeno scrivere questi tipi personalizzati, puoi semplicemente prenderli da Maven Central:
<dependency>
<groupId>com.vladmihalcea</groupId>
<artifactId>hibernate-types-55</artifactId>
<version>${hibernate-types.version}</version>
</dependency>
Bello, vero?
Utilizzare le stored procedure per salvare i roundtrip del database
Quando si elaborano grandi volumi di dati, non è molto efficiente spostare tutti questi dati dentro e fuori dal database. È molto meglio eseguire l'elaborazione sul lato database chiamando una stored procedure.
Per maggiori dettagli, consulta questo articolo su come chiamare una stored procedure MySQL con JPA e Hibernate.
Attento allo streaming di ResultSet
Lo streaming SQL ha senso per le applicazioni a due livelli. Se vuoi eseguire lo streaming di ResultSet, devi prestare attenzione anche al driver JDBC. Su MySQL, per utilizzare un cursore di database, hai due opzioni:
- o imposti il
StatementJDBCfetchSizeproprietà aInteger.MIN_VALUE, - oppure devi impostare il
useCursorFetchproprietà di connessione atruee quindi puoi impostare ilStatementJDBCfetchSizeproprietà a un valore intero positivo
Tuttavia, per le applicazioni basate sul Web, l'impaginazione è molto più adatta. JPA 2.2 introduce anche il supporto per i metodi Java 1.8 Stream, ma il piano di esecuzione potrebbe non essere efficiente come quando si utilizza l'impaginazione a livello SQL.
PreparedStatements potrebbe essere emulato
Poiché Hibernate usa PreparedStatements per impostazione predefinita, potresti pensare che tutte le istruzioni vengano eseguite in questo modo:
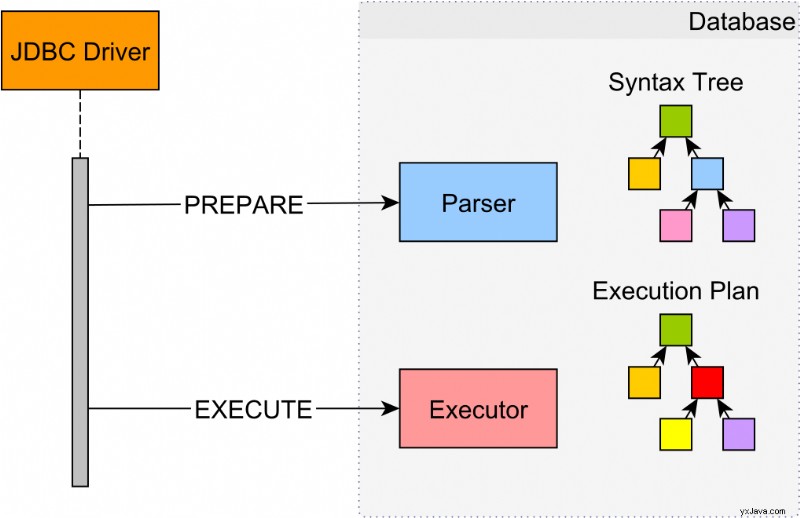
In realtà, vengono eseguiti più in questo modo:
Come ho spiegato in questo articolo, a meno che non imposti il useServerPrepStmts La proprietà MySQL JDBC Driver, PreparedStatements verrà emulata a livello di driver JDBC per salvare un roundtrip di database aggiuntivo.
Termina sempre le transazioni del database
In un database relazionale, ogni istruzione viene eseguita all'interno di una determinata transazione di database. Pertanto, le transazioni non sono facoltative.
Tuttavia, dovresti sempre terminare la transazione corrente in esecuzione, tramite un commit o un rollback. Dimenticare di terminare le transazioni può comportare la conservazione dei blocchi per molto tempo, oltre a impedire al processo di pulizia MVCC di recuperare vecchie tuple o voci di indice che non sono più necessarie.
Consegnare data/ora non è così facile
Ci sono due cose molto complicate nella programmazione:
- gestione delle codifiche
- trasmissione di data/ora su più fusi orari
Per risolvere il secondo problema, è meglio salvare tutti i timestamp nel fuso orario UTC. Tuttavia, prima di MySQL Connector/J 8.0, dovevi anche impostare useLegacyDatetimeCode Proprietà di configurazione del driver JDBC su false . A partire da MySQL Connector/J 8.0, non è necessario fornire questa proprietà.
Conclusione
Come puoi vedere, ci sono molte cose da tenere a mente quando usi MySQL con JPA e Hibernate. Poiché MySQL è uno degli RDBMS più implementati, utilizzato dalla stragrande maggioranza delle applicazioni Web, è molto utile conoscere tutti questi suggerimenti e regolare il livello di accesso ai dati per ottenere il massimo da esso.