Leer Apache Camel - Indexeer Tweets in realtime
In de meeste softwareontwikkelingsprojecten komt er een moment dat de app moet gaan communiceren met andere apps of componenten van derden.
Of het nu gaat om het verzenden van een e-mailmelding, het aanroepen van een externe API, het schrijven naar een bestand of het migreren van gegevens van de ene plaats naar de andere, u implementeert uw eigen oplossing of maakt gebruik van een bestaand framework.
Wat betreft bestaande frameworks in het Java-ecosysteem, aan de ene kant van het spectrum vinden we Tibco BusinessWorks en Mule ESB, en aan de andere kant Spring Integration en Apache Camel.
In deze tutorial laat ik je kennismaken met Apache Camel via een voorbeeldapp die tweets uit de voorbeeldfeed van Twitter leest en die tweets in realtime indexeert met Elastic Search.
Wat is Apache Camel?

Het integreren van een app met interne of externe componenten in een ecosysteem is een van de meest complexe taken in softwareontwikkeling en als het niet goed wordt gedaan, kan dit leiden tot een enorme puinhoop en een echte pijn om op de langere termijn te onderhouden.
Gelukkig is Camel, een open-source integratieframework dat wordt gehost bij Apache, gebaseerd op de Enterprise Integration Patterns en deze patronen kunnen helpen bij het schrijven van beter leesbare en onderhoudbare code. Net als bij Lego kunnen deze patronen worden gebruikt als bouwstenen om een solide softwareontwerp te maken.
Apache Camel ondersteunt ook een breed scala aan connectoren om uw app te integreren met verschillende frameworks en technologieën. En het speelt trouwens ook mooi samen met Spring.
Als je niet bekend bent met Spring, vind je dit bericht misschien nuttig:Twitter-feed verwerken met Spring Boot.
In de volgende secties bekijken we een voorbeeldtoepassing waarin Camel is geïntegreerd met zowel de Twitter-voorbeeldfeed als ElasticSearch.
Wat is ElasticSearch?
ElasticSearch, vergelijkbaar met Apache Solr, is een zeer schaalbare open-source, op Java gebaseerde full-text zoekmachine die bovenop Apache Lucene is gebouwd.
In deze voorbeeldtoepassing gaan we ElasticSearch gebruiken om tweets in realtime te indexeren en ook om in deze tweets te zoeken in volledige tekst.
Andere gebruikte technologieën
Naast Apache Camel en ElasticSearch heb ik ook andere frameworks in deze applicatie opgenomen:Gradle als de buildtool, Spring Boot als het webapplicatieframework en Twitter4j om tweets uit de Twitter-voorbeeldfeed te lezen.
Aan de slag
Het skelet van het project werd gegenereerd op http://start.spring.io waar ik de optie Web-afhankelijkheid aanvinkte, de sectie Projectmetadata invulde en 'Gradle Project' selecteerde als het type project.
Zodra het project is gegenereerd, kunt u het downloaden en importeren in uw favoriete IDE. Ik ga nu niet dieper in op Gradle, maar hier is de lijst met alle afhankelijkheden in het build.gradle-bestand:
def camelVersion = '2.15.2'
dependencies {
compile("org.springframework.boot:spring-boot-starter-web")
compile("org.apache.camel:camel-core:${camelVersion}")
compile("org.apache.camel:camel-spring-boot:${camelVersion}")
compile("org.apache.camel:camel-twitter:${camelVersion}")
compile("org.apache.camel:camel-elasticsearch:${camelVersion}")
compile("org.apache.camel:camel-jackson:${camelVersion}")
compile("joda-time:joda-time:2.8.2")
testCompile("org.springframework.boot:spring-boot-starter-test")
} Integratie met behulp van kameelroutes
Camel implementeert een boodschap georiënteerde architectuur en de belangrijkste bouwstenen zijn Routes die de stroom van de berichten beschrijven.
Routes kunnen worden beschreven in XML (oude manier) of Java DSL (nieuwe manier). We gaan alleen de Java DSL in dit bericht bespreken, want dat is de voorkeurs- en elegantere optie.
Oké, laten we dan eens kijken naar een eenvoudige route:
from("file://orders").
convertBodyTo(String.class).
to("log:com.mycompany.order?level=DEBUG").
to("jms:topic:OrdersTopic"); Er zijn een paar dingen om hier op te letten:
- Berichten stromen tussen eindpunten die worden vertegenwoordigd door en geconfigureerd met URI's
- Een route kan slechts één eindpunt voor het produceren van berichten hebben (in dit geval "file://orders", dat bestanden uit de map bestellingen leest) en meerdere eindpunten voor consumenten van berichten:
- “log:com.mycompany.order?level=DEBUG” die de inhoud van een bestand logt in een foutopsporingsbericht onder de logcategorie com.mycompany.order,
- “jms:topic:OrdersTopic” die de inhoud van het bestand in een JMS-onderwerp schrijft
- Tussen eindpunten kunnen de berichten worden gewijzigd, dwz:convertBodyTo(String.class) die de berichttekst converteert naar een String.
Houd er ook rekening mee dat dezelfde URI kan worden gebruikt voor een consumenteneindpunt in de ene route en een producenteindpunt in een andere:
from("file://orders").
convertBodyTo(String.class).
to("direct:orders");
from("direct:orders).
to("log:com.mycompany.order?level=DEBUG").
to("jms:topic:OrdersTopic"); Het directe eindpunt is een van de generieke eindpunten en maakt het mogelijk om berichten synchroon van de ene route naar de andere door te geven.
Dit helpt bij het maken van leesbare code en het hergebruiken van routes op meerdere plaatsen in de code.
Tweets indexeren
Laten we nu eens kijken naar enkele routes uit onze code. Laten we beginnen met iets simpels:
private String ES_TWEET_INDEXER_ENDPOINT = "direct:tweet-indexer-ES";
...
from("twitter://streaming/sample?type=EVENT&consumerKey={{twitter4j.oauth.consumerKey}}&consumerSecret={{twitter4j.oauth.consumerSecret}}∾cessToken={{twitter4j.oauth.accessToken}}∾cessTokenSecret={{twitter4j.oauth.accessTokenSecret}}")
.to(ES_TWEET_INDEXER_ENDPOINT)
; Dit is zo eenvoudig, toch? Inmiddels heb je misschien bedacht dat deze route tweets uit de Twitter-voorbeeldfeed leest en deze doorgeeft aan het "direct:tweet-indexer-ES" -eindpunt. Houd er rekening mee dat de consumerKey, consumerSecret, enz. zijn geconfigureerd en doorgegeven als systeemeigenschappen (zie http://twitter4j.org/en/configuration.html).
Laten we nu eens kijken naar een iets complexere route die leest vanaf het "direct:tweet-indexer-ES"-eindpunt en tweets in batches in Elasticsearch invoegt (zie opmerkingen voor gedetailleerde uitleg over elke stap):
@Value("${elasticsearch.tweet.uri}")
private String elasticsearchTweetUri;
...
from(ES_TWEET_INDEXER_ENDPOINT)
// groups tweets into separate indexes on a weekly basis to make it easier clean up old tweets:
.process(new WeeklyIndexNameHeaderUpdater(ES_TWEET_INDEX_TYPE))
// converts Twitter4j Tweet object into an elasticsearch document represented by a Map:
.process(new ElasticSearchTweetConverter())
// collects tweets into weekly batches based on index name:
.aggregate(header("indexName"), new ListAggregationStrategy())
// creates new batches every 2 seconds
.completionInterval(2000)
// makes sure the last batch will be processed before the application shuts down:
.forceCompletionOnStop()
// inserts a batch of tweets to elasticsearch:
.to(elasticsearchTweetUri)
.log("Uploaded documents to ElasticSearch index ${headers.indexName}: ${body.size()}")
; Opmerkingen over deze route:
- elasticsearchTweetUri is een veld waarvan de waarde door Spring wordt overgenomen uit het bestand application.properties (elasticsearch.tweet.uri=elasticsearch://tweet-indexer?operation=BULK_INDEX&ip=127.0.0.1&port=9300) en in het veld wordt geïnjecteerd
- Om aangepaste verwerkingslogica binnen een route te implementeren, kunnen we klassen maken die de processorinterface implementeren. Zie WeeklyIndexNameHeaderUpdater en ElasticSearchTweetConverter
- De tweets worden geaggregeerd met behulp van de aangepaste ListAggregationStrategy-strategie die berichten samenvoegt in een ArrayList en die later elke 2 seconden wordt doorgegeven aan het volgende eindpunt (of wanneer de toepassing stopt)
- Camel implementeert een expressietaal die we gebruiken om de grootte van de batch ("${body.size()}") en de naam van de index (${headers.indexName}) te loggen waarin berichten zijn ingevoegd van.
Tweets zoeken in Elasticsearch
Nu we tweets hebben geïndexeerd in Elasticsearch, is het tijd om er wat op te zoeken.
Laten we eerst kijken naar de route die een zoekopdracht ontvangt en de maxSize-parameter die het aantal zoekresultaten beperkt:
public static final String TWEET_SEARCH_URI = "vm:tweetSearch";
...
from(TWEET_SEARCH_URI)
.setHeader("CamelFileName", simple("tweet-${body}-${header.maxSize}-${date:now:yyyyMMddHHmmss}.txt"))
// calls the search() method of the esTweetService which returns an iterator
// to process search result - better than keeping the whole resultset in memory:
.split(method(esTweetService, "search"))
// converts Elasticsearch doucment to Map object:
.process(new ElasticSearchSearchHitConverter())
// serializes the Map object to JSON:
.marshal(new JacksonDataFormat())
// appends new line at the end of every tweet
.setBody(simple("${body}\n"))
// write search results as json into a file under /tmp folder:
.to("file:/tmp?fileExist=Append")
.end()
.log("Wrote search results to /tmp/${headers.CamelFileName}")
; Deze route wordt geactiveerd wanneer een bericht wordt doorgegeven aan het 'vm:tweetSearch'-eindpunt (dat een wachtrij in het geheugen gebruikt om berichten asynchroon te verwerken).
De SearchController-klasse implementeert een REST-API waarmee gebruikers een tweet-zoekopdracht kunnen uitvoeren door een bericht naar het 'vm:tweetSearch'-eindpunt te sturen met behulp van de ProducerTemplate-klasse van Camel:
@Autowired
private ProducerTemplate producerTemplate;
@RequestMapping(value = "/tweet/search", method = { RequestMethod.GET, RequestMethod.POST },
produces = MediaType.TEXT_PLAIN_VALUE)
@ResponseBody
public String tweetSearch(@RequestParam("q") String query,
@RequestParam(value = "max") int maxSize) {
LOG.info("Tweet search request received with query: {} and max: {}", query, maxSize);
Map<String, Object> headers = new HashMap<String, Object>();
// "content" is the field in the Elasticsearch index that we'll be querying:
headers.put("queryField", "content");
headers.put("maxSize", maxSize);
producerTemplate.asyncRequestBodyAndHeaders(CamelRouter.TWEET_SEARCH_URI, query, headers);
return "Request is queued";
} Dit activeert de uitvoering van Elasticsearch, maar het resultaat wordt niet geretourneerd in het antwoord maar geschreven naar een bestand in de map /tmp (zoals eerder besproken).
Deze route gebruikt de klasse ElasticSearchService om tweets te zoeken in ElasticSearch. Wanneer deze route wordt uitgevoerd, roept Camel de methode search() aan en geeft deze de zoekopdracht en de maxSize door als invoerparameters:
public SearchHitIterator search(@Body String query, @Header(value = "queryField") String queryField, @Header(value = "maxSize") int maxSize) {
boolean scroll = maxSize > batchSize;
LOG.info("Executing {} on index type: '{}' with query: '{}' and max: {}", scroll ? "scan & scroll" : "search", indexType, query, maxSize);
QueryBuilder qb = termQuery(queryField, query);
long startTime = System.currentTimeMillis();
SearchResponse response = scroll ? prepareSearchForScroll(maxSize, qb) : prepareSearchForRegular(maxSize, qb);
return new SearchHitIterator(client, response, scroll, maxSize, KEEP_ALIVE_MILLIS, startTime);
} Houd er rekening mee dat, afhankelijk van maxSize en batchSize, de code ofwel een normale zoekopdracht uitvoert die een enkele pagina met resultaten oplevert, ofwel een scrollverzoek uitvoert waarmee we een groot aantal resultaten kunnen ophalen. In het geval van scrollen, zal SearchHitIterator de volgende oproepen doen naar Elasticsearch om de resultaten in batches op te halen.
Elastische zoeken installeren
- Download Elasticsearch van https://www.elastic.co/downloads/elasticsearch.
- Installeer het in een lokale map ($ES_HOME)
- Bewerk $ES_HOME/config/elasticsearch.yml en voeg deze regel toe:
cluster.name:tweet-indexer - Installeer de BigDesk-plug-in om Elasticsearch te controleren:$ES_HOME/bin/plugin -install lukas-vlcek/bigdesk
- Voer Elasticsearch uit:$ES_HOME/bin/elasticsearch.sh of $ES_HOME/bin/elasticsearch.bat
Met deze stappen kunt u een zelfstandige Elasticsearch-instantie met minimale configuratie uitvoeren, maar houd er rekening mee dat ze niet bedoeld zijn voor productiegebruik.
De toepassing uitvoeren
Dit is het toegangspunt tot de toepassing en kan worden uitgevoerd vanaf de opdrachtregel.
package com.kaviddiss.twittercamel;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
public class Application {
public static void main(String[] args) {
SpringApplication.run(Application.class, args);
}
} Om de toepassing uit te voeren, voert u de methode Application.main() uit vanuit uw favoriete IDE of voert u de onderstaande regel uit vanaf de opdrachtregel:
$GRADLE_HOME/bin/gradlew build && java -jar build/libs/twitter-camel-ingester-0.0.1-SNAPSHOT.jar
Zodra de applicatie is opgestart, begint deze automatisch met het indexeren van tweets. Ga naar http://localhost:9200/_plugin/bigdesk/#cluster om uw indexen te visualiseren:
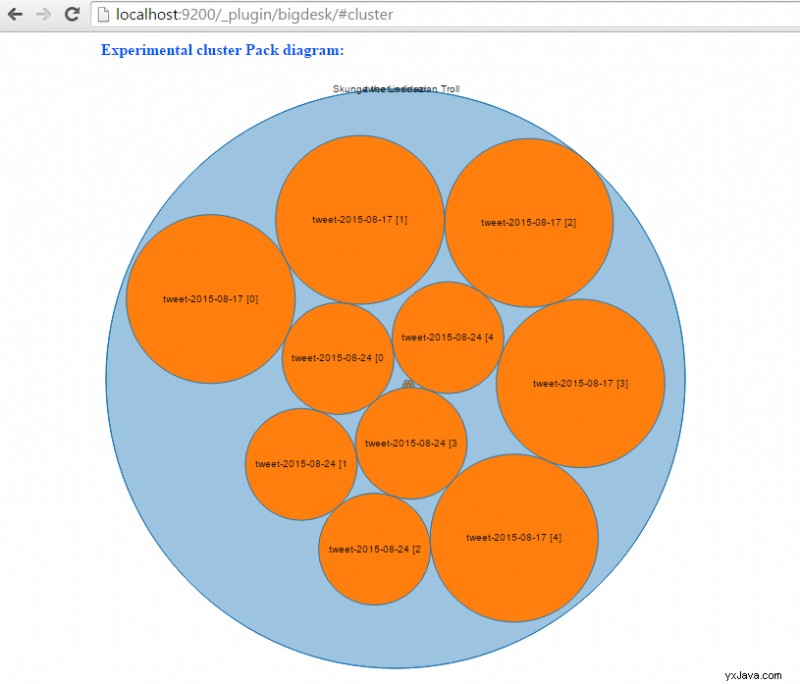
Om tweets te zoeken, voert u een URL in die er ongeveer op lijkt in de browser:http://localhost:8080/tweet/search?q=toronto&max=100.

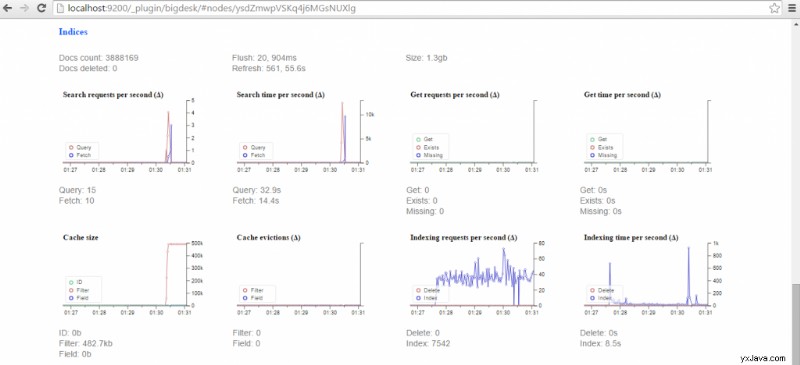
Met behulp van de BigDesk-plug-in kunnen we volgen hoe Elasticsearch tweets indexeert:
Conclusie
In deze inleiding tot Apache Camel hebben we besproken hoe je dit integratieframework kunt gebruiken om te communiceren met externe componenten zoals Twitter-voorbeeldfeed en Elasticsearch om tweets in realtime te indexeren en te doorzoeken.
- De broncode van de voorbeeldapp is beschikbaar op https://github.com/davidkiss/twitter-camel-ingester.