Input Split i Hadoop MapReduce
Når en MapReduce-jobb startes for å behandle en fil som er lagret i HDFS, er en av tingene Hadoop gjør å dele inn input i logiske splittelser, disse splittingene er kjent som input splits i Hadoop .
InputSplit representerer dataene som skal behandles av en individuell kartoppgave, noe som betyr at antall påbegynte kartleggere tilsvarer antallet input-splitter beregnet for jobben. For eksempel hvis inngangsdata er logisk delt inn i 8 inngangsdelinger, vil 8 kartleggere startes for å behandle disse inngangsdelingene parallelt.
Input split er en logisk inndeling av data
Inndatadeling er bare den logiske inndelingen av dataene, den inneholder ikke de fysiske dataene. Hva input split refererer til i denne logiske inndelingen er postene i dataene . Når mapper behandler inngangsdelingen, fungerer den faktisk på postene ((nøkkel, verdi)-par) med i den inndatadelingen i Hadoop.
Med i Hadoop-rammeverket er det InputFormat klasse som deler opp inndatafilene i logiske InputSplits.
Det er RecordReader-klassen som deler opp dataene i nøkkel/verdi-par som deretter sendes som input til Mapper.
InputFormat-klassen i Hadoop Framework
public abstract class InputFormat<K, V> {
public abstract List<InputSplit> getSplits(JobContext context) throws IOException, InterruptedException;
public abstract RecordReader<K,V> createRecordReader(InputSplit split, TaskAttemptContext context) throws IOException, InterruptedException;
} Input Split vs HDFS-blokker
Mange mennesker blir forvirret mellom HDFS-blokkene og inngangsdelingene, siden HDFS-blokken også er delingen av data i mindre biter som deretter lagres på tvers av klyngen. Dessuten er det til syvende og sist dataene som er lagret i nodene som behandles av MapReduce-jobben, og det som faktisk er oppgaven med å dele inn input i Hadoop.
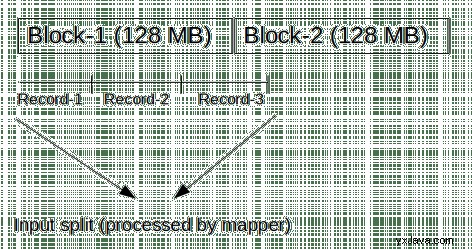
HDFS-blokken er den fysiske representasjonen av dataene, faktiske data lagres med i Hadoop Distributed File System. Hvor som input split er bare den logiske representasjonen av dataene. Når data er delt inn i blokker for lagring i HDFS, deler det bare dataene i biter på 128 MB (standard blokkstørrelse) uten hensyn til postgrenser.
For eksempel hvis hver post er 50 MB, vil to poster passe inn i blokken, men den tredje posten vil ikke passe, 28 MB av den tredje posten vil bli lagret i en annen blokk. Hvis en kartlegger behandler en blokk, vil den ikke kunne behandle den tredje posten, da den ikke får hele posten.
Input split som er logisk representasjon av dataene respekterer logiske postgrenser. Ved å bruke startposten i blokken og byteforskyvningen kan den få hele posten selv om den strekker seg over blokkgrensene. Dermed vil kartleggeren som jobber med inndatadelingen kunne behandle alle 3 postene selv om en del av tredje post er lagret i en annen blokk.
Relaterte innlegg
- Eneste Mapper Job i Hadoop MapReduce
- Hva er datalokalitet i Hadoop
- Spekulativ utførelse i Hadoop Framework
- Distribuert buffer i Hadoop
- Uber-oppgave i YARN
- Datakomprimering i Hadoop Framework
- Hvordan bruke LZO-komprimering i Hadoop
- GenericOptionsParser And ToolRunner i Hadoop
Det er alt for emnet Input Split i Hadoop MapReduce . Hvis noe mangler eller du har noe å dele om emnet, vennligst skriv en kommentar.