JPA- og Hibernate-bufferen på andre nivå
Innledning
I denne artikkelen skal jeg forklare hvordan JPA- og Hibernate-buffermekanismen på andre nivå fungerer og hvorfor de er veldig viktige når det gjelder å forbedre ytelsen til datatilgangslaget ditt.
JPA og Hibernate-enhet på første nivå og andre nivå cache
Som jeg forklarte i denne artikkelen, har JPA og Hibernate også en cache på første nivå. Imidlertid er cachen på første nivå bundet til tråden som kjører for øyeblikket, så de bufrede enhetene kan ikke deles av flere samtidige forespørsler.
På den annen side er bufferen på andre nivå designet for å brukes av flere samtidige forespørsler, og øker derfor sannsynligheten for å få et hurtigbuffertreff.
Når du henter en JPA-enhet:
Post post = entityManager.find(Post.class, 1L);
En dvalemodus LoadEntityEvent utløses, som håndteres av DefaultLoadEventListener slik:
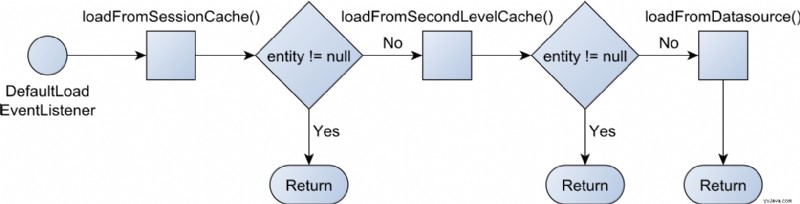
Først sjekker Hibernate om cachen på første nivå (a.k.a JPA EntityManager , dvalemodus Session , eller Persistence Context) inneholder allerede enheten, og hvis den gjør det, returneres den administrerte enheten.
Hvis JPA-enheten ikke blir funnet i cachen på første nivå, vil Hibernate sjekke cachen på andre nivå hvis den er aktivert.
Hvis enheten ikke kan hentes fra cachen på første eller andre nivå, vil Hibernate laste den fra databasen ved hjelp av en SQL-spørring. JDBC ResultSet fra enhetslastingsspørringen omdannes til en Java Object[] som er kjent som enheten lastet tilstand.
Den innlastede tilstandsmatrisen lagres i hurtigbufferen på første nivå sammen med den administrerte enheten for å hjelpe Hibernate skitnekontrollmekanismen med å oppdage om en enhet har blitt endret:
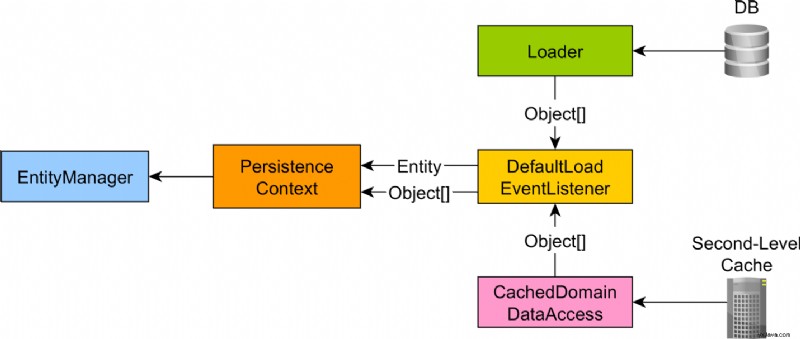
Imidlertid er den samme enheten lastet tilstand også det som lastes fra JPA og Hibernate andrenivåbuffer når databasen omgår.
JPA- og Hibernate-bufferen på andre nivå er hurtigbufferen til den enhetslastede tilstandsmatrisen, ikke til den faktiske enhetsobjektreferansen.
Hvorfor bruke JPA og Hibernate på andre nivå cache
Nå som du har sett hvordan cachen på andre nivå fungerer når du henter enheter, lurer du kanskje på hvorfor ikke hente enheten direkte fra databasen.
Skalering av skrivebeskyttede transaksjoner kan gjøres ganske enkelt ved å legge til flere replika-noder. Det fungerer imidlertid ikke for den primære noden siden den bare kan skaleres vertikalt.
Og det er her cachen på andre nivå kommer inn i bildet. For lese-skrive databasetransaksjoner som må utføres på primærnoden, kan cachen på andre nivå hjelpe deg med å redusere spørringsbelastningen ved å dirigere den til den sterkt konsistente cachen på andre nivå:
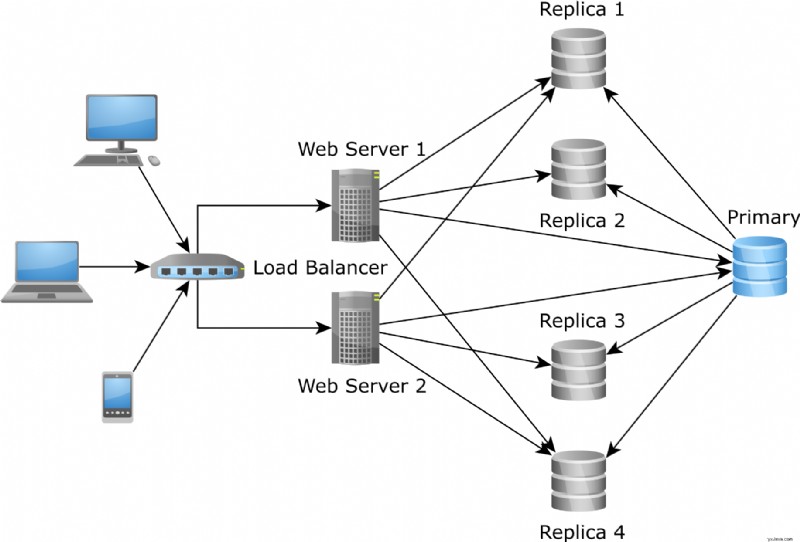
JPA- og Hibernate-bufferen på andre nivå kan hjelpe deg med å øke hastigheten på lese- og skrivetransaksjoner ved å avlaste lesetrafikken fra primærnoden og betjene den fra hurtigbufferen.
Skalering av JPA- og Hibernate-bufferen på andre nivå
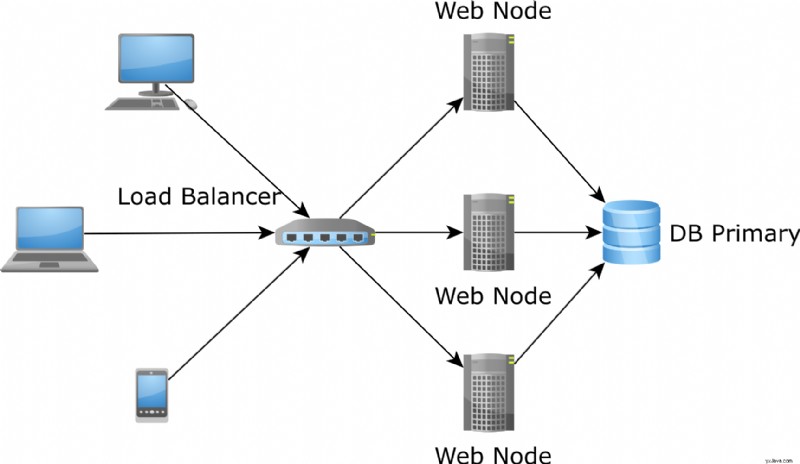
Tradisjonelt ble cachen på andre nivå lagret i applikasjonens minne, og det var problematisk av flere grunner.
For det første er applikasjonsminnet begrenset, så volumet av data som kan bufres er også begrenset.
For det andre, når trafikken øker og vi ønsker å starte nye applikasjonsnoder for å håndtere den ekstra trafikken, vil de nye nodene starte med en kald cache, noe som gjør problemet enda verre ettersom de får en økning i databasebelastningen til cachen er fylt med data:
For å løse dette problemet, er det bedre å ha hurtigbufferen som kjører som et distribuert system, som Redis. På denne måten begrenses ikke mengden av hurtigbufrede data av minnestørrelsen på en enkelt node, siden sharding kan brukes til å dele dataene mellom flere noder.
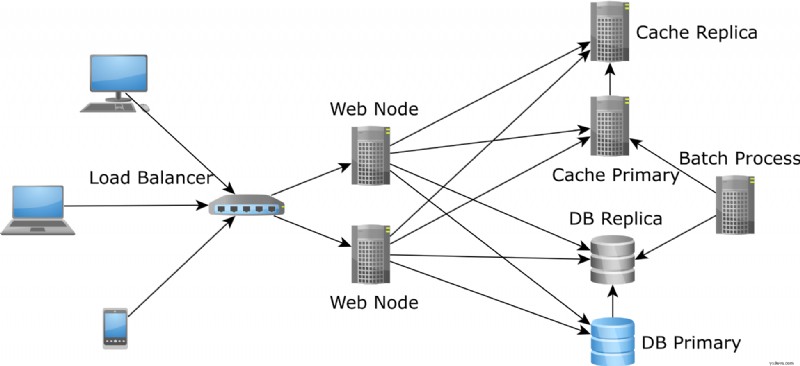
Og når en ny applikasjonsnode legges til av autoskaleren, vil den nye noden laste data fra den samme distribuerte hurtigbufferen. Derfor er det ikke noe problem med kaldt cache lenger.
JPA- og Hibernate-bufferalternativer på andre nivå
Det er flere ting som kan lagres av JPA- og Hibernate-cachen på andre nivå:
- entitet lastet tilstand
- identifikatorer for samlingsenhet
- søkeresultater for både enheter og DTO-projeksjoner
- den tilknyttede enhetsidentifikatoren for en gitt naturlig identifikator
Så cachen på andre nivå er ikke begrenset til kun å hente enheter.
Konklusjon
JPA- og Hibernate-cachen på andre nivå er veldig nyttig når man skal skalere rad-skrive-transaksjoner. Fordi cachen på andre nivå er designet for å være sterkt konsistent, trenger du ikke å bekymre deg for at foreldede data kommer til å bli servert fra cachen.
Dessuten trenger du ikke å bekymre deg for å holde styr på databasemodifikasjoner for å planlegge hurtigbufferoppdateringer heller fordi dette gjøres transparent av Hibernate for deg.