En introduktion till Apache Spark med Java
Vad är Apache Spark?
Apache Spark är en in-memory distribuerad databehandlingsmotor som används för bearbetning och analys av stora datamängder. Spark presenterar ett enkelt gränssnitt för användaren att utföra distribuerad beräkning på hela klustren.
Spark har inga egna filsystem, så det måste bero på lagringssystemen för databehandling. Den kan köras på HDFS eller molnbaserade filsystem som Amazon S3 och Azure BLOB.
Förutom molnbaserade filsystem kan den också köras med NoSQL-databaser som Cassandra och MongoDB.
Spark-jobb kan skrivas i Java, Scala, Python, R och SQL. Det tillhandahåller direkta bibliotek för maskininlärning, grafbearbetning, streaming och SQL-liknande databehandling. Vi kommer att gå in i detalj om vart och ett av dessa bibliotek senare i artikeln.
Motorn utvecklades vid University of California, Berkeleys AMPLab och donerades till Apache Software Foundation 2013.
Need for Spark
Det traditionella sättet att behandla data på Hadoop är att använda dess MapReduce-ramverk. MapReduce innebär mycket diskanvändning och som sådan är bearbetningen långsammare. När dataanalys blev mer mainstream kände skaparna ett behov av att påskynda bearbetningen genom att minska diskutnyttjandet under jobbkörningar.
Apache Spark åtgärdar det här problemet genom att utföra beräkningen i huvudminnet (RAM) för arbetarnoderna och lagrar inte beräkningsresultat i mitten på disken.
För det andra laddar den faktiskt inte data förrän den krävs för beräkning. Den konverterar den givna uppsättningen kommandon till en riktad acyklisk graf (DAG) och kör den sedan. Detta förhindrar behovet av att läsa data från disken och skriva tillbaka utdata från varje steg som är fallet med Hadoop MapReduce . Som ett resultat hävdar Spark att han behandlar data vid 100X snabbare än ett motsvarande jobb med MapReduce för beräkningsjobb i minnet.
Spark Architecture
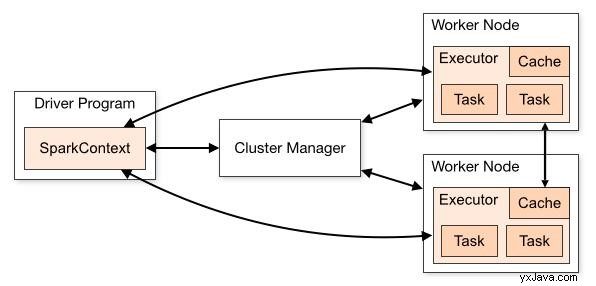
Kredit:https://spark.apache.org/
Spark Core använder en master-slave-arkitektur. Drivrutinsprogrammet körs i masternoden och distribuerar uppgifterna till en Executor som körs på olika slavnoder. Executor körs på sina egna separata JVM, som utför de uppgifter som tilldelats dem i flera trådar.
Varje Executor har också en cache kopplad till sig. Cache kan vara i minnet samt skrivas till disken på arbetarens nod . Executors kör uppgifterna och skicka tillbaka resultatet till drivrutinen .
Drivrutinen kommunicerar med noderna i kluster med hjälp av en Cluster Manager som den inbyggda klusterhanteraren, Mesos, YARN, etc. Batchprogrammen vi skriver exekveras i Driver Node.
Enkelt Spark Job med Java
Vi har diskuterat mycket om Spark och dess arkitektur, så nu ska vi ta en titt på ett enkelt Spark-jobb som räknar summan av mellanrumsseparerade tal från en given textfil:
32 23 45 67 2 5 7 9
12 45 68 73 83 24 1
12 27 51 34 22 14 31
...
Vi börjar med att importera beroenden för Spark Core som innehåller Spark-bearbetningsmotorn. Den har inga ytterligare krav eftersom den kan använda det lokala filsystemet för att läsa datafilen och skriva resultaten:
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.10</artifactId>
<version>2.2.3</version>
</dependency>
Med kärninställningen, låt oss fortsätta att skriva vår Spark-batch!
public class CalculateFileSum {
public static String SPACE_DELIMITER = " ";
public static void main(String[] args) {
SparkConf conf = new parkConf().setMaster("local[*]").setAppName("SparkFileSumApp");
JavaSparkContext sc = new JavaSparkContext(conf);
JavaRDD<String> input = sc.textFile("numbers.txt");
JavaRDD<String> numberStrings = input.flatMap(s -> Arrays.asList(s.split(SPACE_DELIMITER)).iterator());
JavaRDD<String> validNumberString = numberStrings.filter(string -> !string.isEmpty());
JavaRDD<Integer> numbers = validNumberString.map(numberString -> Integer.valueOf(numberString));
int finalSum = numbers.reduce((x,y) -> x+y);
System.out.println("Final sum is: " + finalSum);
sc.close();
}
}
Att köra den här kodbiten bör ge:
Final sum is: 687
JavaSparkContext objekt vi har skapat fungerar som en koppling till klustret. Spark Context vi har skapat här har tilldelats alla tillgängliga lokala processorer, därav * .
Den mest grundläggande abstraktionen i Spark är RDD , som står för Resilient Distributed Dataset . Den är motståndskraftig och distribuerad eftersom data replikeras över klustret och kan återställas om någon av noderna kraschar.
En annan fördel med att distribuera data är att den kan behandlas parallellt, vilket främjar horisontell skalning. En annan viktig egenskap hos RDD:er är att de är oföränderliga. Om vi tillämpar någon åtgärd eller transformation på en given RDD, blir resultatet en annan uppsättning RDD:er.
I det här exemplet har vi läst orden från inmatningsfilen som RDD s och omvandlade dem till siffror. Sedan har vi tillämpat reduce funktion på dem för att summera värdena för var och en av RDD:erna innan de visas på konsolen.
Introduktion till Spark Libraries
Spark ger oss ett antal inbyggda bibliotek som körs ovanpå Spark Core.
Spark SQL
Spark SQL tillhandahåller ett SQL-liknande gränssnitt för att utföra bearbetning av strukturerad data. När användaren kör en SQL-fråga, startas ett batch-jobb internt av Spark SQL som manipulerar RDD:erna enligt frågan.
Fördelen med detta API är att de som är bekanta med RDBMS-stil sökningar finner det enkelt att gå över till Spark och skriva jobb i Spark.
Spark Streaming
Spark Streaming är lämplig för applikationer som hanterar data som flödar i realtid, som att bearbeta Twitter-flöden.
Spark kan integreras med Apache Kafka och andra strömningsverktyg för att tillhandahålla feltoleranta och högkapacitetsbehandlingsmöjligheter för strömmande data.
Spark MLlib
MLlib är en förkortning för Machine Learning Library som Spark tillhandahåller. Det inkluderar de vanliga inlärningsalgoritmerna som klassificering, rekommendationer, modellering etc. som används i maskininlärning.
Dessa algoritmer kan användas för att träna modellen enligt underliggande data. På grund av den extremt snabba databearbetningen som stöds av Spark, kan maskininlärningsmodellerna tränas på relativt kortare tid.
GraphX
Som namnet indikerar är GraphX Spark API för att bearbeta grafer och utföra grafparallella beräkningar.
Användaren kan skapa grafer och utföra operationer som att sammanfoga och transformera graferna. Precis som med MLlib kommer Graphx med inbyggda grafalgoritmer för sidrankning, triangelantal och mer.
Slutsats
Apache Spark är den bästa plattformen tack vare sin blixtsnabba databearbetningshastighet, enkla att använda och feltoleranta funktioner.
I den här artikeln tog vi en titt på arkitekturen hos Spark och vad som är hemligheten bakom dess blixtsnabba bearbetningshastighet med hjälp av ett exempel. Vi tog också en titt på de populära Spark Libraries och deras funktioner.