Elastisk infrastruktur i praktiken
För ett par veckor sedan fick jag ett sällsynt tillfälle att smutsa ner händerna på infrastrukturområdet. Eftersom jag var en intressant förändring av mina dagliga timmar djupt under huven på JVM-interna, tänkte jag dela motivationen och resultaten med dig. Förhoppningsvis tjänar det som inspiration till liknande problemkategorier där ute.
Bakgrund
Jag börjar med att förklara i vilket sammanhang lösningen behövdes. Om du vet vad Plumbr prestandaövervakning handlar om kan du hoppa över den här delen. För alla andra bygger vi på Plumbr en lösning för prestandaövervakning. Vårt tillvägagångssätt är unikt, eftersom vi strävar efter att utrusta alla prestandaproblem med grundorsaken i källkoden.
En av de mer komplexa kategorierna av sådana problem har sina rötter gömda i Java-minnestilldelning och -hantering. Problemen i denna kategori inkluderar:
- minnet tar slut;
- för ofta/för långa GC-pauser;
- försöker minska programmets minnesavtryck.
Vår lösning på problem som detta bygger på att ta en ögonblicksbild av objektgrafen och exponera de mest minneskrävande datastrukturerna därifrån. Som ett resultat kommer du att få insyn i körtiden i vad som faktiskt händer i JVM:s hög:
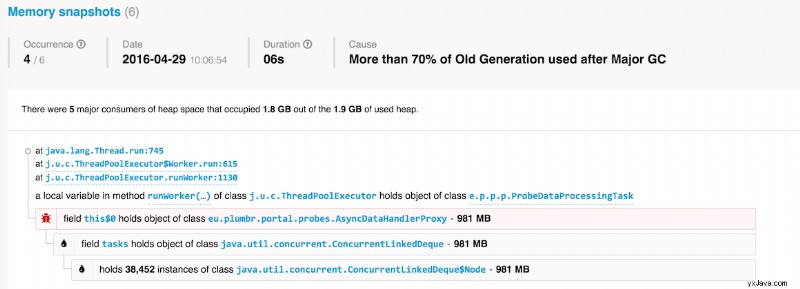
Ovanstående är ett exempel på vad vi upptäckte när vi övervakade våra egna tjänster. Som vi kan se hade vi någon gång efter en major GC-paus mer än 70 % av den gamla generationen ockuperade. Hög beläggning av den gamla generationen orsakar vanligtvis långa GC-pauser, så Plumbr tog en ögonblicksbild för att visa vad som faktiskt finns där.
I det här specifika fallet fick vi reda på att vår bearbetningskö som innehåller ProbeDataProcessingTasks har vuxit till nästan en gigabyte i storlek. Att förstå vilka datastrukturer som var skyldiga gjorde det trivialt att lösa problemet. Som ett resultat hölls frekvensen och varaktigheten av GC-pauser i schack.
Att ta dessa ögonblicksbilder är dock något dyrt. Tiden det tar att fånga ögonblicksbilden beror på antalet objekt i högen och referenser mellan dem. Våra agenter timar ögonblicksbilderna noggrant för att undvika att själva bli en prestationsflaskhals.
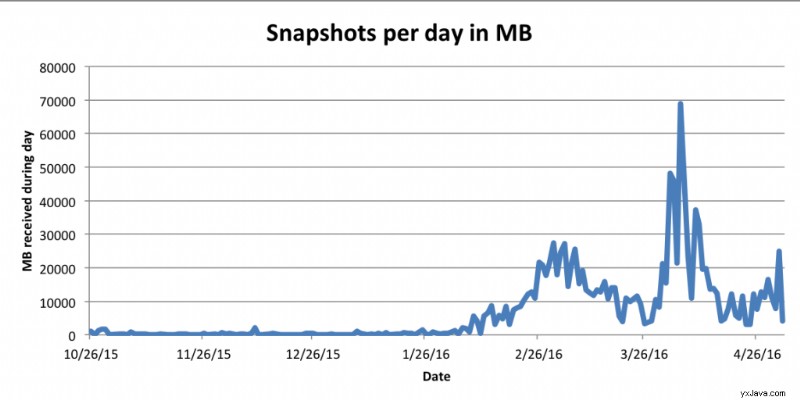
För att sammanfatta det:i samband med vår infrastruktur resulterar denna speciella funktion i ett oförutsägbart inflöde av minnesbilder. För att göra saken värre är storleken på ögonblicksbilderna också allt annat än förutsägbara. Ibland kan vi få bara en liten ögonblicksbild per timme och plötsligt blir vi bombarderade med många av 10+G ögonblicksbilder under mycket korta tidsperioder:
Problem med vår första lösning
Den första lösningen vi byggde var en dedikerad mikrotjänst som hanterade det inkommande flödet av ögonblicksbilder. Vi började möta problem direkt. Först var vi långt borta med att uppskatta storleken på dessa ögonblicksbilder. 4G-minnet som ursprungligen tillhandahålls var långt ifrån tillräckligt för att hantera de större ögonblicksbilderna som flödade mot oss. För att analysera en ögonblicksbild måste vi ladda objektgrafen i minnet, så ju större ögonblicksbilden är, desto mer RAM krävs för analys.
Så vi behövde skaffa en större maskin från Amazon. Helt plötsligt var inte mikrotjänsten så mikro längre. Håller m4.10xlarge exempel brummande 24×7 är faktiskt synligt i din månatliga faktura, som vi snart upptäckte. Förutom att den var väldigt dyr, stod maskinen nästan på tomgång i 99 % av tiden – de enorma ögonblicksbilderna av högen inträffade sällan nog, så oftare än inte var maskinen mer än 10 gånger överprovisionerad för att klara enstaka toppar.
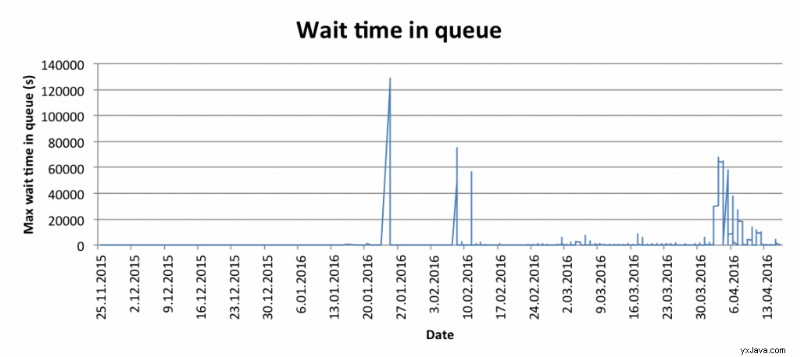
Dessutom blev analystiden snabbt en flaskhals i sig. Ögonblicksbilderna tog allt från 10 sekunder till tiotals minuter att analysera var och en, så när flera stora ögonblicksbilder kom under en kort tidsperiod blev köväntetiden ett problem:
Krav för lösningen
Efter att ha förstått problemen var nästa steg att reducera problemen till krav på en lösning:
- Analyseuppgifterna ska inte stå i kön i timmar. Vi borde kunna bearbeta dem parallellt. Närhelst en stor ögonblicksbild kommer och tar lång tid att analysera, bör de andra inte vänta på att den ska slutföras.
- För varje ögonblicksbild kan vi uppskatta hur mycket hög det skulle ta för att utföra analysen. Vi skulle vilja använda ungefär lika mycket, utan att överprovisionera infrastrukturen.
För den som har byggt elastiska miljöer tidigare kan kraven på lösningen framstå som självklara. För de som inte har det kommer jag att täcka lösningsarkitekturen och implementeringshörnfallen i nästa avsnitt.
Bygga lösningen
Kraven dikterade oss faktiskt att vi istället för en enda dedikerad instans skulle upprätthålla en elastisk infrastruktur. Instanserna ska skapas på begäran och instanstypen ska motsvara storleken på den mottagna ögonblicksbilden.
Så vi fortsatte med att slå in vår ögonblicksbildanalyskod i dockercontainrar och använde AWS ECS för att använda sådana containrar som uppgifter i ett kluster. Efter att ha gjort just det, snubblade vi över det första problemet:att skala ut var inte en så trivial uppgift som förväntat.
Det naiva tillvägagångssättet att bara skapa en ny instans av lämplig storlek för varje analys och omedelbart avsluta den efteråt visade sig vara en dålig idé. Att starta en instans kan ta upp till fem minuter, beroende på instanstyp. Dessutom utför AWS fakturering på timbasis, så att hålla en instans igång i 60 minuter är tio gånger billigare än att köra tio instanser i sex minuter vardera.
Det typiska tillvägagångssättet i sådana fall är att använda AWS-autoskalningsgrupper. Tydligen passade detta inte oss eftersom AWS inte automatiskt kan skapa instanser baserat på hur mycket minne en ECS-uppgift behöver. Du kan inte skicka en uppgift till ett ECS-kluster om inte klustret redan har tillräckligt med resurser för att ta emot det.
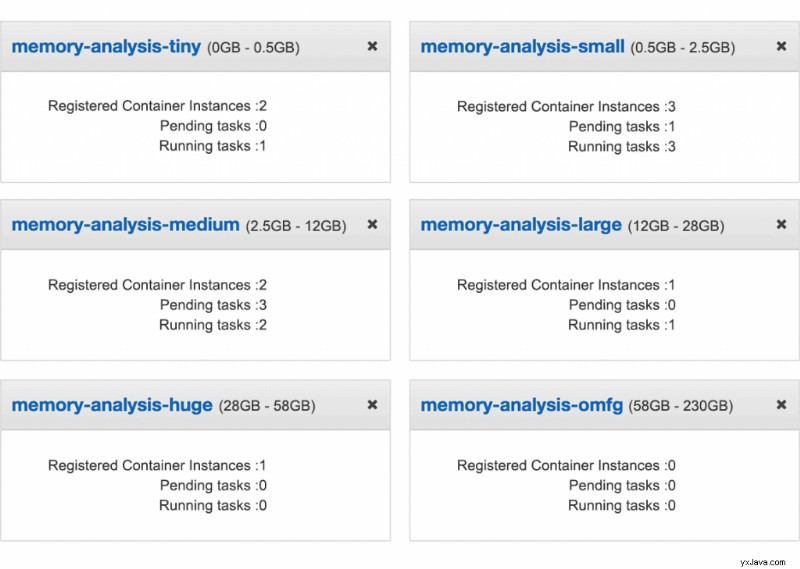
Vår lösning var att dela upp analysuppgifterna i hinkar baserat på hur mycket minne de kräver, och ha ett separat kluster för varje hink. När vi får en ny ögonblicksbild kontrollerar vi om målklustret har tillräckligt med lediga resurser för att köra uppgiften. Om inte, ökar vi det önskade antalet instanser i dess automatiska skalningsgrupp. AWS tar då automatiskt upp en ny instans av lämplig storlek. Så i huvudsak slutade vi med sex hinkar, som var och en innehåller instanserna av lämplig storlek som ska skalas ut baserat på efterfrågan:
Det andra problemet uppstod med att skala in igen. Standard CloudWatch-larmen för inskalning baseras på hur underutnyttjat ett kluster är. Om ett kluster har stått stilla tillräckligt länge, minskar vi antalet önskade instanser. "Idleness" beräknas baserat på det förbrukade minnet i klustret, och om minnesanvändningen under 45 minuter har legat under den angivna tröskeln, startar skala in och avslutar de extra instanserna.
Det fanns en varning här också:när man skalar i en automatisk skalningsgrupp väljer AWS den instans som ska avslutas på ett märkligt sätt. Till exempel, om ett kluster har två instanser och en av dem är inaktiv, och den andra kör analys, är det fullt möjligt att den aktiva instansen skulle dödas istället för den inaktiva.
Lösningen på inskalningsproblemet var att vi under analysens varaktighet satte in skalningsskydd för den specifika instans som utför den. När vi börjar analysera sätter vi flaggan och tar bort den när den är klar. Automatisk skalning kommer inte att avsluta instanser som är skyddade från inskalning. Den sista biten räckte och vi började löpa smidigt hela tiden.
Att ha hittat lösningar på båda problemen gav oss det förväntade resultatet. Tiden som väntade i kön efter ändringen ser nu ut så här:
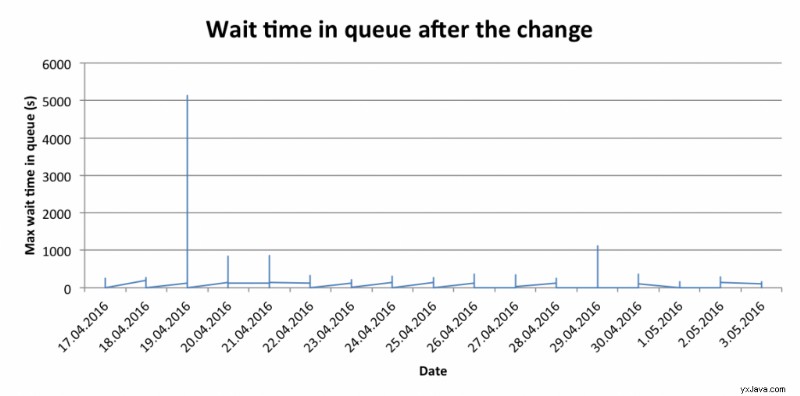
Take-away
Detta är ett av de sällsynta fallen där du kan förbättra prestandan för en applikation, och även minska kapacitetskraven och minska kostnaderna. För det mesta måste du betala en rejäl slant för prestandaförbättringar, så man kan uppskatta sådana ögonblick. On-demand computing är nu enklare än någonsin, så kanske du kan optimera din applikation på ett liknande sätt.
Och om inlägget förutom att vara ett intressant fall för elastisk infrastruktur väckte ett intresse för hur du kan få insyn i din egen applikationsminneanvändning, fortsätt och ta den kostnadsfria Plumbr-testversionen för att kolla upp det.


