Big Data Hadoop Tutorial för nybörjare
Denna handledning är för nybörjare som vill börja lära sig om Big Data och Apache Hadoop Ecosystem. Denna handledning ger en introduktion av olika koncept av Big Data och Apache Hadoop som kommer att lägga grunden för vidare lärande.
Innehållsförteckning
- 1. Inledning
- 2. Big Data?
- 2.1 Exempel på Big Data.
- 3. Egenskaper för Big Data
- 3.1 Volym
- 3.2 Variation
- 3.3 Hastighet
- 4. Typer av Big Data
- 4.1 Strukturerad data
- 4.2 Halvstrukturerade data
- 4.3 Ostrukturerade data
- 5. Apache Hadoop
- 6. Hadoop Distributed File System (HDFS)
- 7. HDFS fungerar
- 7.1 Läsoperation
- 7.2 Skrivoperation
- 8. MapReduce
- 8.1 Hur MapReduce fungerar
- 8.2 Exekveringsprocess
- 9. Ytterligare läsningar
- 10. Slutsats
1. Inledning
I den här handledningen ska vi titta på grunderna för big data, vad exakt big data är. Hur man bearbetar den mängden data och var Apache Hadoop passar i behandlingen av big data. Den här artikeln är för nybörjare och kommer att behandla alla grunder som behövs för att förstå för att dyka in i Big Data och Hadoop Ecosystem.
2. Big Data?
Data definieras som kvantiteter, tecken eller symboler på vilka datorer eller andra beräkningssystem utför operationer och som kan lagras och överföras i form av elektronisk form.
Så baserat på det är "Big Data" också liknande data men i termer av storlek är den ganska större och växer exponentiellt med tiden. Nu är stor inte en kvantitativ term och olika personer kan ha olika definitioner av hur mycket som är stort. Men det finns en acceptabel definition av big i betydelsen big data. Data som är så stor och komplex att den inte kan bearbetas eller lagras effektivt av de traditionella datahanteringsverktygen kallas "Big Data".
2.1 Exempel på Big Data
Några av exemplen på big data är:
- Sociala medier: Sociala medier är en av de största bidragsgivarna till den flod av data vi har idag. Facebook genererar cirka 500+ terabyte data varje dag i form av innehåll som genereras av användarna som statusmeddelanden, foton och videouppladdningar, meddelanden, kommentarer etc.
- Börs: Data som genereras av börser är också i terabyte per dag. De flesta av dessa data är handelsdata för användare och företag.
- Flygindustrin: En enda jetmotor kan generera cirka 10 terabyte data under en 30 minuters flygning.
3. Egenskaper för Big Data
Big Data har i princip tre egenskaper:
- Volym
- Mångfald
- Hastighet
3.1 Volym
Storleken på data spelar en mycket viktig roll för att få ut värdet av data. Big Data innebär att enorma mängder data är inblandade. Sociala mediasajter, börsindustrin och andra maskiner (sensorer etc) genererar en enorm mängd data som ska analyseras för att förstå data. Detta gör enorma datavolymer till en av de grundläggande egenskaperna hos big data.
3.2 Variation
Variation, som namnet antyder, indikerar data av olika slag och från olika källor. Den kan innehålla både strukturerad och ostrukturerad data. Med en kontinuerlig ökning av användningen av teknik har vi nu flera källor varifrån data kommer som e-post, videor, dokument, kalkylblad, databashanteringssystem, webbplatser etc. Variation i strukturen för data från olika källor gör det svårt att lagra denna data men desto mer komplex uppgift är det att bryta, bearbeta och omvandla dessa olika strukturer för att få en mening ur det. Mångfalden av data är kännetecknet för big data som är ännu viktigare än volymen av data.
3.3 Hastighet
Big Data Velocity handlar om i vilken takt och brant data strömmar in i det mottagande systemet från olika datakällor som affärsprocesser, sensorer, sociala nätverk, mobila enheter etc. Dataflödet är enormt och kontinuerligt många gånger i realtid eller nästan verkligt tid. Big data-ramverk måste kunna hantera den kontinuerliga strömmen av data vilket gör att en Velocity också är en av de viktigaste egenskaperna hos Big Data. 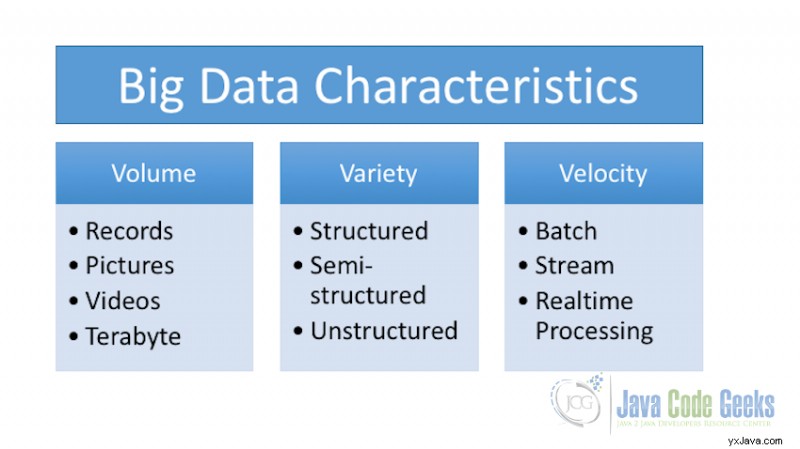
3 egenskaper hos Big Data
4. Typer av Big Data
Big Data är generellt indelad i tre kategorier:
- Strukturerade data
- Halvstrukturerad data
- Ostrukturerad data
4.1 Strukturerad data
All data som kan lagras i form av ett visst fast format kallas strukturerad data. Till exempel är data som lagras i kolumner och tabellrader i en relationsdatabashanteringssystem en form av strukturerad data.
4.2 Halvstrukturerade data
Semistrukturerad data som namnet antyder kan ha data som är strukturerad och samma datakälla kan ha data som är ostrukturerad. Data från olika typer av formulär som lagrar data i XML- eller JSON-format kan kategoriseras som semistrukturerad data. Med den här typen av data vet vi vad som är formen av data på ett sätt som vi förstår vad denna del av data representerar och vad en annan speciell uppsättning data representerar, men denna data kan eller kanske inte konverteras och lagras som tabellschema.
4.3 Ostrukturerad data
Alla data som inte har något fast format eller som formatet inte kan vara känt i förväg kategoriseras som ostrukturerad data. När det gäller ostrukturerad data är storleken inte det enda problemet, att härleda värde eller få resultat ur ostrukturerad data är mycket mer komplext och utmanande jämfört med strukturerad data. Exempel på ostrukturerad data är en samling dokument som finns i ett företags eller en organisations lagring som har olika strukturer, innehåller videor, bilder, ljud etc. Nästan alla organisationer stora som små har ett stort antal sådan data liggande men de har ingen aning om hur man härleder värde ur denna data. 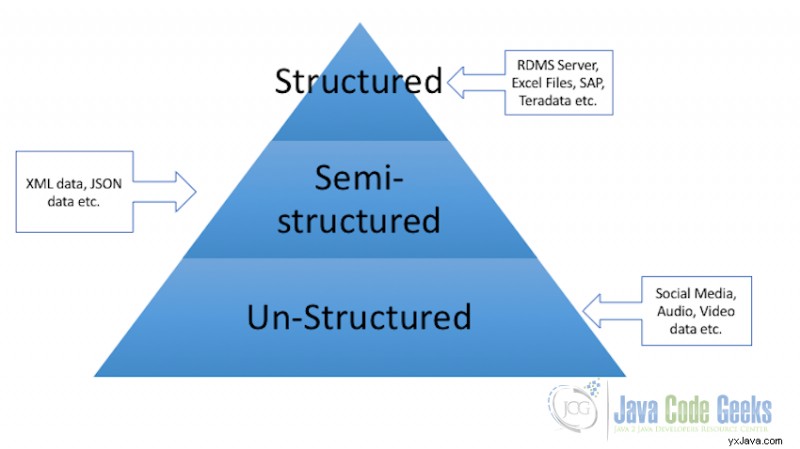
Typer av Big Data
5. Apache Hadoop
Med all denna mängd och alla typer av data tillgängliga, måste vi bearbeta dem alla för att göra det vettigt ur det. Företag måste förstå data så att vi kan fatta bättre beslut. Det finns inget enkelt kommersiellt system som är lättillgängligt som kan behandla denna mängd data. För att utnyttja kraften i big data behöver vi en infrastruktur som kan hantera och bearbeta enorma volymer av strukturerad och ostrukturerad data och allt detta bör vara inom de acceptabla tidsgränserna. Det är här Apache Hadoop kommer in i bilden.
Apache Hadoop är ett ramverk som använder MapRedue programmeringsparadigm och används för att utveckla databehandlingsapplikationer som kan köras parallellt, i en distribuerad datoruppsättning ovanpå ett kluster av kommersiella system.
Apache Hadoop består av två huvuddelprojekt som utgör basen för Hadoop ekosystem:
- Hadoop Distributed File System (HDFS) :Hadoop Distributed File system som namnet indikerar är ett filsystem som är distribuerat till sin natur. Den tar hand om lagringsdelen av Hadoop-applikationerna och gör det möjligt att lagra data på ett distribuerat sätt på de olika systemen i klustret. HDFS skapar också flera repliker av datablock och distribuerar dem på de olika noderna i klustret. Distribution och replikering av data möjliggör snabb beräkning och extrem tillförlitlighet vid fel. HDFS är en öppen källkodsimplementering av Google File System som Google först publicerade en artikel om 2003 med namnet The Google File System
- Hadoop MapReduce :Som vi diskuterade ovan är MapReduce programmeringsparadigmet och beräkningsmodellen för att skriva Hadoop-applikationer som körs på Hadoop-kluster. Där har MapReduce-applikationer parallellt körande jobb som kan bearbeta enorma data parallellt i stora kluster. Hadoop MapReduce är en öppen källkodsimplementering av Google MapReduce. Google skrev en artikel om sitt MapReduce-paradigm 2004 MapReduce:Simplified Data Processing on Large Clusters som blev basen för MapReduce och databehandling i klusterdatoreran.
6. Hadoop Distributed File System (HDFS)
HDFS är designat för att lagra mycket stora datafiler som bearbetas av MapReduce, som körs på kluster av råvaruhårdvara. HDFS är feltolerant eftersom den replikerar data flera gånger i klustret och är även skalbar vilket innebär att den enkelt kan skalas utifrån kravet.
HDFS-kluster består av två typer av noder:
- DataNode :Datanoder är slavnoderna som finns på varje maskin i klustret och ansvarar för att tillhandahålla den faktiska lagringen av data. DataNode är den som ansvarar för att läsa och skriva filer till lagringen. Läs-/skrivoperationer görs på blocknivå. Standard blockstorlek i HDFS är inställd på 64 MB. Filer delas upp i bitar enligt blockstorlekarna och lagras i DataNode. När data väl har lagrats i block, replikeras dessa block också för att ge feltoleransen i händelse av hårdvarufel.
- NameNode :NameNode är komponenten i HDFS som underhåller metadata för alla filer och kataloger lagrade i HDFS. NameNode upprätthåller detaljer om alla DataNodes som innehåller block för en viss fil.
7. HDFS fungerar
I det här avsnittet kommer vi att gå igenom hur Hadoop Distributed File System fungerar. Vi kommer att titta på läs- och skrivoperationen i HDFS.
7.1 Läs Operation
Nedanstående diagram förklarar läsfunktionen för HDFS: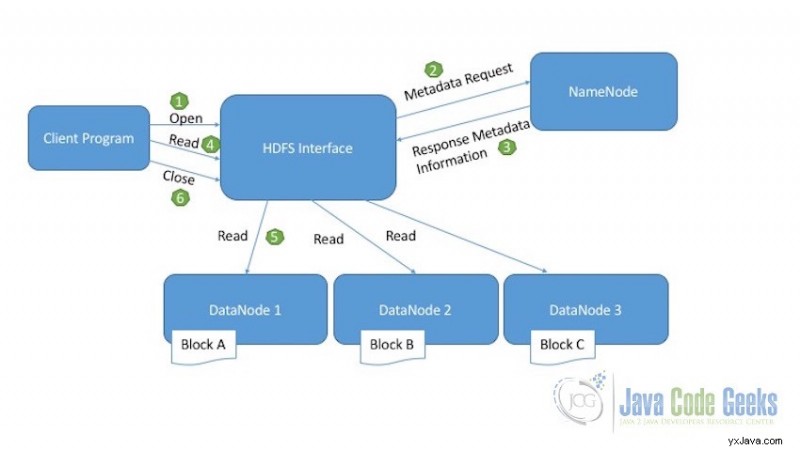
Läs Operation i HDFS
- Klientprogram som behöver läsa filen från HDFS initierar läsbegäran genom att anropa den öppna metoden.
- HDFS-gränssnittet tar emot läsbegäran och ansluter till NameNode för att hämta metadatainformationen för filen. Denna metadatainformation inkluderar plats för filblocken.
- NameNode skickar tillbaka svaret med all nödvändig metadatainformation som krävs för att komma åt datablocken i DataNodes.
- När klienten tar emot platsen för filblocken, initierar klienten läsbegäran för DataNodes som tillhandahålls av NameNode.
- HDFS-gränssnittet utför nu själva läsaktiviteten. Den ansluter till den första DataNode som innehåller det första datablocket. Datan returneras från DataNode som en ström. Detta fortsätter tills det sista blocket av data läses.
- När läsningen av det sista datablocket är klar skickar klienten stängningsförfrågan för att indikera att läsoperationen är klar.
7.2 Skrivoperation
Nedanstående diagram förklarar skrivoperationen för HDFS: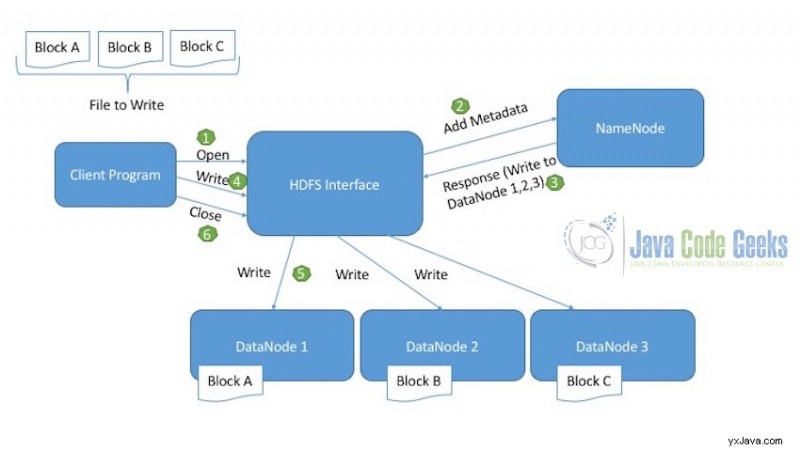
Skriv operation i HDFS
Låt oss anta att filen vi vill skriva till HDFS är uppdelad i tre block:Block A, Block B, Block C.
- Klienten initierar först och främst läsoperationen som indikeras av det öppna samtalet.
- HDFS-gränssnitt vid mottagande av den nya skrivbegäran, ansluter till NameNode och initierar en ny filskapande. NameNode ser vid detta tillfälle till att filen inte redan finns och att klientprogrammet har rätt behörighet att skapa denna fil. Om filen redan finns i HDFS eller om klientprogrammet inte har de nödvändiga behörigheterna för att skriva filen, visas ett IOException kastas.
- När NameNode lyckats skapa den nya posten för filen som ska skrivas i DataNodes, berättar den för klienten var den ska skriva vilket block. Skriv till exempel Block A i DataNode 1, Block B i DataNode 2 och Block C i DataNode 3.
- Klienten som sedan har tillräcklig information om var filblocken ska skrivas anropar skrivmetoden.
- HDFS-gränssnitt vid mottagande av skrivanropet, skriver blocken i motsvarande DataNodes.
- När skrivningen av alla block i motsvarande DataNodes är klar, skickar klienten stängningsförfrågan för att indikera att skrivoperationen har slutförts framgångsrikt.
Obs! För ytterligare läsning och förståelse av HDFS rekommenderar jag att du läser Apache Hadoop Distributed File System Explained
8. MapReduce
Som vi redan diskuterat och introducerat är MapReduce ett programmeringsparadigm/ramverk som är utvecklat för det enda syftet att möjliggöra bearbetning av "big data". Dessa MapReduce-jobb körs ovanpå Hadoop Cluster. MapReduce är skrivet i Java och det är det primära språket för Hadoop men Hadoop stöder även MapReduce-program skrivna på andra språk som Python, Ruby, C++ etc.
Som framgår av namnet består MapReduce-program av minst två faser:
- Kartfas
- Reducera fas
8.1 Hur MapReduce fungerar
MapReduce-programmen består av olika faser och varje fas tar nyckel-värde par som ingångar. Följande är arbetsflödet för ett enkelt MapReduce-program:
- Den första fasen av programmet är kartfasen. Varje kartfas kräver en bit indata att bearbeta. Denna bit kallas input split . Fullständig inmatning är uppdelad i ingångsdelningar och en kartuppgift bearbetar en ingångsdelning.
- Kartfasen bearbetar den del av data som den tar emot. Till exempel, i fallet med ett arbetsräkningsexempel, läser kartfasen data, delas upp i ord och skickar nyckel-värdeparet med ord som nyckel och 1 som värde till utdataströmmen.
- Nu är denna utdata från de flera kartuppgifterna i slumpmässig form. Så efter kartuppgiften, blandas bort dessa data för att ordna data så att liknande nyckel-värdepar går till en enda reducering.
- Reducerfas för MapReduce, indatavärdena är aggregerade. Den kombinerar värden från inmatningen och returnerar ett enda resulterande värde. Till exempel, i ordräkningsprogrammet kommer reduceringsfasen att få nyckelvärdespar med ord och värde som ett. Om en reducerare tar emot låt oss säga tre nyckel-värdepar för ordet "Data", kommer den att kombinera alla tre och utdata blir
- Efter att reduceringsfasen har avslutat databearbetningen avslutas MapReduce-programmet.
8.2 Exekveringsprocess
Exekveringsprocesserna för Map and Reduce-uppgifter styrs av två typer av enheter:
- Jobbspårare :Jobbspårare är huvudkomponenten som är ansvarig för det fullständiga utförandet av det övergripande MapReduce-jobbet. För ett inskickat jobb kommer det alltid att finnas en one jobtracker som körs på Namenode.
- Tasktrackers :Tasktrackers är slavkomponenterna de ansvarar för utförandet av de enskilda jobben på Datanoderna.
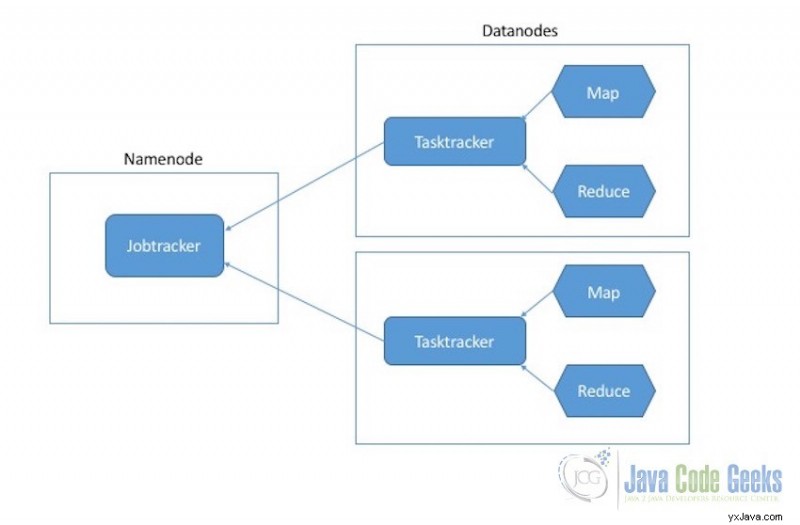
MapReduce exekveringskomponenter
9. Ytterligare läsningar
Den här artikeln täcker grunderna i Apache Hadoop för nybörjare. Efter detta skulle jag vilja rekommendera några andra artiklar för att gräva lite djupare i resan att lära sig Apache Hadoop och MapReduce. Här följer några fler artiklar för vidare läsning:
Hadoop distribuerade filsystem
- Apache Hadoop distribuerade filsystem förklaras
- Exempel på Apache Hadoop FS-kommandon
MapReduce
- Exempel på Apache Hadoop WordCount
- Hadoop-strömningsexempel
- Exempel på Hadoop MapReduce Combiner
Hadoop Cluster Administration
- Hur man installerar Apache Hadoop på Ubuntu
- Exempel på installation av Apache Hadoop-kluster (med virtuell maskin)
- Apache Hadoop Administration Handledning
10. Slutsats
I den här nybörjarartikeln tittade vi på exakt vad Big Data är, olika typer av big data och vi diskuterade också olika egenskaper hos big data. Sedan lärde vi oss om Apache Hadoop Ecosystem.
Två huvuddelprojekt (komponenter) av Apache Hadoop diskuterades, dvs Hadoop Distributed File System och MapReduce-ramverket och hur de fungerar i Hadoop ovanpå multi-nodklustret.
Artikeln avslutas med länkar till några viktiga artiklar för vidare läsning som kommer att täcka de viktigaste ämnena för Apache Hadoop-inlärning när dessa grunder är klara. Apache Hadoop Big Data Hadoop Map-Reduce tutorial Handledning för nybörjare