Datastruktur i Java – En komplett guide för linjära och icke-linjära datastrukturer
Att sortera genom det oändliga utbudet av mobiltelefoner baserat på pris eller söka efter en viss bok från miljontals böcker på Flipkart görs allt med mindre komplexa och billiga algoritmer som fungerar på strukturerad data.
Eftersom datastruktur är en kärna i alla programmeringsspråk och att välja en viss datastruktur påverkar i hög grad både prestanda och funktionalitet hos Java-applikationer, därför är det värt ett försök att lära sig olika datastrukturer som är tillgängliga i Java.
Idag kommer denna artikel att guida dig till varje typ av datastrukturer som stöds av Java med exempel och syntax, tillsammans med deras implementering och användning i Java.
Låt oss först bekanta oss med de 12 bästa Java-applikationerna med Techvidvan.
Håll dig uppdaterad med de senaste tekniktrenderna, Gå med i TechVidvan på Telegram
Vad är en datastruktur i Java?
Termen datastruktur avser en datainsamling med väldefinierade operationer och beteenden eller egenskaper. En datastruktur är ett unikt sätt att lagra eller organisera data i datorns minne så att vi kan använda dem effektivt.
Vi använder datastrukturer främst inom nästan alla områden inom datavetenskap, vilket är datorgrafik, operativsystem, artificiell intelligens, kompilatordesign och många fler.
Behovet av datastrukturer i Java
Eftersom mängden data växer snabbt blir applikationerna mer komplexa och följande problem kan uppstå:
- Bearbetningshastighet: Eftersom data ökar dag för dag krävs höghastighetsbehandling för att hantera denna enorma mängd data, men processorn kan misslyckas med att hantera så mycket data.
- Söka efter data: Tänk på en inventering med en storlek på 200 artiklar. Om din applikation behöver söka efter ett visst objekt, måste det gå igenom 200 objekt i varje sökning. Detta resulterar i att sökprocessen saktar ner.
- Flera förfrågningar samtidigt: Anta att miljontals användare samtidigt söker efter data på en webbserver, då finns det en risk för serverfel.
För att lösa ovanstående problem använder vi datastrukturer. Datastrukturen lagrar och hanterar data på ett sådant sätt att den nödvändiga informationen kan sökas direkt.
Fördelar med Java-datastrukturer
- Effektivitet: Datastrukturer används för att öka effektiviteten och prestandan för en applikation genom att organisera data på ett sådant sätt att de kräver mindre utrymme med högre bearbetningshastighet.
- Återanvändbarhet: Datastrukturer ger återanvändbarhet av data, det vill säga efter att ha implementerat en viss datastruktur en gång kan vi använda den många gånger var som helst. Vi kan sammanställa implementeringen av dessa datastrukturer i bibliotek och klienterna kan använda dessa bibliotek på många sätt.
- Abstraktion: I Java används ADT (Abstract Data Types) för att specificera en datastruktur. ADT ger en abstraktionsnivå. Klientprogrammet använder endast datastrukturen med hjälp av gränssnittet, utan att ha kunskap om implementeringsdetaljerna.
Datastrukturklassificering i Java
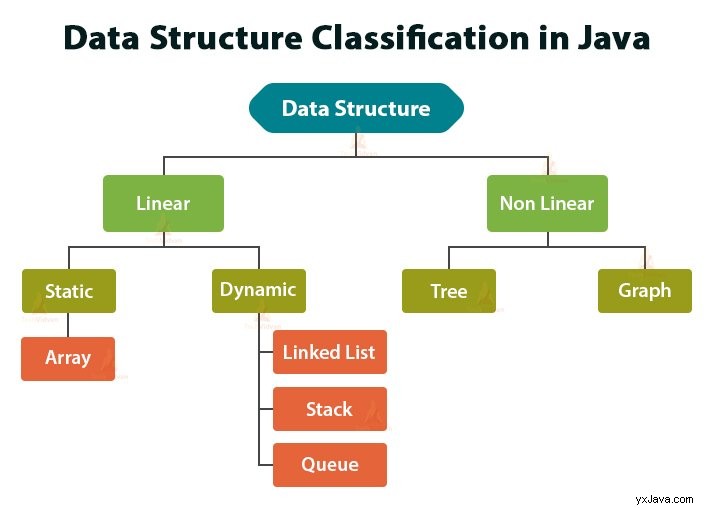
- Linjära datastrukturer: I en linjär datastruktur är alla element ordnade i linjär eller sekventiell ordning. Den linjära datastrukturen är en datastruktur på en nivå.
- Icke-linjära datastrukturer: Den icke-linjära datastrukturen arrangerar inte data på ett sekventiellt sätt som i linjära datastrukturer. Icke-linjära datastrukturer är flernivådatastrukturen.
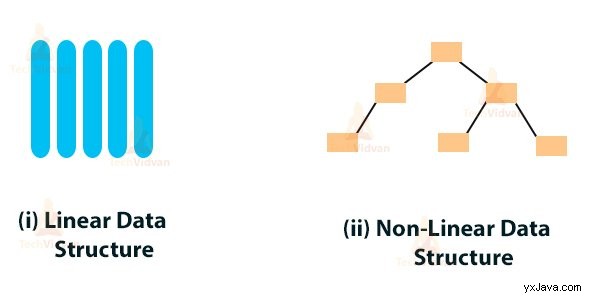
Typer av datastruktur i Java
Det finns några vanliga typer av datastrukturer i Java, de är följande –
- Arrayer
- Länkade listor
- Stack
- Kö
- Diagram
- Ställ in
1. Arrayer
En Array, som är den enklaste datastrukturen, är en samling element av samma typ som refereras till med ett gemensamt namn. Arrayer består av sammanhängande minnesplatser. Den första adressen i arrayen tillhör det första elementet och den sista adressen till arrayens sista element.
Några punkter om matriser:
- Arrayer kan ha dataobjekt av enkla och liknande typer som int eller float, eller till och med användardefinierade datatyper som strukturer och objekt.
- Den vanliga datatypen för matriselement är känd som bastypen för matrisen.
- Arrayer betraktas som objekt i Java.
- Indexeringen av variabeln i en array börjar från 0.
- Vi måste definiera en array innan vi kan använda den för att lagra information.
- Lagringen av arrayer i Java är i form av dynamisk allokering i heapområdet.
- Vi kan hitta längden på arrayer med hjälp av medlemmen 'längd'.
- Storleken på en array måste vara ett int-värde.
Arrayer kan vara av tre typer:
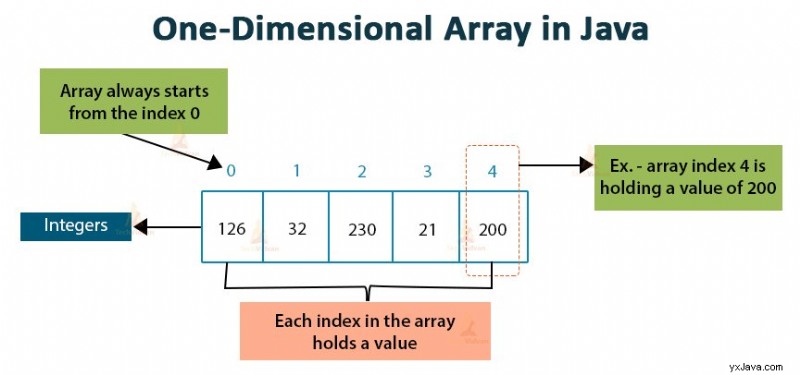
- Endimensionella matriser
- Tvådimensionella matriser
- Multidimensionella arrayer
Diagrammet nedan visar illustrationen av endimensionella arrayer.
Obs!
Vi kan bara använda en array när vi förutbestämmer antalet element tillsammans med dess storlek eftersom minnet bevaras innan bearbetning. Av denna anledning faller arrayer under kategorin statiska datastrukturer.
Tidskomplexitet för arrayoperationer:
- Åtkomst till element:O(1)
- Sökning:
För sekventiell sökning:O(n)
För binär sökning [Om matrisen är sorterad]:O(log n) - Infogning:O(n)
- Ta bort:O(n)
Dyk lite djupt in i begreppen Java Arrays för att lära dig mer i detalj.
2. Länkade listor
De länkade listorna i Java är en annan viktig typ av datastruktur. En länkad lista är en samling liknande typer av dataelement, som kallas noder , som pekar på följande noder med hjälp av pekare .
Behov av länkade listor:
Länkade listor övervinner nackdelarna med arrayer eftersom det i länkade listor inte finns något behov av att definiera antalet element innan de används, därför kan tilldelningen eller deallokeringen av minne ske under bearbetningen enligt kravet, vilket gör insättningar och borttagningar mycket enklare och enklare.
Typer av länkade listor:

Låt oss börja diskutera var och en av dessa typer i detalj:
2.1 Enkellänkad lista
En enkellänkad lista är en länkad lista som lagrar data och referensen till nästa nod eller ett nollvärde. Enkellänkade listor är också kända som envägslistor eftersom de innehåller en nod med en enda pekare som pekar på nästa nod i sekvensen.
Det finns en START-pekare som lagrar den allra första adressen till den länkade listan. Nästa pekare för den sista noden eller slutnoden lagrar NULL-värdet, vilket pekar på den sista noden i listan som inte pekar på någon annan nod.

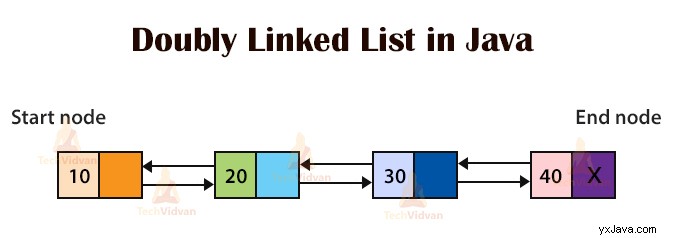
2.2 Dubbellänkad lista
Det är samma sak som en enkellänkad lista med skillnaden att den har två pekare, en som pekar på föregående nod och en som pekar på nästa nod i sekvensen. Därför tillåter en dubbellänkad lista oss att korsa i båda riktningarna för listan.
2.3 Cirkulär länkad lista
I den cirkulära länkade listan justeras alla noder för att bilda en cirkel. I denna länkade lista finns det ingen NULL-nod i slutet. Vi kan definiera vilken nod som helst som den första noden. Cirkulärt länkade listor är användbara för att implementera en cirkulär kö.
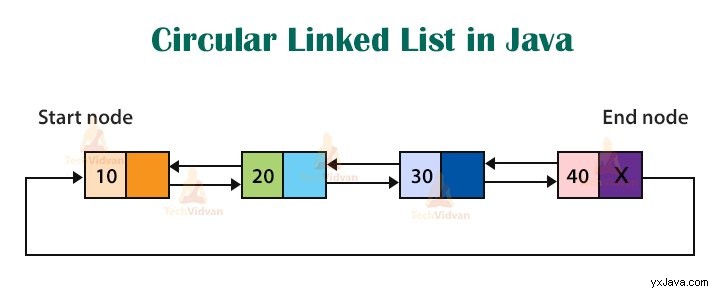
I figuren nedan kan vi se att slutnoden återigen är kopplad till startnoden.
Tidskomplexitet för operationer med länkade listor:
- Övergångselement: O(n)
- Söka efter ett element: O(n)
- Infogning: O(1)
- Ta bort: O(1)
Vi kan också utföra fler operationer som:
- Sammanfogar två listor
- Dela lista
- Återföring av lista
3. Stack
En stack är en LIFO (Last In First Out) datastruktur som fysiskt kan implementeras som en array eller som en länkad lista. Insättning och radering av element i en stack sker endast i den övre änden. En infogning i en stack kallas pushing och borttagning från en stack kallas popning.
När vi implementerar en stack som en array, ärver den alla egenskaper hos en array och om vi implementerar den som en länkad lista, förvärvar den alla egenskaper för en länkad lista.
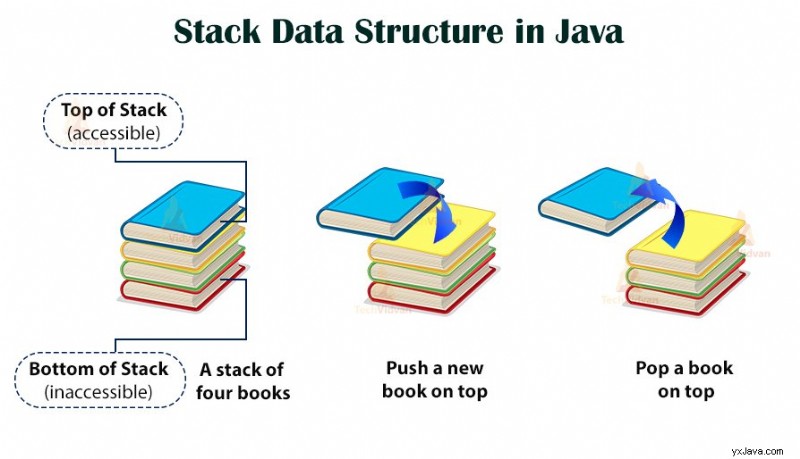
Vanliga operationer på en stack är:
- Push(): Lägger till ett objekt överst i högen.
- Pop(): Tar bort objektet från toppen av stapeln
- Peek(): Den berättar för oss vad som finns på toppen av stapeln utan att ta bort den. Ibland kan vi också kalla det top().
Stackar är användbara i:
- Parentesmatchning
- Lösa labyrintproblemet
- Kästade funktionsanrop
4. Kö
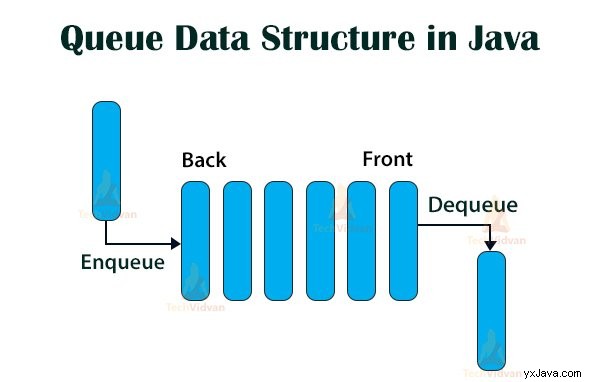
Logiskt sett är en kö en FIFO (First In First Out) datastruktur och vi kan fysiskt implementera den antingen som en array eller en länkad lista. Oavsett sätt vi använder för att implementera en kö, sker insättningar alltid på ”baksidan” slut och raderingar alltid från "fronten" slutet av kön.

Vanliga operationer i en kö är:
- Enqueue(): Lägger till element i den bakre änden av kön.
- Dequeue(): Tar bort element från den främre delen av kön.
Variationer i kö:
Beroende på programmets krav kan vi använda köerna på flera olika sätt. Två populära varianter av köer är Cirkulära köer och Deköer (dubbelköer).
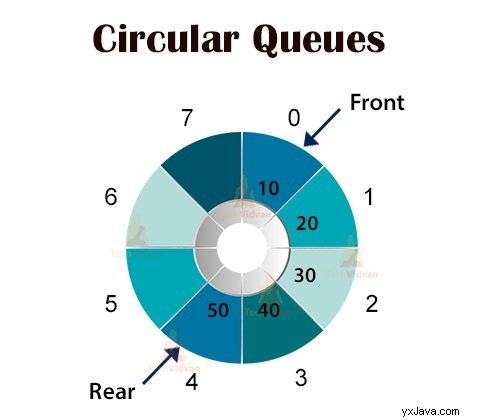
4.1 Cirkulära köer
Cirkulära köer är köerna implementerade i cirkelform snarare än ett rakt sätt. Cirkulära köer övervinner problemet med outnyttjat utrymme i de linjära köerna som vi implementerar som arrayer.
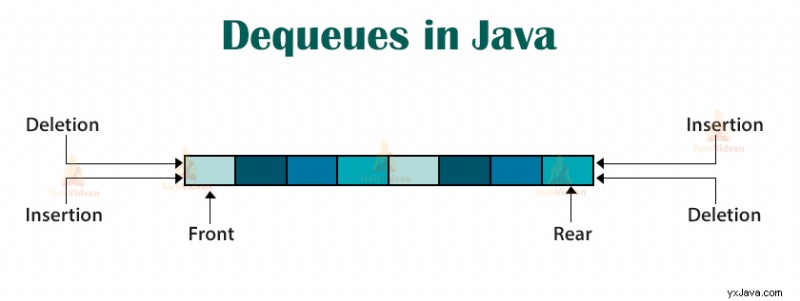
4.2 Avköer
En dubbelkö eller en avkö är en förfinad kö där man kan lägga till eller ta bort elementen i endera änden men inte i mitten.
Applikationer för en kö:
- Köer är användbara vid telefonförfrågningar, bokningsförfrågningar, trafikflöden etc. När du använder telefonkatalogtjänsten kan du ibland ha hört "Vänta, du står i KÖ".
- För att komma åt vissa resurser som skrivarköer, diskköer etc.
- För breddförst sökning i speciella datastrukturer som grafer och träd.
- För hantering av schemaläggning av processer i ett multitasking-operativsystem, t.ex. FCFS-schemaläggning (First Come First Serve), Round-Robin-schemaläggning, etc.
5. Diagram
En graf är en icke-linjär datastruktur i Java och följande två komponenter definierar den:
- En uppsättning av ett ändligt antal hörn som vi kallar somnoder .
- En kant med en ändlig uppsättning ordnade par som har formen (u, v).
- V representerar antalet hörn.
- N representerar antalet kanter.
Klassificering av en graf
Grafdatastrukturer i Java kan klassificeras utifrån två parametrar:riktning och vikt .
5.1 Riktning
På basis av riktning kan grafen klassificeras som enriktad graf och ett oriktat diagram.
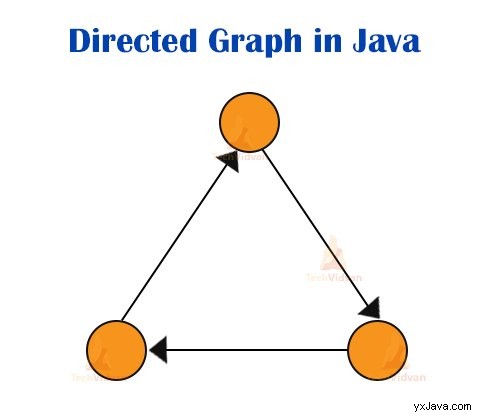
A. Riktat diagram
En riktad graf är en uppsättning noder eller hörn som ansluts med varandra och alla kanter har en riktning från en vertex till en annan. Det finns en riktad kant för varje anslutning av hörn. Bilden nedan visar en riktad graf:
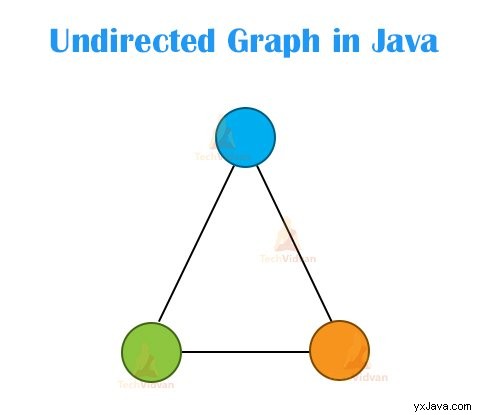
B. Oriktat diagram
En oriktad graf är en uppsättning noder eller hörn som är sammankopplade, utan riktning. Bilden nedan visar en oriktad graf:
5.2 Vikt
På basis av vikt kan grafen klassificeras som en viktad graf och en oviktad graf.
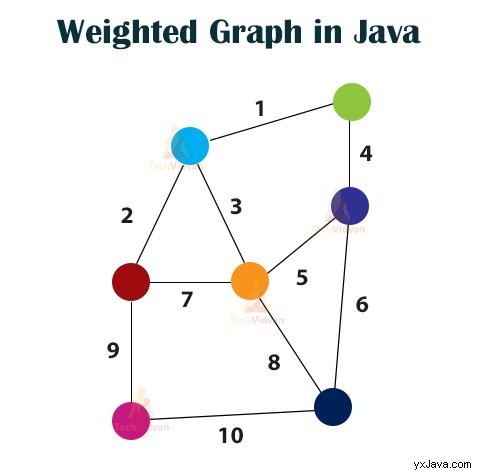
A. Viktat diagram
En viktad graf är en graf där vikten finns vid varje kant av grafen. En viktad graf är också en speciell typ av märkt graf. Figuren nedan visar en viktad graf:
B. Oviktad graf
En oviktad graf är den där det inte finns någon vikt på någon kant. Bilden nedan visar en oviktad graf:

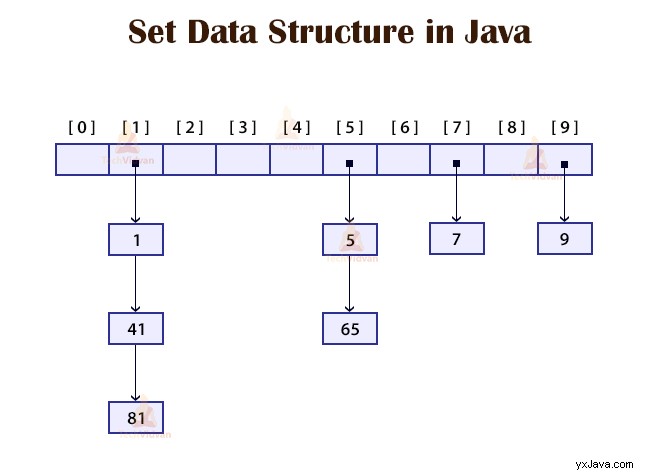
6. Ställ in
En uppsättning är en speciell datastruktur där vi inte kan använda dubblettvärdena. Det är en mycket användbar datastruktur främst när vi vill lagra unika element, till exempel unika ID:n.
Det finns många implementeringar av Set som HashSet, TreeSet och LinkedHashSet som tillhandahålls av Java Collection API.
Sammanfattning
Datastrukturer är användbara för att lagra och organisera data på ett effektivt sätt.
I artikeln ovan diskuterade vi några viktiga Java-datastrukturer som arrayer, länkade listor, stackar, köer, grafer och, Set med deras typer, implementering och exempel. Den här artikeln kommer säkert att hjälpa dig i din framtida Java-programmering.
Tack för att du läser vår artikel. Om du har några frågor relaterade till datastrukturer i Java, låt oss veta det genom att släppa en kommentar nedan.